
Planet Python
Last update: September 29, 2025 04:44 PM UTC
September 29, 2025
Real Python
Astral's ty: A New Blazing-Fast Type Checker for Python
After Ruff and uv, the Astral team is back with another Rust-based tool called ty, short for type check. This new tool delivers a lightning-fast static type-checking experience in Python, aiming to outpace existing tools in both performance and convenience. By incorporating ty into your daily workflow, you’ll catch type-related bugs earlier and get clearer feedback.
But is ty suitable for you? Take a look at the table below to make a quick decision:
| Use Case | Pick ty |
Pick Other Tools |
|---|---|---|
| Development or experimentation | ✅ | ❌ |
| Production use | ❌ | ✅ |
At the time of writing, ty is available as an early preview release with hundreds of open issues. Despite being actively developed and boasting over ten thousand stars on GitHub, it’s still missing essential features and might occasionally fail.
As such, it’s not ready for full adoption in production yet, nor is it going to be a drop-in replacement for any of its competitors. Bugs can take you by surprise in unexpected ways! Additionally, because ty’s implementation is moving fast, some of the information you’ll find in this tutorial may become outdated over time.
If you’d like to get familiar with a new, robust, and promising type checker in your personal projects, then by all means give ty a try! Ready to dive in? Click the link below to grab the sample code you’ll be working with in this tutorial:
Get Your Code: Click here to download the free sample code that you’ll use to learn about Astral’s ty.
Take the Quiz: Test your knowledge with our interactive “Astral's ty Type Checker for Python” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Astral's ty Type Checker for PythonTest your knowledge of Astral's ty—a blazing-fast, Rust-powered Python type checker. You'll cover installation, usage, rule configuration, and the tool's current limitations.
Start Using ty in Python Now
Python is a dynamically typed language, so it requires third-party tools to perform type checking and other kinds of static code analysis. Recently, ty joined the club of external type-checking tools for Python. Despite being created by a private company, Astral, the tool itself remains open source and MIT-licensed.
Although ty is mostly written in Rust, you don’t need the Rust compiler or its execution environment to type check your Python projects with it. To quickly get started with ty, you can install it directly from PyPI with pip, preferably within an activated virtual environment:
(venv) $ python -m pip install ty
As long as you’re on one of the three major operating systems—Windows, macOS, or Linux—this command will bring a hefty binary script called ty into your virtual environment. The script is already compiled to machine code suitable for your platform with all the necessary dependencies baked in, so you can run it directly, just like any other command-line program.
To verify the installation, run the following command in your terminal emulator app:
(venv) $ ty --version
ty 0.0.1-alpha.21
You should see a version number similar to the one above appear in the output. Alternatively, if that doesn’t work, then try to execute ty as a Python module using the interpreter’s -m option:
(venv) $ python -m ty --version
ty 0.0.1-alpha.21
When you do, Python runs a tiny wrapper script that looks for the ty binary executable in your path and invokes it for you.
Note that the pip install command only installs ty into the given virtual environment, which is usually associated with a specific project. To make ty available globally from any folder on your computer, you’ll need to use a different approach. Check out the official documentation for more installation options.
Note: If Visual Studio Code is your code editor of choice, then you’ll benefit from installing the official ty extension. This extension integrates ty directly into VS Code, letting you work without ever touching the command line. Unfortunately, users of PyCharm and other popular IDEs must wait until plugins for their tools catch up.
If your editor supports the Language Server Protocol, then you could leverage the ty server subcommand. For PyCharm, this requires installing the LSP4IJ plugin first, though this tutorial won’t cover its configuration.
Finally, if none of this works for you, then you may want to run the ty check subcommand with the optional --watch switch. This will have ty automatically rerun the checks for instant feedback whenever changes are detected upon saving one of the files in your project.
From now on, you won’t see the virtual environment’s name (venv) in the command prompts for the rest of this tutorial. To keep the code blocks concise, it’ll be assumed that ty is already installed globally and available in your system’s path.
Alright. It’s time for the fun part: letting ty scrutinize some Python code to catch bugs before they sneak in.
Catch Typing Errors With ty
The command-line interface of ty is pretty minimal and straightforward, as you’ll notice when you run ty without providing any subcommands or options:
$ ty
An extremely fast Python type checker.
Usage: ty <COMMAND>
Commands:
check Check a project for type errors
server Start the language server
version Display ty's version
help Print this message or the help of the given subcommand(s)
Options:
-h, --help Print help
-V, --version Print version
Read the full article at https://realpython.com/python-ty/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 29, 2025 02:00 PM UTC
Quiz: Astral's ty Type Checker for Python
In this quiz, you’ll revisit the key concepts from Astral’s ty: A New Blazing-Fast Type Checker for Python. You’ll check your understanding of installing ty from PyPI, running type checks, and interpreting its structured diagnostics. You’ll also recall how to configure and silence specific rules, limit the scope of checks, and adjust Python version or platform settings.
By completing this quiz, you’ll cement your ability to experiment confidently with ty in personal or exploratory projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 29, 2025 12:00 PM UTC
Talk Python to Me
#521: Red Teaming LLMs and GenAI with PyRIT
English is now an API. Our apps read untrusted text; they follow instructions hidden in plain sight, and sometimes they turn that text into action. If you connect a model to tools or let it read documents from the wild, you have created a brand new attack surface. In this episode, we will make that concrete. We will talk about the attacks teams are seeing in 2025, the defenses that actually work, and how to test those defenses the same way we test code. Our guides are Tori Westerhoff and Roman Lutz from Microsoft. They help lead AI red teaming and build PyRIT, a Python framework the Microsoft AI Red Team uses to pressure test real products. By the end of this hour you will know where the biggest risks live, what you can ship this quarter to reduce them, and how PyRIT can turn security from a one time audit into an everyday engineering practice.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/sentryagents'>Sentry AI Monitoring, Code TALKPYTHON</a><br> <a href='https://talkpython.fm/agntcy'>Agntcy</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading">Links from the show</h2> <div><strong>Tori Westerhoff</strong>: <a href="https://www.linkedin.com/in/victoriawesterhoff/?featured_on=talkpython" target="_blank" >linkedin.com</a><br/> <strong>Roman Lutz</strong>: <a href="https://www.linkedin.com/in/romanlutz/?featured_on=talkpython" target="_blank" >linkedin.com</a><br/> <br/> <strong>PyRIT</strong>: <a href="https://aka.ms/pyrit?featured_on=talkpython" target="_blank" >aka.ms/pyrit</a><br/> <strong>Microsoft AI Red Team page</strong>: <a href="https://learn.microsoft.com/en-us/security/ai-red-team/?featured_on=talkpython" target="_blank" >learn.microsoft.com</a><br/> <strong>2025 Top 10 Risk & Mitigations for LLMs and Gen AI Apps</strong>: <a href="https://genai.owasp.org/llm-top-10/?featured_on=talkpython" target="_blank" >genai.owasp.org</a><br/> <strong>AI Red Teaming Agent</strong>: <a href="https://learn.microsoft.com/en-us/azure/ai-foundry/concepts/ai-red-teaming-agent?featured_on=talkpython" target="_blank" >learn.microsoft.com</a><br/> <strong>3 takeaways from red teaming 100 generative AI products</strong>: <a href="https://www.microsoft.com/en-us/security/blog/2025/01/13/3-takeaways-from-red-teaming-100-generative-ai-products/?featured_on=talkpython" target="_blank" >microsoft.com</a><br/> <strong>MIT report: 95% of generative AI pilots at companies are failing</strong>: <a href="https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/?featured_on=talkpython" target="_blank" >fortune.com</a><br/> <br/> <strong>A couple of "Little Bobby AI" cartoons</strong><br/> <strong>Give me candy</strong>: <a href="https://blobs.talkpython.fm/little-bobby-ai-1.png" target="_blank" >talkpython.fm</a><br/> <strong>Tell me a joke</strong>: <a href="https://blobs.talkpython.fm/little-bobby-ai-2.png" target="_blank" >talkpython.fm</a><br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=N681L4BXTUw" target="_blank" >youtube.com</a><br/> <strong>Episode #521 deep-dive</strong>: <a href="https://talkpython.fm/episodes/show/521/red-teaming-llms-and-genai-with-pyrit#takeaways-anchor" target="_blank" >talkpython.fm/521</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/521/red-teaming-llms-and-genai-with-pyrit" target="_blank" >talkpython.fm</a><br/> <strong>Developer Rap Theme Song: Served in a Flask</strong>: <a href="https://talkpython.fm/flasksong" target="_blank" >talkpython.fm/flasksong</a><br/> <br/> <strong>--- Stay in touch with us ---</strong><br/> <strong>Subscribe to Talk Python on YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" >youtube.com</a><br/> <strong>Talk Python on Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm at bsky.app</a><br/> <strong>Talk Python on Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i>talkpython</a><br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes at bsky.app</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
September 29, 2025 08:00 AM UTC
Armin Ronacher
90%
“I think we will be there in three to six months, where AI is writing 90% of the code. And then, in 12 months, we may be in a world where AI is writing essentially all of the code”
Three months ago I said that AI changes everything. I came to that after plenty of skepticism. There are still good reasons to doubt that AI will write all code, but my current reality is close.
For the infrastructure component I started at my new company, I’m probably north of 90% AI-written code. I don’t want to convince you — just share what I learned. In parts, because I approached this project differently from my first experiments with AI-assisted coding.
The service is written in Go with few dependencies and an OpenAPI-compatible REST API. At its core, it sends and receives emails. I also generated SDKs for Python and TypeScript with a custom SDK generator. In total: about 40,000 lines, including Go, YAML, Pulumi, and some custom SDK glue.
I set a high bar, especially that I can operate it reliably. I’ve run similar systems before and knew what I wanted.
Setting it in Context
Some startups are already near 100% AI-generated. I know, because many build in the open and you can see their code. Whether that works long-term remains to be seen. I still treat every line as my responsibility, judged as if I wrote it myself. AI doesn’t change that.
There are no weird files that shouldn’t belong there, no duplicate implementations, and no emojis all over the place. The comments still follow the style I want and, crucially, often aren’t there. I pay close attention to the fundamentals of system architecture, code layout, and database interaction. I’m incredibly opinionated. As a result, there are certain things I don’t let the AI do. I know it won’t reach the point where I could sign off on a commit. That’s why it’s not 100%.
As contrast: another quick prototype we built is a mess of unclear database tgables, markdown file clutter in the repo, and boatloads of unwanted emojis. It served its purpose — validate an idea — but wasn’t built to last, and we had no expectation to that end.
