
Planet Python
Last update: July 01, 2025 09:42 PM UTC
July 01, 2025
PyCoder’s Weekly
Issue #688: Checking Dicts, DuckDB, Reading shelve.py, and More (July 1, 2025)
#688 – JULY 1, 2025
View in Browser »

Statically Checking Python Dicts for Completeness
To keep code concerns separate you might have two data structures (like an Enum and a dict) that are supposed to change in sequence: adding a value to the Enum requires you to add a similar value in the dict. This is common when separating business logic from UI code. This article shows you ways of making sure the corresponding changes happen together.
LUKE PLANT
Starting With DuckDB and Python
Learn how to use DuckDB in Python to query large datasets with SQL or its Python API, handle files like Parquet or CSV, and integrate with pandas or Polars.
REAL PYTHON course
From AI Hype to Durable Reality: Why Agentic Flows Need Distributed-Systems Discipline

If you’ve explored building agentic AI, you’ve likely discovered that the glamorous part of AI ends quickly; operationalizing for production is where projects live or die. Explore these seven lessons from our team on how to transform agentic flows into reliable powerhouses →
TEMPORAL sponsor
Code Reading: The Python Module shelve.py
Reading code is a great way to learn to write better code. This post walks you through the standard library shelve module as code-reading practice.
BEYOND DREAMSCAPE
Python Jobs
Sr. Software Developer (Python, Healthcare) (USA)
Articles & Tutorials
New Python Client Library for Google Data Commons
Google Data Commons announced the general availability of its new Python client library for the Data Commons. The goal of the library is to enhance how students, researchers, analysts, and data scientists access and leverage Data Commons.
KARA MOSCOE • Shared by Ariana Gaspar
From Notebooks to Production Data Science Systems
Talk Python To Me interviews Catherine Nelson and they discuss techniques and tools to move your data science from an experimental notebook to full production workflows.
KENNEDY & NELSON podcast
Deploy Your Streamlit, Dash, Bokeh Apps all in one Place
Posit Connect Cloud is a cloud environment for showcasing your Python apps, no matter the framework.
POSIT sponsor
Python enumerate(): Simplify Loops That Need Counters
Learn how to simplify your loops with Python’s enumerate(). This tutorial shows you how to pair items with their index cleanly and effectively using real-world examples.
REAL PYTHON
Your Guide to the Python print() Function
Learn how Python’s print() function works, avoid common pitfalls, and explore powerful alternatives and hidden features that can improve your code.
REAL PYTHON
Building a Multi-Tenant App With Django
This tutorial explains how to implement a multi-tenant web app in Django using the django-tenants and django-tenant-users packages.
NIK TOMAZIC • Shared by Michael Herman
Flask or Django: Which One Best Fits Your Python Project?
Explore the key factors to take into account when deciding between Flask or Django for your Python app.
FEDERICO TROTTA • Shared by AppSignal
Fun With uv and PEP 723
How to use uv and the Python inline script metadata proposal PEP 723 to run scripts seamlessly.
DEEPAK JOIS
How I’ve Run Major Projects
If you want to progress to being a technical lead, you need to understand how to manage projects. This post talks about the skills you need, and how often times it is mostly about being organized.
BEN KUHN
How to Think About Time in Programming
Time is a complex thing to code. This article is a very deep dive, covering absolute measurement, civil time, modern time keeping, the mess that are timezones, and much more.
SHAN RAUF
Projects & Code
POC Implementation of Progressive JSON
GITHUB.COM/MACIEYNG • Shared by Maciej
Events
🇨🇦
July 1, 2025
REALPYTHON.COM
Python New Zealand: Python Learners’ Co-Op
July 3, 2025
IRIDESCENT.NZ
Canberra Python Meetup
July 3, 2025
MEETUP.COM
Sydney Python User Group (SyPy)
July 3, 2025
SYPY.ORG
PyCon Colombia 2025
July 4 to July 7, 2025
PYCON.CO
Python Norte 2025
July 4 to July 7, 2025
PYTHONNORTE.ORG
SciPy 2025
July 7 to July 14, 2025
SCIPY.ORG
Python-Powered Cloud on July 22
July 22, 2025
MEETUP.COM • Shared by Laura Stephens
Happy Pythoning!
This was PyCoder’s Weekly Issue #688.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Real Python
Implementing the Factory Method Pattern in Python
This video course explores the Factory Method design pattern and its implementation in Python. Design patterns became a popular topic in late 90s after the so-called Gang of Four (GoF: Gamma, Helm, Johson, and Vlissides) published