Foundation Building
I began in the traditional way: system design, schema, architecture. At this state I don’t let the AI write, but I loop it in AI as a kind of rubber duck. The back-and-forth helps me see mistakes, even if I don’t need or trust the answers.
I did get the foundation wrong once. I initially argued myself into a more complex setup than I wanted. That’s a part where I later used the LLM to redo a larger part early and clean it up.
For AI-generated or AI-supported code, I now end up with a stack that looks something like something I often wanted, but was too hard to do by hand:
-
Raw SQL: This is probably the biggest change to how I used to write code. I really like using an ORM, but I don’t like some of its effects. In particular, once you approach the ORM’s limits, you’re forced to switch to handwritten SQL. That mapping is often tedious because you lose some of the powers the ORM gives you. Another consequence is that it’s very hard to find the underlying queries, which makes debugging harder. Seeing the actual SQL in your code and in the database log is powerful. You always lose that with an ORM.
The fact that I no longer have to write SQL because the AI does it for me is a game changer.
I also use raw SQL for migrations now.
-
OpenAPI first: I tried various approaches here. There are many frameworks you can use. I ended up first generating the OpenAPI specification and then using code generation from there to the interface layer. This approach works better with AI-generated code. The OpenAPI specification is now the canonical one that both clients and server shim is based on.
Iteration
Today I use Claude Code and Codex. Each has strengths, but the constant is Codex for code review after PRs. It’s very good at that. Claude is indispensable still when debugging and needing a lot of tool access (eg: why do I have a deadlock, why is there corrupted data in the database etc.). The working together of the two is where it’s most magical. Claude might find the data, Codex might understand it better.
I cannot stress enough how bad the code from these agents can be if you’re not careful. While they understand system architecture and how to build something, they can’t keep the whole picture in scope. They will recreate things that already exist. They create abstractions that are completely inappropriate for the scale of the problem.
You constantly need to learn how to bring the right information to the context. For me, this means pointing the AI to existing implementations and giving it very specific instructions on how to follow along.
I generally create PR-sized chunks that I can review. There are two paths to this:
-
Agent loop with finishing touches: Prompt until the result is close, then clean up.
-
Lockstep loop: Earlier I went edit by edit. Now I lean on the first method most of the time, keeping a todo list for cleanups before merge.
It requires intuition to know when each approach is more likely to lead to the right results. Familiarity with the agent also helps understanding when a task will not go anywhere, avoiding wasted cycles.
Where It Fails
The most important piece of working with an agent is the same as regular software engineering. You need to understand your state machines, how the system behaves at any point in time, your database.
It is easy to create systems that appear to behave correctly but have unclear runtime behavior when relying on agents. For instance, the AI doesn’t fully comprehend threading or goroutines. If you don’t keep the bad decisions at bay early it, you won’t be able to operate it in a stable manner later.
Here’s an example: I asked it to build a rate limiter. It “worked” but lacked jitter and used poor storage decisions. Easy to fix if you know rate limiters, dangerous if you don’t.
Agents also operate on conventional wisdom from the internet and in tern do things I would never do myself. It loves to use dependencies (particularly outdated ones). It loves to swallow errors and take away all tracebacks. I’d rather uphold strong invariants and let code crash loudly when they fail, than hide problems. If you don’t fight this, you end up with opaque, unobservable systems.
Where It Shines
For me, this has reached the point where I can’t imagine working any other way. Yes, I could probably have done it without AI. But I would have built a different system in parts because I would have made different trade-offs. This way of working unlocks paths I’d normally skip or defer.
Here are some of the things I enjoyed a lot on this project:
-
Research + code, instead of research and code later: Some things that would have taken me a day or two to figure out now take 10 to 15 minutes.
It allows me to directly play with one or two implementations of a problem. It moves me from abstract contemplation to hands on evaluation. -
Trying out things: I tried three different OpenAPI implementations and approaches in a day.
-
Constant refactoring: The code looks more organized than it would otherwise have been because the cost of refactoring is quite low. You need to know what you do, but if set up well, refactoring becomes easy.
-
Infrastructure: Claude got me through AWS and Pulumi. Work I generally dislike became a few days instead of weeks. It also debugged the setup issues as it was going through them. I barely had to read the docs.
-
Adopting new patterns: While they suck at writing tests, they turned out great at setting up test infrastructure I didn’t know I needed. I got a recommendation on Twitter to use testcontainers for testing against Postgres. The approach runs migrations once and then creates database clones per test. That turns out to be super useful. It would have been quite an involved project to migrate to. Claude did it in an hour for all tests.
-
SQL quality: It writes solid SQL I could never remember. I just need to review which I can. But to this day I suck at remembering
MERGEandWITHwhen writing it.
What does it mean?
Is 90% of code going to be written by AI? I don’t know. What I do know is, that for me, on this project, the answer is already yes. I’m part of that growing subset of developers who are building real systems this way.
At the same time, for me, AI doesn’t own the code. I still review every line, shape the architecture, and carry the responsibility for how it runs in production. But the sheer volume of what I now let an agent generate would have been unthinkable even six months ago.
That’s why I’m convinced this isn’t some far-off prediction. It’s already here — just unevenly distributed — and the number of developers working like this is only going to grow.
That said, none of this removes the need to actually be a good engineer. If you let the AI take over without judgment, you’ll end up with brittle systems and painful surprises (data loss, security holes, unscalable software). The tools are powerful, but they don’t absolve you of responsibility.
September 29, 2025 12:00 AM UTC
September 28, 2025
Daniel Roy Greenfeld
TIL: Loading .env files with uv run
We don't need python-dotenv, use uv run with --env-file, and your env vars from .env get loaded.
For example, if we've got a FastAPI or Air project we can run it locally with env vars like:
uv run --env-file .env fastapi dev
You can specific different env files for different environments, like .env.dev, .env.prod, etc.
uv run --env-file .env.dev fastapi dev
All credit goes to Audrey Roy Greenfeld for pointing this out to me.
September 28, 2025 10:44 PM UTC
September 26, 2025
Real Python
The Real Python Podcast – Episode #267: Managing Feature Flags & Comparing Python Visualization Libraries
What's a good way to enable or disable code paths without redeploying the software? How can you use feature flags to toggle functionality for specific users of your application? Christopher Trudeau is back on the show this week, bringing another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 26, 2025 12:00 PM UTC
Julien Tayon
Abusing yahi -a log based statistic tool à la awstats- to plot histograms/date series from CSV
pre { line-height: 125%; } td.linenos .normal { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } span.linenos { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } td.linenos .special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } span.linenos.special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } .highlight .hll { background-color: #ffffcc } .highlight { background: #eeffcc; } .highlight .c { color: #408090; font-style: italic } /* Comment */ .highlight .err { border: 1px solid #FF0000 } /* Error */ .highlight .k { color: #007020; font-weight: bold } /* Keyword */ .highlight .o { color: #666666 } /* Operator */ .highlight .ch { color: #408090; font-style: italic } /* Comment.Hashbang */ .highlight .cm { color: #408090; font-style: italic } /* Comment.Multiline */ .highlight .cp { color: #007020 } /* Comment.Preproc */ .highlight .cpf { color: #408090; font-style: italic } /* Comment.PreprocFile */ .highlight .c1 { color: #408090; font-style: italic } /* Comment.Single */ .highlight .cs { color: #408090; background-color: #fff0f0 } /* Comment.Special */ .highlight .gd { color: #A00000 } /* Generic.Deleted */ .highlight .ge { font-style: italic } /* Generic.Emph */ .highlight .ges { font-weight: bold; font-style: italic } /* Generic.EmphStrong */ .highlight .gr { color: #FF0000 } /* Generic.Error */ .highlight .gh { color: #000080; font-weight: bold } /* Generic.Heading */ .highlight .gi { color: #00A000 } /* Generic.Inserted */ .highlight .go { color: #333333 } /* Generic.Output */ .highlight .gp { color: #c65d09; font-weight: bold } /* Generic.Prompt */ .highlight .gs { font-weight: bold } /* Generic.Strong */ .highlight .gu { color: #800080; font-weight: bold } /* Generic.Subheading */ .highlight .gt { color: #0044DD } /* Generic.Traceback */ .highlight .kc { color: #007020; font-weight: bold } /* Keyword.Constant */ .highlight .kd { color: #007020; font-weight: bold } /* Keyword.Declaration */ .highlight .kn { color: #007020; font-weight: bold } /* Keyword.Namespace */ .highlight .kp { color: #007020 } /* Keyword.Pseudo */ .highlight .kr { color: #007020; font-weight: bold } /* Keyword.Reserved */ .highlight .kt { color: #902000 } /* Keyword.Type */ .highlight .m { color: #208050 } /* Literal.Number */ .highlight .s { color: #4070a0 } /* Literal.String */ .highlight .na { color: #4070a0 } /* Name.Attribute */ .highlight .nb { color: #007020 } /* Name.Builtin */ .highlight .nc { color: #0e84b5; font-weight: bold } /* Name.Class */ .highlight .no { color: #60add5 } /* Name.Constant */ .highlight .nd { color: #555555; font-weight: bold } /* Name.Decorator */ .highlight .ni { color: #d55537; font-weight: bold } /* Name.Entity */ .highlight .ne { color: #007020 } /* Name.Exception */ .highlight .nf { color: #06287e } /* Name.Function */ .highlight .nl { color: #002070; font-weight: bold } /* Name.Label */ .highlight .nn { color: #0e84b5; font-weight: bold } /* Name.Namespace */ .highlight .nt { color: #062873; font-weight: bold } /* Name.Tag */ .highlight .nv { color: #bb60d5 } /* Name.Variable */ .highlight .ow { color: #007020; font-weight: bold } /* Operator.Word */ .highlight .w { color: #bbbbbb } /* Text.Whitespace */ .highlight .mb { color: #208050 } /* Literal.Number.Bin */ .highlight .mf { color: #208050 } /* Literal.Number.Float */ .highlight .mh { color: #208050 } /* Literal.Number.Hex */ .highlight .mi { color: #208050 } /* Literal.Number.Integer */ .highlight .mo { color: #208050 } /* Literal.Number.Oct */ .highlight .sa { color: #4070a0 } /* Literal.String.Affix */ .highlight .sb { color: #4070a0 } /* Literal.String.Backtick */ .highlight .sc { color: #4070a0 } /* Literal.String.Char */ .highlight .dl { color: #4070a0 } /* Literal.String.Delimiter */ .highlight .sd { color: #4070a0; font-style: italic } /* Literal.String.Doc */ .highlight .s2 { color: #4070a0 } /* Literal.String.Double */ .highlight .se { color: #4070a0; font-weight: bold } /* Literal.String.Escape */ .highlight .sh { color: #4070a0 } /* Literal.String.Heredoc */ .highlight .si { color: #70a0d0; font-style: italic } /* Literal.String.Interpol */ .highlight .sx { color: #c65d09 } /* Literal.String.Other */ .highlight .sr { color: #235388 } /* Literal.String.Regex */ .highlight .s1 { color: #4070a0 } /* Literal.String.Single */ .highlight .ss { color: #517918 } /* Literal.String.Symbol */ .highlight .bp { color: #007020 } /* Name.Builtin.Pseudo */ .highlight .fm { color: #06287e } /* Name.Function.Magic */ .highlight .vc { color: #bb60d5 } /* Name.Variable.Class */ .highlight .vg { color: #bb60d5 } /* Name.Variable.Global */ .highlight .vi { color: #bb60d5 } /* Name.Variable.Instance */ .highlight .vm { color: #bb60d5 } /* Name.Variable.Magic */ .highlight .il { color: #208050 } /* Literal.Number.Integer.Long */ div.admonition, div.topic, blockquote { clear: left; } div.admonition { margin: 20px 0px; padding: 10px 30px; background-color: #EEE; border: 1px solid #CCC; } div.admonition tt.xref, div.admonition code.xref, div.admonition a tt { background-color: #FBFBFB; border-bottom: 1px solid #fafafa; } div.admonition p.admonition-title { font-family: Georgia, serif; font-weight: normal; font-size: 24px; margin: 0 0 10px 0; padding: 0; line-height: 1; } div.admonition p.last { margin-bottom: 0; } /* -- topics ---------------------------------------------------------------- */ nav.contents, aside.topic, div.topic { border: 1px solid #ccc; padding: 7px; margin: 10px 0 10px 0; } p.topic-title { font-size: 1.1em; font-weight: bold; margin-top: 10px; } /* -- admonitions ----------------------------------------------------------- */ div.admonition { margin-top: 10px; margin-bottom: 10px; padding: 7px; } div.admonition dt { font-weight: bold; } p.admonition-title { margin: 0px 10px 5px 0px; font-weight: bold; } div.body p.centered { text-align: center; margin-top: 25px; }
Foreword what is yahi?
Yahi is a python module that can installed with pip to make a all in one static html page aggregating the data from a web server. Actually, as shown with the parsing of auth.log in the documentation, it is pretty much a versatile log analyser based on regexp enabling various aggregation : by geo_ip, by histograms, chronological series.
The demo is here. It pretty much is close to awstats which is discontinued or goaccess.
As the author of yahi I may not be very objective, but I claim it is having a quality other tools don't have : it is easy to abuse for format other than web logs and here is an example out of the norm : parsing CSV.
Ploting histograms or time series from CSV
CSV that can be parsed as regexp
There are simple cases when CSV don’t have strings embedded and are litteraly comma separated integers/floats.
In this case, CSV can be parsed as a regexp and it’s all the more convenient when the CSV has no title.
Here is an example using the CSV coming from the CSV generated by trollometre
A line is made off a timestamp followed by various (int) counters.
Tip
For the sake of ease of use I hacked the date_pattern format to accept “%s” as a timestamp (while it’s normally only valid strptime formater)
from archery import mdict
from yahi import notch, shoot
from json import dump
import re
context=notch(
off="user_agent,geo_ip",
log_format="custom",
output_format="json",
date_pattern="%s",
log_pattern="""^(?P<datetime>[^,]+),
(?P<nb_fr>[^,]+),
(?P<nb_total>[^,]+),?.*
$""")
date_formater= lambda dt :"%s-%s-%s" % ( dt.year, dt.month, dt.day)
res= shoot(
context,
lambda data: mdict({
"date_fr" :
mdict({ date_formater(data["_datetime"]) :
int(data["nb_fr"]) }),
"hour_fr" :
mdict({ "%02d" % data["_datetime"].hour :
int(data["nb_fr"]) }),
"date_all" :
mdict({ date_formater(data["_datetime"]) :
int(data["nb_total"]) }),
"hour_all" :
mdict({ "%02d" % data["_datetime"].hour :
int(data["nb_total"]) }),
"total" : 1
})
)
dump(res,open("data.js","w"), indent=4)
Then, all that remains to do is
python test.py < ~/trollometre.csv && yahi_all_in_one_maker && firefox aio.html
You click on time series and can see the either the chronological time serie

Or the profile by hour

Raw approach with csv.DictReader
Let’s take the use case where my job insurance sent me the data of all the 10000 jobless persons in my vicinity consisting for each line of :
opaque id,civility,firstname, lastname, email,email of the counseler following the job less person
For this CSV, I have the title as the first line, and have strings that may countain “,”, hence the regexp approach is strongly ill advised.
What we want here is 2 histograms :
- the frequency of the firstname (that does not violates RGPD) and that I can share,
- how much each adviser is counseling.
Here is the code
from csv import DictReader
from json import dump
from archery import mdict
res=mdict()
with open("/home/jul/Téléchargements/GEMESCAPEG.csv") as f:
for l in DictReader(f):
res+=mdict(by_ref = mdict({l["Referent"]: 1}), by_prenom=mdict({l["Prenom"]:1}))
dump(res, open("data.js", "w"), indent=4)
Then, all that remains to do is
yahi_all_in_one_maker && firefox aio.html
And here we can see that each counseler is following on average ~250 jobless persons.

And the frequency of the firstname

Which correlated with the demographic of the firstname as included here below tends to prove that the older you are the less likeky you are to be jobless.
I am not saying ageism, the data are doing it for me.



September 26, 2025 09:59 AM UTC
Python Engineering at Microsoft
Simplifying Resource Management in mssql-python through Context Manager

Reviewed by: Sumit Sarabhai and Gaurav Sharma
If you’ve worked with databases in Python, you know the boilerplate: open a connection, create a cursor, run queries, commit or rollback transactions, close cursors and connection. Forgetting just one cleanup step can lead to resource leaks (open connections) or even inconsistent data. That’s where context managers step in.
We’ve introduced context manager support in mssql‑python driver, enabling Python applications to interact with SQL Server and Azure SQL more safely, cleanly, and in a truly Pythonic way.
Try it here
You can install driver using pip install mssql-pythonCalling all Python + SQL developers! We invite the community to try out mssql-python and help us shape the future of high-performance SQL Server connectivity in Python.!
Why Context Managers?
In Python, the with statement is syntactic sugar for resource management. It actively sets up resources when you enter a block and automatically cleans them up when you exit — even if an exception is raised.
Think of it as hiring a helper:
- They prepare the workspace before you begin.
- They pack everything up when you’re done.
- If something breaks midway, they handle the cleanup for you.
The Problem: Managing Connections and Cursors
Earlier, working with Python applications and SQL server/Azure SQL looked something like this:
from mssql_python import connect
conn = connect(connection_string)
cursor = conn.cursor()
try:
cursor.execute("SELECT * FROM users")
for row in cursor:
print(row)
finally:
cursor.close()
conn.close()
This works perfectly fine. But imagine if your code had multiple cursors, multiple queries, and exception handling sprinkled all over. Closing every connection and cursor manually becomes tedious and error-prone. Miss a close() somewhere, and you have a resource leak.
That’s where Python’s with statement — the context manager — comes to the rescue. mssql_python not only supports it for connections but also for cursors, which makes resource management nearly effortless.
Using Context Managers with Connections
Now comes the real magic — connection-level context managers. When you wrap a connection in a with block, several things happen under the hood:
- If everything succeeds, the transaction is committed.
- If an exception occurs, the transaction is rolled back.
- The connection is always closed when leaving the block.
Example:
from mssql_python import connect
with connect(connection_string) as conn:
cursor = conn.cursor()
cursor.execute("INSERT INTO users (name) VALUES ('Alice')")
# If no exception → commit happens automatically
# If exception → rollback happens automatically
# Connection is closed automatically hereEquivalent traditional approach:
conn = connect(connection_string)
try:
cursor = conn.cursor()
cursor.execute("INSERT INTO users (name) VALUES ('Alice')")
if not conn.autocommit:
conn.commit()
except:
if not conn.autocommit:
conn.rollback()
raise
finally:
conn.close()
How It Works Internally
- Entering the block
- Connection is opened and assigned to conn.
- All operations inside the block run using this connection.
- Exiting the block
- No exception: If
autocommit=False, transactions are committed. - Exception raised: If
autocommit=False, uncommitted changes are rolled back. The exception propagates unless handled.
- No exception: If
- Cleanup: Connection is always closed, preventing resource leaks.
Use case: Perfect for transactional code — inserts, updates, deletes — where you want automatic commit/rollback.
Using Context Managers with Cursors
Cursors in mssql_python now support the with statement. The context here is tied to the cursor resource, not the transaction.
with conn.cursor() as cursor:
cursor.execute("SELECT * FROM users")
for row in cursor:
print(row)
# Cursor is automatically closed hereWhat happens here?
- Entering the block: A new cursor is created.
- Inside the block: All SQL statements execute using this cursor.
- Exiting the block: The cursor is automatically closed — no need to call
cursor.close()manually. - Transactions: The cursor itself doesn’t manage transactions. Commit/rollback is controlled by the connection.
- If
autocommit=False, changes are committed or rolled back at the connection level. - If
autocommit=True, each statement is committed immediately as it executes.
- If
Above code is equivalent to the traditional try-finally approach:
cursor = conn.cursor()
try:
cursor.execute("SELECT * FROM users")
for row in cursor:
print(row)
finally:
cursor.close()Use case: Best for read-only queries where you don’t want to worry about cursor leaks.
Important
If you just want to ensure the cursor closes properly without worrying about transactions, this is the simplest and safest approach.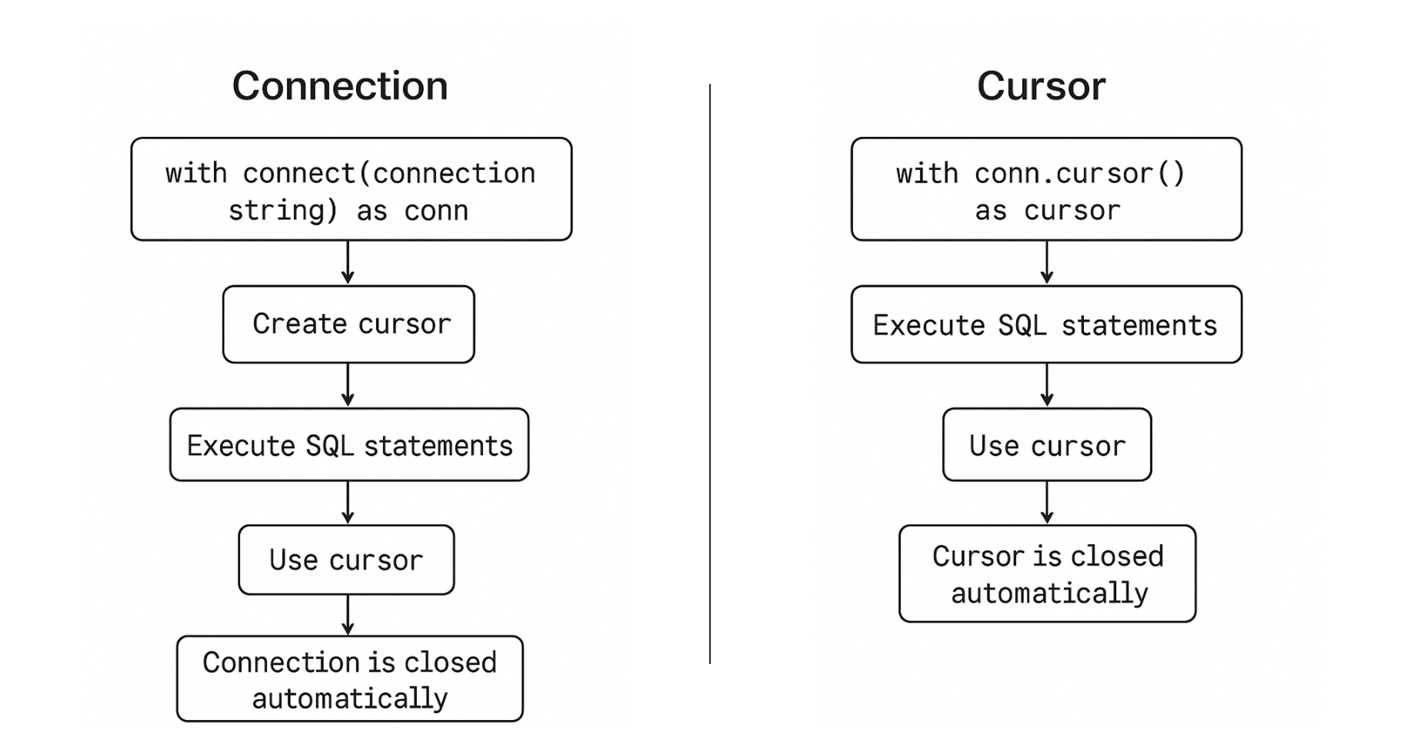
Image 1: Workflow of Context Manager in Connections and Cursor
Practical Examples
Example 1: Safe SELECT Queries
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("SELECT * FROM users WHERE age > 25")
for row in cursor:
print(row)
# Cursor closed, connection still open until block ends
# Connection is closed Example 2: Multiple Operations in One Transaction
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("INSERT INTO users (name) VALUES ('Bob')")
cursor.execute("UPDATE users SET age = age + 1 WHERE name = 'Alice'")
# Everything committed automatically if no exceptionExample 3: Handling Exceptions Automatically
try:
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("INSERT INTO users (name) VALUES ('Charlie')")
# Simulate error
raise ValueError("Oops, something went wrong")
except ValueError as e:
print("Transaction rolled back due to:", e)
# Connection closed automatically, rollback executed
Real-Life Scenarios
Example 1: Web Applications
In a web app where each request inserts or fetches data:
def add_user(name):
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("INSERT INTO users (name) VALUES (?)", (name,))- Guarantees commit/rollback automatically.
- No open connections piling up.
- Clean, readable, and safe code for high-traffic scenarios.
Example 2: Data Migration / ETL
Migrating data between tables:
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("INSERT INTO archive_users SELECT * FROM users WHERE inactive=1")
cursor.execute("DELETE FROM users WHERE inactive=1")- If any statement fails, rollback happens automatically.
- Prevents partial migration, keeping data consistent.
Example 3: Automated Reporting
Running multiple queries for analytics:
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("SELECT COUNT(*) FROM users")
user_count = cursor.fetchone()[0]
cursor.execute("SELECT department, COUNT(*) FROM employees GROUP BY department")
for row in cursor:
print(row)- Cursors closed automatically after each block.
- Makes scripts modular and maintainable.
Example 4: Financial Transactions
Simple bank transfer example:
def transfer_funds(from_account, to_account, amount):
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("UPDATE accounts SET balance = balance - ? WHERE id=?", (amount, from_account))
cursor.execute("UPDATE accounts SET balance = balance + ? WHERE id=?", (amount, to_account))- Automatic rollback on failure ensures money isn’t lost or double-counted.
- Eliminates verbose error-handling boilerplate.
Example 5: Ad-Hoc Data Exploration
When exploring data in scripts or notebooks:
with connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute("SELECT AVG(salary) FROM employees")
print("Average salary:", cursor.fetchone()[0])- Perfect for quick queries.
- No forgotten
close()calls. - Encourages clean, reusable query blocks.
Takeaway
Python’s philosophy is “simple is better than complex.” With context managers in mssql_python, we’ve brought that simplicity to SQL Server interactions with python apps making lives of the developers easier.
Next time you’re working with mssql_python, try wrapping your connections and cursors with with. You’ll write less code, make fewer mistakes, and your future self will thank you. Whether it’s a high-traffic web application, an ETL script, or exploratory analysis, context managers simplify life, make code safer, and reduce errors.
Remember, context manager will help you with:
- Less boilerplate code: No longer try-finally for cursors or connections.
- Automatic transaction management: Commit or rollback is handled based on success or failure.
- Safe resource cleanup: Prevents resource leaks with automatic closing.
- Readable and Pythonic: Nested with blocks clearly show the scope of cursor and connection usage.
Try It and Share Your Feedback!
We invite you to:
- Check-out the mssql-python driver and integrate it into your projects.
- Share your thoughts: Open issues, suggest features, and contribute to the project.
- Join the conversation: GitHub Discussions | SQL Server Tech Community.
Use Python Driver with Free Azure SQL Database
You can use the Python Driver with the free version of Azure SQL Database! Deploy Azure SQL Database for free
Deploy Azure SQL Database for free
Deploy Azure SQL Managed Instance for free Perfect for testing, development, or learning scenarios without incurring costs.
The post Simplifying Resource Management in mssql-python through Context Manager appeared first on Microsoft for Python Developers Blog.
September 26, 2025 09:49 AM UTC
Wingware
Wing Python IDE Version 11.0.5 - September 26, 2025
Wing Python IDE version 11.0.5 has been released. It fixes remote development with older Python versions, improves Python code analysis when using Python 3.14 and for type hints on instance attributes, and fixes Find Uses and Refactoring to find all overrides of a method.
Downloads
Wing 10 and earlier versions are not affected by installation of Wing 11 and may be installed and used independently. However, project files for Wing 10 and earlier are converted when opened by Wing 11 and should be saved under a new name, since Wing 11 projects cannot be opened by older versions of Wing.
 New in Wing 11
New in Wing 11
Improved AI Assisted Development
Wing 11 improves the user interface for AI assisted development by introducing two separate tools AI Coder and AI Chat. AI Coder can be used to write, redesign, or extend code in the current editor. AI Chat can be used to ask about code or iterate in creating a design or new code without directly modifying the code in an editor.
Wing 11's AI assisted development features now support not just OpenAI but also Claude, Grok, Gemini, Perplexity, Mistral, Deepseek, and any other OpenAI completions API compatible AI provider.
This release also improves setting up AI request context, so that both automatically and manually selected and described context items may be paired with an AI request. AI request contexts can now be stored, optionally so they are shared by all projects, and may be used independently with different AI features.
AI requests can now also be stored in the current project or shared with all projects, and Wing comes preconfigured with a set of commonly used requests. In addition to changing code in the current editor, stored requests may create a new untitled file or run instead in AI Chat. Wing 11 also introduces options for changing code within an editor, including replacing code, commenting out code, or starting a diff/merge session to either accept or reject changes.
Wing 11 also supports using AI to generate commit messages based on the changes being committed to a revision control system.
You can now also configure multiple AI providers for easier access to different models.
For details see AI Assisted Development under Wing Manual in Wing 11's Help menu.
Package Management with uv
Wing Pro 11 adds support for the uv package manager in the New Project dialog and the Packages tool.
For details see Project Manager > Creating Projects > Creating Python Environments and Package Manager > Package Management with uv under Wing Manual in Wing 11's Help menu.
Improved Python Code Analysis
Wing 11 makes substantial improvements to Python code analysis, with better support for literals such as dicts and sets, parametrized type aliases, typing.Self, type of variables on the def or class line that declares them, generic classes with [...], __all__ in *.pyi files, subscripts in typing.Type and similar, type aliases, type hints in strings, type[...] and tuple[...], @functools.cached_property, base classes found also in .pyi files, and typing.Literal[...].
Updated Localizations
Wing 11 updates the German, French, and Russian localizations, and introduces a new experimental AI-generated Spanish localization. The Spanish localization and the new AI-generated strings in the French and Russian localizations may be accessed with the new User Interface > Include AI Translated Strings preference.
Improved diff/merge
Wing Pro 11 adds floating buttons directly between the editors to make navigating differences and merging easier, allows undoing previously merged changes, and does a better job managing scratch buffers, scroll locking, and sizing of merged ranges.
For details see Difference and Merge under Wing Manual in Wing 11's Help menu.
Other Minor Features and Improvements
Wing 11 also adds support for Python 3.14, improves the custom key binding assignment user interface, adds a Files > Auto-Save Files When Wing Loses Focus preference, warns immediately when opening a project with an invalid Python Executable configuration, allows clearing recent menus, expands the set of available special environment variables for project configuration, and makes a number of other bug fixes and usability improvements.
Changes and Incompatibilities
Since Wing 11 replaced the AI tool with AI Coder and AI Chat, and AI configuration is completely different than in Wing 10, you will need to reconfigure your AI integration manually in Wing 11. This is done with Manage AI Providers in the AI menu. After adding the first provider configuration, Wing will set that provider as the default. You can switch between providers with Switch to Provider in the AI menu.
If you have questions, please don't hesitate to contact us at support@wingware.com.
September 26, 2025 01:00 AM UTC
Seth Michael Larson
GZipped files and streams may contain names
It's just another day, you're sending a bunch of files to a friend. For no particular reason you decide to name the archive with your controversial movie opinions:
$ tar -cf i-did-not-care-for-the-godfather.tar *.txt
$ gzip i-did-not-care-for-the-godfather.tar
Realizing you'd be sharing this file with others, you decide to rename the file.
$ mv i-did-not-care-for-the-godfather.tar.gz \
i-love-the-godfather.tar.gz
That's better! Now your secret is safe. You share the tarball with your colleague who notes your "good taste" in movies and proceeds to extract the archive.
$ gunzip --name i-love-the-godfather.tar.gz
i-love-the-godfather.tar.gz: 100.0% --
replaced with i-did-not-care-for-the-godfather.tar
Uh oh, your secret is out! The decompressed .tar file was named i-did-not-care-for-the-godfather.tar
instead of i-love-the-godfather.tar like we intended. How could this happen?
It turns out that GZip streams have fields for information about the original file
including the filename, modified timestamp, and comments.
This means GZip streams can leak secret information if it's contained within the file metadata.
Luckily tar when using $ tar -czf (which is the typical workflow) instead of the gzip and gunzip commands
doesn't preserve the original filename in the GZip stream.
If you do have to use gzip, use the --no-name option to strip this information
from the GZip stream. Use a hex editor to check a GZip compressed file if you are unsure.
Thanks for keeping RSS alive! ♥
September 26, 2025 12:00 AM UTC
September 25, 2025
PyPodcats
Episode 10: With Una Galyeva
Learn about Una's journey. Una is a driving force behind PyLadies Amsterdam, a Microsoft MVP, AI4ALL Advisory board member, and Head of Artificial Intelligence.Learn about Una's journey. Una is a driving force behind PyLadies Amsterdam, a Microsoft MVP, AI4ALL Advisory board member, and Head of Artificial Intelligence.
We interviewed Una Galyeva.
With over 19 years of experience in Data and AI, Una Galyeva held various positions, from hands-on Data and AI development to leading Data and AI teams and departments. She is a driving force behind PyLadies Amsterdam, a Microsoft MVP, AI4ALL Advisory board member, and Head of Artificial Intelligence.
In this episode, Una shares her journey of relocating to Amsterdam, navigating the tech industry, and building inclusive communities. From freelancing challenges to leading innovative workshops, Una offers valuable insights on career growth, and fostering diversity in tech.
Be sure to listen to the episode to learn all about Una’s inspiring story!
Topic discussed
- Introductions
- Getting to know Una
- Una’s journey and relocation in Amsterdam
- Her transition from Exectutive Director to freelancer
- Insights to freelancing
- PyLadies Amsterdam
- Excitement of freelancing and working on diverse topics
- Her community philosophy, especially for PyLadies Amsterdam
- Job search and recruitment
Links from the show
- PyLadies Amsterdam: http://amsterdam.pyladies.com/
September 25, 2025 09:00 AM UTC
September 24, 2025
Antonio Cuni
Tracing JITs in the real world @ CPython Core Dev Sprint
Tracing JITs in the real world @ CPython Core Dev Sprint
.slide { border: 2px solid #ddd; border-radius: 8px; margin: 2em 0; background: #f9f9f9; max-width: 100%; width: 100%; box-sizing: border-box; padding: 2em; background: white; border-radius: 6px 6px 0 0; border-bottom: 2px solid #eee; display: block; min-height: 400px; height: auto; overflow-y: auto; overflow-x: hidden;}.slide h1, .slide h2, .slide h3 { margin-top: 0; color: #333;}Last week I got to take part in the CPython Core Developer Sprint inCambridge, hosted by ARM and brilliantlyorganized by Diego Russo-- about ~50 core devs and guests were there, and I was excited to join as oneof the guests.

I had three main areas of focus:
C API: this was a follow up of what we discussed at the C API summit at EuroPython. The current C API is problematic, so we are exploring ideas for the development of PyNI (Python Native Interface), whose design will likely be heavily inspired by HPy. It's important to underline that this is just the beginning and the entire process will require multiple PEPs.
fancycompleter This is a small PR which I started months ago, to enable colorful tab completions within the Python REPL. I wrote the original version of fancycompleter 15 years ago, but colorful completions work only in combination with PyREPL. Now PyREPL is part of the standard library and enabled by default, so we can finally upstream it. I hope to see it merged soon.
"JIT stuff": I spent a considerable amount of time talking to the people who are working on the CPython JIT (in particular Mark, Brandt, Savannah, Ken Jin and Diego). Knowledge transfer worked in both ways: I learned a lot about the internal details of CPython's JIT, and conversely I shared with them some of the experience, pain points and gut feelings which I got by working many years on PyPy.
In particular, on the first day I presented a talk titled Tracing JIT and real world Python (slides and source code).
What follows is an annotated version of the slides.
September 24, 2025 09:37 PM UTC
Slides for my EuroPython 2025 talks
EuroPython 2025 slides
Here are the slides for the three speeches which I gave atEuroPython 2025:
September 24, 2025 09:37 PM UTC
SPy @ PyCon IT 2025
SPy @ PyCon IT 2025
Yesterday I talked about SPy at PyCon Italy.

Thanks to Hugo van Kemenade for the picture.
Slides are available here.
The edited video is not available yet, but in the meantime it's possible towatch unedited version available inside thelive streamat minute 05:44:05.
September 24, 2025 08:55 PM UTC
Real Python
Python MCP: Connect Your LLM With the World
The Model Context Protocol (MCP) is a new open protocol that allows AI models to interact with external systems in a standardized, extensible way. In this tutorial, you’ll install MCP, explore its client-server architecture, and work with its core concepts: prompts, resources, and tools. You’ll then build and test a Python MCP server that queries e-commerce data and integrate it with an AI agent in Cursor to see real tool calls in action.
By the end of this tutorial, you’ll understand:
- What MCP is and why it was created
- What MCP prompts, resources, and tools are
- How to build an MCP server with customized tools
- How to integrate your MCP server with AI agents like Cursor
You’ll get hands-on experience with Python MCP by creating and testing MCP servers and connecting your MCP to AI tools. To keep the focus on learning MCP rather than building a complex project, you’ll build a simple MCP server that interacts with a simulated e-commerce database. You’ll also use Cursor’s MCP client, which saves you from having to implement your own.
Note: If you’re curious about further discussions on MCP, then listen to the Real Python Podcast Episode 266: Dangers of Automatically Converting a REST API to MCP.
You’ll get the most out of this tutorial if you’re comfortable with intermediate Python concepts such as functions, object-oriented programming, and asynchronous programming. It will also be helpful if you’re familiar with AI tools like ChatGPT, Claude, LangChain, and Cursor.
Get Your Code: Click here to download the free sample code that shows you how to use Python MCP to connect your LLM With the World.
Take the Quiz: Test your knowledge with our interactive “Python MCP: Connect Your LLM With the World” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python MCP: Connect Your LLM With the WorldTest your knowledge of Python MCP. Practice installation, tools, resources, transports, and how LLMs interact with servers.
Installing Python MCP
Python MCP is available on PyPI, and you can install it with pip. Open a terminal or command prompt, create a new virtual environment, and then run the following command:
(venv) $ python -m pip install "mcp[cli]"
This command will install the latest version of MCP from PyPI onto your machine. To verify that the installation was successful, start a Python REPL and import MCP:
>>> import mcp
If the import runs without error, then you’ve successfully installed MCP. You’ll also need pytest-asyncio for this tutorial:
(venv) $ python -m pip install pytest-asyncio
It’s a pytest plugin that adds asyncio support, which you’ll use to test your MCP server. With that, you’ve installed all the Python dependencies you need, and you’re ready to dive into MCP! You’ll start with a brief introduction to MCP and its core concepts.
What Is MCP?
Before diving into the code for this tutorial, you’ll learn what MCP is and the problem it tries to solve. You’ll then explore MCP’s core primitives—prompts, resources, and tools.
Understanding MCP
The Model Context Protocol is a protocol for AI language models, often referred to as large language models (LLMs), that standardizes how they interact with the outside world. This interaction most often involves performing actions like sending emails, writing and executing code, making API requests, browsing the web, and much more.
You might be wondering how LLMs are capable of this. How can an LLM that accepts text as input and returns text as output possibly perform actions? The key to this capability lies in function calling—a process through which LLMs execute predefined functions in a programming language like Python. At a high level, here’s what an LLM function-calling workflow might look like:
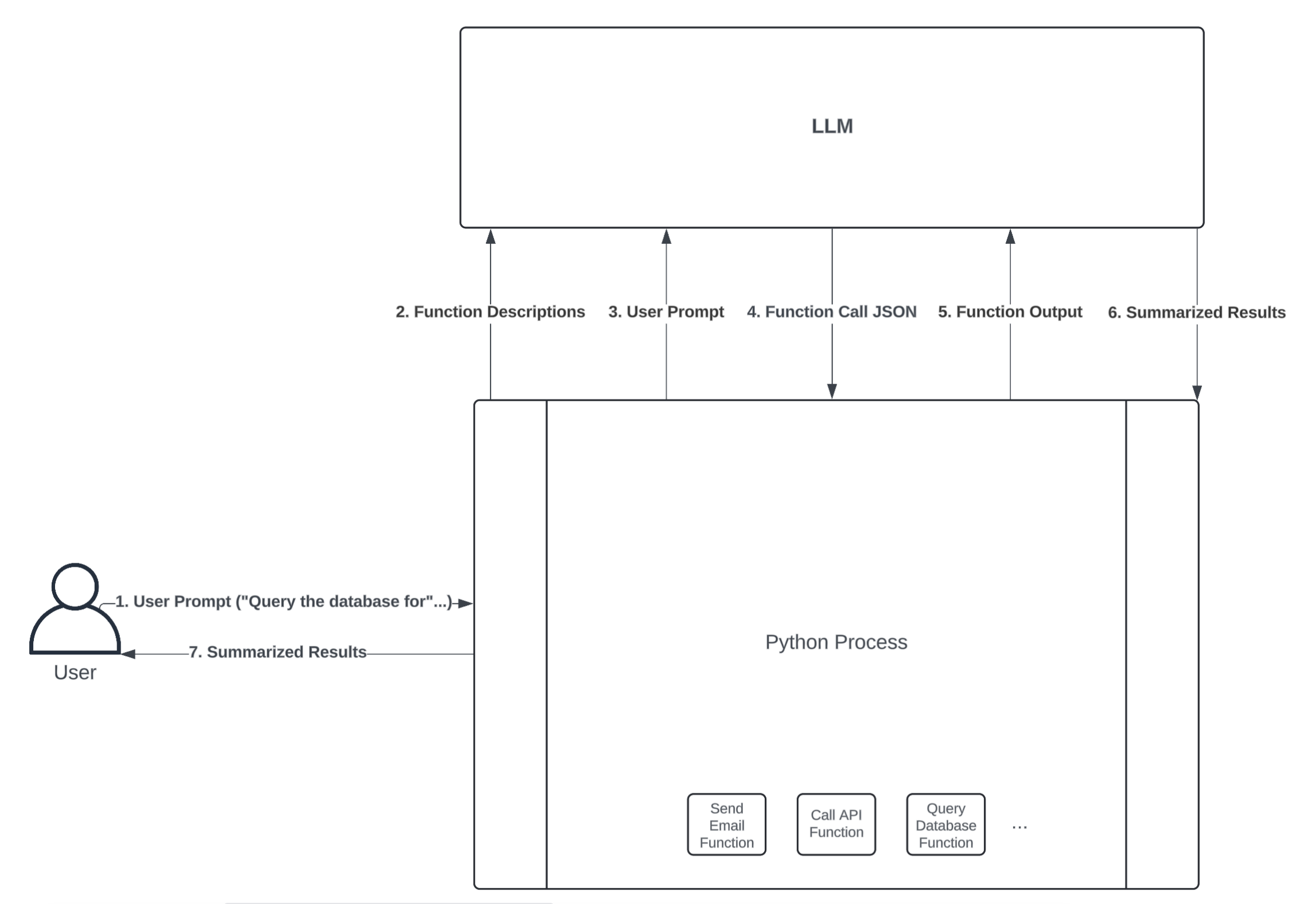 LLM Function Calling Workflow
LLM Function Calling Workflow
The diagram above illustrates how an LLM and Python process could interact to perform an action through function calling. Here’s a breakdown of each step:
-
User Prompt: The user first sends a prompt to the Python process. For example, the user might ask a question that requires a database query to answer, such as “How many customers have ordered our product today?”
-
Function Descriptions: The Python process can expose several functions to the LLM, allowing it to decide which one to call. You do this by type hinting your functions’ input arguments and writing thorough docstrings that describe what your functions do. An LLM framework like LangChain will convert your function definition into a text description and send it to an LLM along with the user prompt.
-
User Prompt: In combination with the function descriptions, the LLM also needs the user prompt to guide which function(s) it should call.
-
Function Call JSON: Once the LLM receives the user prompt and a description of each function available in your Python process, it can decide which function to call by sending back a JSON string. The JSON string must include the name of the function that the LLM wants to execute, as well as the inputs to pass to that function. If the JSON string is valid, then your Python process can convert it into a dictionary and call the respective function.
-
Function Output: If your Python process successfully executes the function call specified in the JSON string, it then sends the function’s output back to the LLM for further processing. This is useful because it allows the LLM to interpret and summarize the function’s output in a human-readable format.
-
Summarized Results: The LLM returns summarized results back to the Python process. For example, if the user prompt is “How many customers have ordered our product today?”, the summarized result might be “10 customers have placed orders today.” Despite all of the work happening between the Python process and the LLM to query the database in this example, the user experience is seamless.
-
Summarized Results: Lastly, the Python process gives the LLM’s summarized results to the user.
The power of MCP lies in its standardized architecture built around clients and servers. An MCP server is an API that hosts the prompts, resources, and tools you want to make available to an LLM. You’ll learn about prompts, resources, and tools shortly.
Read the full article at https://realpython.com/python-mcp/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 24, 2025 02:00 PM UTC
PyCharm
Why Is Python So Popular in 2025?
September 24, 2025 11:19 AM UTC
Why Is Python So Popular in 2025?

While other programming languages come and go, Python has stood the test of time and firmly established itself as a top choice for developers of all levels, from beginners to seasoned professionals.
Whether you’re working on intelligent systems or data-driven workflows, Python has a pivotal role to play in how your software is built, scaled, and optimized.
Many surveys, including our upcoming Developer Ecosystem Survey 2025, confirm Python’s continued popularity. The real question is why developers keep choosing it, and that’s what we’ll explore.
Whether you’re choosing your first language or building production-scale services, this post will walk you through why Python remains a top choice for developers.
How popular is Python in 2025?
In our Developer Ecosystem Survey 2025, Python ranks as the second most-used programming language in the last 12 months, with 57% of developers reporting that they use it.
More than a third (34%) said Python is their primary programming language. This places it ahead of JavaScript, Java, and TypeScript in terms of primary use. It’s also performing well despite fierce competition from newer systems and niche domain tools.
These stats tell a story of sustained relevance across diverse developer segments, from seasoned backend engineers to first-time data analysts.
This continued success is down to Python’s ability to grow with you. It doesn’t just serve as a first step; it continues adding value in advanced environments as you gain skills and experience throughout your career.
Let’s explore why Python remains a popular choice in 2025.
1. Dominance in AI and machine learning
Our recently released report, The State of Python 2025, shows that 41% of Python developers use the language specifically for machine learning.
This is because Python drives innovation in areas like natural language processing, computer vision, and recommendation systems.
Python’s strength in this area comes from the fact that it offers support at every stage of the process, from prototyping to production. It also integrates into machine learning operations (MLOps) pipelines with minimal friction and high flexibility.
One of the most significant reasons for Python’s popularity is its syntax, which is expressive, readable, and dynamic. This allows developers to write training loops, manipulate tensors, and orchestrate workflows without boilerplate friction.
However, it’s Python’s ecosystem that makes it indispensable.
Core frameworks include:
- PyTorch – for research-oriented deep learning
- TensorFlow – for production deployment and scalability
- Keras – for rapid prototyping
- scikit-learn – for classical machine learning
- Hugging Face Transformers – for natural language processing and generative models
These frameworks are mature, well-documented, and interoperable, benefitting from rapid open-source development and extensive community contributions. They support everything from GPU acceleration and distributed training to model export and quantization.
Python also integrates cleanly across the machine learning (ML) pipeline, from data preprocessing with pandas and NumPy to model serving via FastAPI or Flask to inference serving for LLMs with vLLM.
It all comes together to provide a solution that allows you to deliver a working AI solution without ever really having to work outside Python.
2. Strength in data science and analytics
From analytics dashboards to ETL scripts, Python’s flexibility drives fast, interpretable insights across industries. It’s particularly adept at handling complex data, such as time-series analyses.
The State of Python 2025 reveals that 51% of respondents are involved in data exploration and processing. This includes tasks like:
- Data extraction, transformation, and loading (ETL)
- Exploratory data analysis (EDA)
- Statistical and predictive modeling
- Visualization and reporting
- Real-time data analysis
- Communication of insights
Core libraries such as pandas, NumPy, Matplotlib, Plotly, and Jupyter Notebook form a mature ecosystem that’s supported by strong documentation and active community development.
Python offers a unique balance. It’s accessible enough for non-engineers, but powerful enough for production-grade pipelines. It also integrates with cloud platforms, supports multiple data formats, and works seamlessly with SQL and NoSQL data stores.
3. Syntax that’s simple and scalable
Python’s most visible strength remains its readability. Developers routinely cite Python’s low barrier to entry and clean syntax as reasons for initial adoption and longer-term loyalty. In Python, even model training syntax reads like plain English:
def train(model):
for item in model.data:
model.learn(item)
Code snippets like this require no special decoding. That clarity isn’t just beginner-friendly; it also lowers maintenance costs, shortens onboarding time, and improves communication across mixed-skill teams.
This readability brings practical advantages. Teams spend less time deciphering logic and more time improving functionality. Bugs surface faster. Reviews run more smoothly. And non-developers can often read Python scripts without assistance.
The State of Python 2025 revealed that 50% of respondents had less than two years of total coding experience. Over a third (39%) had been coding in Python for two years or less, even in hobbyist or educational settings.
This is where Python really stands out. Though its simple syntax makes it an ideal entry point for new coders, it scales with users, which means retention rates remain high. As projects grow in complexity, Python’s simplicity becomes a strength, not a limitation.
Add to this the fact that Python supports multiple programming paradigms (procedural, object-oriented, and functional), and it becomes clear why readability is important. It’s what enables developers to move between approaches without friction.
4. A mature and versatile ecosystem
Python’s power lies in its vast network of libraries that span nearly every domain of modern software development.
Our survey shows that developers rely on Python for everything from web applications and API integration to data science, automation, and testing.
Its deep, actively maintained toolset means you can use Python at all stages of production.
Here’s a snapshot of Python’s core domains and the main libraries developers reach for:
| Domain | Popular Libraries |
| Web development | Django, Flask, FastAPI |
| AI and ML | TensorFlow, PyTorch, scikit-learn, Keras |
| Testing | pytest, unittest, Hypothesis |
| Automation | Click, APScheduler, Rich |
| Data science | pandas, NumPy, Plotly, Matplotlib |
This breadth translates to real-world agility. Developers can move between back-end APIs and machine learning pipelines without changing language or tooling. They can prototype with high-level wrappers and drop to lower-level control when needed.
Critically, Python’s packaging and dependency management systems like pip, conda, and poetry support modular development and reproducible environments. Combined with frameworks like FastAPI for APIs, pytest for testing, and pandas for data handling, Python offers unrivaled scalability.
5. Community support and shared knowledge
Python’s enduring popularity owes much to its global, engaged developer community.
From individual learners to enterprise teams, Python users benefit from open forums, high-quality tutorials, and a strong culture of mentorship. The community isn’t just helpful, it’s fast-moving and inclusive, fostering a welcoming environment for developers of all levels.
Key pillars include:
- The Python Software Foundation, which supports education, events, and outreach.
- High activity on Stack Overflow, ensuring quick answers to real-world problems, and active participation in open-source projects and local user groups.
- A rich landscape of resources (Real Python, Talk Python, and PyCon), serving both beginners and professionals.
This network doesn’t just solve problems; it also shapes the language’s evolution. Python’s ecosystem is sustained by collaboration, continual refinement, and shared best practices.
When you choose Python, you tap into a knowledge base that grows with the language and with you over time.
6. Cross-domain versatility
Python’s reach is not limited to AI and ML or data science and analytics. It’s equally at home in automation, scripting, web APIs, data workflows, and systems engineering. Its ability to move seamlessly across platforms, domains, and deployment targets makes it the default language for multipurpose development.
The State of Python 2025 shows just how broadly developers rely on Python:
| Functionality | Percentage of Python users |
| Data analysis | 48% |
| Web development | 46% |
| Machine learning | 41% |
| Data engineering | 31% |
| Academic research | 27% |
| DevOps and systems administration | 26% |
That spread illustrates Python’s domain elasticity. The same language that powers model training can also automate payroll tasks, control scientific instruments, or serve REST endpoints. Developers can consolidate tools, reduce context-switching, and streamline team workflows.
Python’s platform independence (Windows, Linux, MacOS, cloud, and browser) reinforces this versatility. Add in a robust packaging ecosystem and consistent cross-library standards, and the result is a language equally suited to both rapid prototyping and enterprise production.
Few languages match Python’s reach, and fewer still offer such seamless continuity. From frontend interfaces to backend logic, Python gives developers one cohesive environment to build and ship full solutions.
That completeness is part of the reason people stick with it. Once you’re in, you rarely need to reach for anything else.
Python in the age of intelligent development
As software becomes more adaptive, predictive, and intelligent, Python is strongly positioned to retain its popularity.
Its abilities in areas like AI, ML, and data handling, as well as its mature libraries, make it a strong choice for systems that evolve over time.
Python’s popularity comes from its ability to easily scale across your projects and platforms. It continues to be a great choice for developers of all experience levels and across projects of all sizes, from casual automation scripts to enterprise AI platforms.
And when working with PyCharm, Python is an intelligent, fast, and clean option.
For a deeper dive, check out The State of Python 2025 by Michael Kennedy, Python expert and host of the Talk Python to Me podcast.
Michael analyzed over 30,000 responses from our Python Developers Survey 2024, uncovering fascinating insights and identifying the latest trends.
Whether you’re a beginner or seasoned developer, The State of Python 2025 will give you the inside track on where the language is now and where it’s headed.
As tools like Astral’s uv show, Python’s evolution is far from over, despite its relative maturity. With a growing ecosystem and proven staying power, it’s well-positioned to remain a popular choice for developers for years to come.
September 24, 2025 11:19 AM UTC
Daniel Roy Greenfeld
Over Twenty Years of Writing Tools
On my articles page, you can read near the top that I've been writing for the past 20 years (plus a little more). It's not all my online public writing, but it's a majority of it. The primary reason parts are missing is that over time, I've used a variety of tools to publish my thoughts. Some of those tools were hosted services, and material that was lost was because of services being shut down. Hence, why I prefer markdown files in a git repository over a database solution.
Here's the story of my writing tools over the years.
Geocities 1997-2010
In 1997, I first remember writing something for general publication on the web. Until then, my writings had been transmitted by printing paper, hand-copying onto disks, sending by email, or posting to usenet. I think it was in 1997 that I made my first essay-style writing on GeoCities site I put together. Geocities is gone, but periodically I've thought of digging through GeoCities archives to find my writing from that time between 1997 and 2004. Otherwise, those articles are gone.
Even though there's nothing from that time on this site, as Geocities overlaps with the first entry on this site, I've included it for the sake of posterity.
Livejournal 2004-2009
From 2004 to 2009, I used LiveJournal to put down my thoughts, and there I wrote on a regular basis about life, activities, fitness, coding, and general work stuff. When I revisit those posts, I see some fun things, some hard challenges, and between the lines a lot carefully hidden despair. The few articles that made it onto this site capture extended family memories.
Some of the articles from LiveJournal exist here.
Blogger 2007-2012
In 2007, blogs had taken off, and it was clear that professionally having my own blog was important. I decided to keep things simple and use Blogger to host my first professional blog. I opened a few other blogger sites for other purposes, but the main one was [PyDanny](https://pydanny.blogspot.com/.
This was my formative years of Python (and Django). Everything was bright and shiny and new. I met Audrey and fell in love with her.
A few years ago, I migrated that content here on this page.
Pelican 2012-2018
In 2012, I started writing content on a Pelican static site. I liked not having to set up a database for content. What I didn't like was having to work through the abstraction of Pelican to do anything.
Mountain 2018-2019
Frustrated with the lack of control of Pelican in 2018, I wrote my own Flask-powered blog engine, which I called Mountain. The challenge there was that I had some crazy ideas for a feature that caused too much complexity. The result was a very slow rendering of the static site. It was too much trouble to fix, so I stuck with it.
Uma was born in early 2019. I was too busy being a new father to do much writing, only getting in 5 articles for the whole of 2019.
Vuepress 2019-2021
By 2019, I was in the Jamstack world. I've since left it, but for a while my site was on Vuepress. The speed of compilation was nice compared to Mountain, and I could stick in special pages as needed. However, there were a few too many layers of abstraction, and that made extending it to work outside the default behaviors of Vuepress too difficult.
Next.js 2021-2024
In early 2021, for work, I needed to learn Next.js quickly. I used the official Next.js tutorial that existed at the time to learn the framework and React over a weekend. This was still the early days of Next.js, and I found it to be tons of fun. It reminded me of the best features of Flask combined with tons of frontend power.
Next.js has changed rapidly. I believe Next.js went in an uncomfortable direction in terms of complexity and decreasing quality of documentation for new or changed features. Bitrot happened frequently, and I felt like I was fighting version upgrades rather than working with the Framework.
FastHTML 2024-2025
I tried out FastHTML in the summer of 2024. Keeping the features spec in my head, tiny, I coded up the kernel of a cached markdown content site in 45 minutes. This was a vast improvement in terms of speed and complexity over the unnecessarily complex Mountain project of 2018. It was nice to return to Python, but it chafed to use a framework that wasn't PEP8 nor fully type-annotated.
Air 2025+
For a few years now, I've wanted to create my own web framework. This year I did so, launching AIR with my wife and coding partner Audrey. Air is a shallow layer over FastAPI, adding features to expedite authoring of dynamic HTML pages. One of the early projects I did with it was to convert this site to use Air. It was nice to return to a PEP8-formatted codebase that is fully type-annotated. I also like the smaller dependency tree.
The Future
Perhaps I'll grow restless again in a few years and try something new. Or perhaps I'll stick with Air for a long time. What I do know is that I enjoy writing and sharing my thoughts. So there will be posts going into the future.
September 24, 2025 12:45 AM UTC
Quansight Labs Blog
Unlocking Performance in Python's Free-Threaded Future: GC Optimizations
A description of the performance optimizations made to the free-threaded garbage collector for Python 3.14.
September 24, 2025 12:00 AM UTC
September 23, 2025
PyCoder’s Weekly
Issue #701: Python to LaTeX Math, MCPs, Playwright, and More (Sept. 23, 2025)
#701 – SEPTEMBER 23, 2025
View in Browser »

3 Tools To Convert Python Code to LaTeX Math
LaTeX is a powerful tool for writing mathematical notation and equations. It is widely used in academic papers, research papers, and technical reports. You can convert Python code to LaTeX in Jupyter notebooks using four powerful tools: IPython.display.Latex, handcalcs, latexify-py, and SymPy.
CODECUT.AI • Shared by Khuyen Tran
Dangers of Automatically Converting a REST API to MCP
When converting an existing REST API to the Model Context Protocol, what should you consider? What anti-patterns should you avoid to keep an AI agent’s context clean? This week on the show, Kyle Stratis returns to discuss his upcoming book, “AI Agents with MCP”.
REAL PYTHON podcast
DevSecCon 2025 Oct 22: The AI Security Developers Challenge

Snyk hosted DevSecCon25 is back, and this time with the very first AI Security Developers Challenge! Get hands-on experience with the latest AI security practices and methodologies for your own AI-driven projects. Register today to stay in the loop and snag your spot before it’s gone →
SNYK.IO sponsor
Playwright & pytest Techniques That Bring Me Joy
Tim has been working on a project with a lot of HTMX and Alpine. The result is a post with a collection of his favorite Playwright and pytest techniques to use when doing end to end testing.
TIM SCHILLING
Python Jobs
Senior Python Developer (Houston, TX, USA)
Articles & Tutorials
Data Science Cloud Lessons at Scale
Talk Python interviews Matthew Rocklin, creator of Dask, and Nat Tabris a staff software engineer at Coiled. They discuss how you can help teams of data scientists to scale from their laptops to large scale clusters.
KENNEDY, ROCKLIN, & TABRIS podcast
DjangoCon US 2025: Security, Simplicity, and Community
At DjangoCon US 2025, speakers emphasized seasoned tech over hype, featuring secure GitOps workflows, simpler frontend alternatives, and sustainable open-source models. This article summarizes some of the key talks.
DWAYNE MCDANIEL
What Context-Aware AI Agents Look Like, on Sept 25
Join Glean:LIVE on Sept 25 for a first look at our next‑gen Assistant and Agents. See our new agentic engine, how to vibe code an agent leveraging SDK & APIs you’re already familiar with, and hear a fireside chat with eBay’s CIO on deploying AI at scale. Register now to secure your spot →
GLEAN sponsor
Playwright vs Pydoll
Playwright and Pydoll are both browser automation libraries typically used for end-to-end testing. This article measures the performance and usability of both of these libraries.
ALBERTO MH
The Python Software Foundation With Deb Nicholson
This podcast is an interview with Deb Nicholson about the Python Software Foundation. They discuss everything from funding open-source projects to organizing community events.
BRESSERS & NICHOLSON
Announcing the 2025 PSF Board Election Results!
The Python Software Foundation board election is complete, resulting in two new members and two who are returning: Abigail Dogbe, Jannis Leidel, Sheena O’Connell, and Simon Willison.
PYTHON SOFTWARE FOUNDATION
Python Project Management With uv
Create and manage Python projects with uv, a blazing-fast package and project manager built in Rust. Learn setup, workflow, and best practices.
REAL PYTHON course
Python 3.14 Preview: REPL Autocompletion and Highlighting
Explore Python 3.14 REPL updates: import autocompletion, syntax coloring, and theme customization to help you code faster and read with ease.
REAL PYTHON
Token Exfiltration Campaign via GitHub Actions Workflows
This post by the PyPI security engineer outlines a recent attack, which thankfully resulted in no compromise to PyPI packages.
MIKE FIEDLER
CodeRabbit: Free AI Code Reviews in CLI
CodeRabbit CLI gives instant code reviews in your terminal. It plugs into any AI coding CLI and catches bugs, security issues, and AI hallucinations before they reach your codebase.
CODERABBIT sponsor
Nested List Comprehensions
Nested list comprehensions in Python can look complex, but with thoughtful whitespace, they can be pretty readable!
TREY HUNNER
Intro to NiceGUI: Build Interactive Python Web Apps
Use NiceGUI to turn Python scripts into interactive web apps without touching HTML, CSS, or JavaScript.
HAZIMED.COM • Shared by Mohamed Haziane
Projects & Code
Events
Weekly Real Python Office Hours Q&A (Virtual)
September 24, 2025
REALPYTHON.COM
PyCon Ghana 2025
September 25 to September 28, 2025
PYCON.ORG
PyCon JP 2025
September 26 to September 28, 2025
PYCON.JP
PyBeach 2025
September 27 to September 28, 2025
PYBEACH.ORG
Building Python Community in Northern Nigeria
September 27 to September 28, 2025
PYTHONNIGER.ORG
PyCon Estonia 2025
October 2 to October 4, 2025
PYCON.EE
PyCon Nigeria 2025
October 2 to October 5, 2025
PYCON.ORG
Happy Pythoning!
This was PyCoder’s Weekly Issue #701.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
September 23, 2025 07:30 PM UTC
Real Python
Strip Characters From a Python String
By default, Python’s .strip() method removes whitespace characters from both ends of a string. To remove different characters, you can pass a string as an argument that specifies a set of characters to remove. The .strip() method is useful for tasks like cleaning user input, standardizing filenames, and preparing data for storage.
By the end of this video course, you’ll understand that:
- The
.strip()method removes leading and trailing whitespace but doesn’t remove whitespace from the middle of a string. - You can use
.strip()to remove specified characters from both ends of the string by providing these characters as an argument. - With the related methods
.lstrip()and.rstrip(), you can remove characters from one side of the string only. - All three methods,
.strip(),.lstrip(), and.rstrip(), remove character sets, not sequences. - You can use
.removeprefix()and.removesuffix()to strip character sequences from the start or end of a string.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 23, 2025 02:00 PM UTC
Quiz: Strip Characters From a Python String
Brush up on how Python’s strip, lstrip, and rstrip string methods work. You’ll practice how to remove whitespace, specific characters, and use the right tool for trimming string ends.
Try these questions to check your understanding of default stripping, custom character sets, and the difference between stripping characters and removing sequences. Need a refresher? See Strip Characters From a Python String.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 23, 2025 12:00 PM UTC
Talk Python to Me
#520: pyx - the other side of the uv coin (announcing pyx)
A couple years ago, Charlie Marsh lit a fire under Python tooling with Ruff and then uv. Today he’s back with something on the other side of that coin: pyx. <br/> <br/> Pyx isn’t a PyPI replacement. Think server, not just index. It mirrors PyPI, plays fine with pip or uv, and aims to make installs fast and predictable by letting a smart client talk to a smart server. When the client and server understand each other, you get new fast paths, fewer edge cases, and the kind of reliability teams beg for. If Python packaging has felt like friction, this conversation is traction. Let’s get into it.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/sixfeetup'>Six Feet Up</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading">Links from the show</h2> <div><strong>Charlie Marsh on Twitter</strong>: <a href="https://twitter.com/charliermarsh?featured_on=talkpython" target="_blank" >@charliermarsh</a><br/> <strong>Charlie Marsh on Mastodon</strong>: <a href="https://hachyderm.io/@charliermarsh?featured_on=talkpython" target="_blank" >@charliermarsh</a><br/> <br/> <strong>Astral Homepage</strong>: <a href="https://astral.sh/?featured_on=talkpython" target="_blank" >astral.sh</a><br/> <strong>Pyx Project</strong>: <a href="https://astral.sh/pyx?featured_on=talkpython" target="_blank" >astral.sh</a><br/> <strong>Introducing Pyx Blog Post</strong>: <a href="https://astral.sh/blog/introducing-pyx?featured_on=talkpython" target="_blank" >astral.sh</a><br/> <strong>uv Package on GitHub</strong>: <a href="https://github.com/astral-sh/uv?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>UV Star History Chart</strong>: <a href="https://www.star-history.com/#astral-sh/uv&Date" target="_blank" >star-history.com</a><br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=YKBcgBgK7gc" target="_blank" >youtube.com</a><br/> <strong>Episode #520 deep-dive</strong>: <a href="https://talkpython.fm/episodes/show/520/pyx-the-other-side-of-the-uv-coin-announcing-pyx#takeaways-anchor" target="_blank" >talkpython.fm/520</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/520/pyx-the-other-side-of-the-uv-coin-announcing-pyx" target="_blank" >talkpython.fm</a><br/> <strong>Developer Rap Theme Song: Served in a Flask</strong>: <a href="https://talkpython.fm/flasksong" target="_blank" >talkpython.fm/flasksong</a><br/> <br/> <strong>--- Stay in touch with us ---</strong><br/> <strong>Subscribe to Talk Python on YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" >youtube.com</a><br/> <strong>Talk Python on Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm at bsky.app</a><br/> <strong>Talk Python on Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i>talkpython</a><br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes at bsky.app</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
September 23, 2025 08:00 AM UTC
September 22, 2025
Jacob Perkins
Async Python Functions with Celery
Celery is a great tool for scheduled function execution in python. You can also use it for running functions in the background asynchronously from your main process. However, it does not support python asyncio. This is a big limitation, because async functions are usually much more I/O efficient, and there are many libraries that provide great async support. And parallel data processing with async.gather becomes impossible in celery without async support.
Celery Async Issues
Unfortunately, based on the current Open status of these issues, celery will not support async functions anytime soon.
But luckily there are two projects that provide async celery support.
AIO Celery
This project is an alternative independent asyncio implementation of Celery
aio-celery “does not depend on the celery codebase”. Instead, it provides a new implementation of the Celery Message Protocol that enables asyncio tasks and workers.
It is written completely from scratch as a thin wrapper around aio-pika (which is an asynchronous RabbitMQ python driver) and it has no other dependencies
It is actively developed, and seems like a great celery alternative. But there are some downsides:
- “Only RabbitMQ as a message broker” means you cannot use any other broker such as Redis
- “Only Redis as a result backend” means you can’t store results in any other database
- “Complete feature parity with upstream Celery project is not the goal”, so there may be features from celery you want that are not present in aio-celery
Celery AIO Pool
celery-aio-pool provides a custom worker pool implementation that works with celery 5.3+. Unlike aio-celery, you can keep using your existing celery implementation. All you have to do to get async task support in celery is:
- Start your celery worker with this environment variable:
CELERY_CUSTOM_WORKER_POOL='celery_aio_pool.pool:AsyncIOPool' - Run the celery worker process with
--pool=custom
So your worker command will look like
CELERY_CUSTOM_WORKER_POOL='celery_aio_pool.pool:AsyncIOPool' celery worker --pool=customplus whatever other arguments or environment variables you need. Once you have this in place, you can start using async functions as celery tasks.
While celery-aio-pool is not as actively developed, it works, and has the following benefits:
- Simple to install and configure with Celery >= 5.3
- Works with any celery support message broker or result backend
- Works with your existing celery setup without requiring any other changes
September 22, 2025 05:00 PM UTC
Ned Batchelder
Testing is better than DSA
I see new learners asking about “DSA” a lot. Data Structures and Algorithms are of course important: considered broadly, they are the two ingredients that make up all programs. But in my opinion, “DSA” as an abstract field of study is over-emphasized.
I understand why people focus on DSA: it’s a concrete thing to learn about, there are web sites devoted to testing you on it, and most importantly, because job interviews often involve DSA coding questions.
Before I get to other opinions, let me make clear that anything you can do to help you get a job is a good thing to do. If grinding leetcode will land you a position, then do it.
But I hope companies hiring entry-level engineers aren’t asking them to reverse linked lists or balance trees. Asking about techniques that can be memorized ahead of time won’t tell them anything about how well you can work. The stated purpose of those interviews is to see how well you can figure out solutions, in which case memorization will defeat the point.
The thing new learners don’t understand about DSA is that actual software engineering almost never involves implementing the kinds of algorithms that “DSA” teaches you. Sure, it can be helpful to work through some of these puzzles and see how they are solved, but writing real code just doesn’t involve writing that kind of code.
Here is what I think in-the-trenches software engineers should know about data structures and algorithms:
- Data structures are ways to organize data. Learn some of the basics: linked list, array, hash table, tree. By “learn” I mean understand what it does and why you might want to use one.
- Different data structures can be used to organize the same data in different ways. Learn some of the trade-offs between structures that are similar.
- Algorithms are ways of manipulating data. I don’t mean named algorithms like Quicksort, but algorithms as any chunk of code that works on data and does something with it.
- How you organize data affects what algorithms you can use to work with the data. Some data structures will be slow for some operations where another structure will be fast.
- Algorithms have a “time complexity” (Big O): how the code slows as the data grows. Get a sense of what this means.
- Python has a number of built-in data structures. Learn how they work, and the time complexity of their operations.
- Learn how to think about your code to understand its time complexity.
- Read a little about more esoteric things like Bloom filters, so you can find them later in the unlikely case you need them.
Here are some things you don’t need to learn:
- The details of a dozen different sorting algorithms. Look at two to see different ways of approaching the same problem, then move on.
- The names of “important” algorithms. Those have all been implemented for you.
- The answers to all N problems on some quiz web site. You won’t be asked these exact questions, and they won’t come up in your real work. Again: try a few to get a feel for how some algorithms work. The exact answers are not what you need.
Of course some engineers need to implement hash tables, or sorting algorithms or whatever. We love those engineers: they write libraries we can use off the shelf so we don’t have to implement them ourselves.
There have been times when I implemented something that felt like An Algorithm (for example, Finding fuzzy floats), but it was more about considering another perspective on my data, looking at the time complexity, and moving operations around to avoid quadratic behavior. It wasn’t opening a textbook to find the famous algorithm that would solve my problem.
Again: if it will help you get a job, deep-study DSA. But don’t be disappointed when you don’t use it on the job.
If you want to prepare yourself for a career, and also stand out in job interviews, learn how to write tests:
- This will be a skill you use constantly. Real-world software means writing tests much more than school teaches you to.
- In a job search, testing experience will stand out more than DSA depth. It shows you’ve thought about what it takes to write high-quality software instead of just academic exercises.
- It’s not obvious how to test code well. It’s a puzzle and a problem to solve. If you like figuring out solutions to tricky questions, focus on how to write code so that it can be tested, and how to test it.
- Testing not only gives you more confidence in your code, it helps you write better code in the first place.
- Testing applies everywhere, from tiny bits of code to entire architectures, assisting you in design and implementation at all scales.
- If pursued diligently, testing is an engineering discipline in its own right, with a fascinating array of tools and techniques.
Less DSA, more testing.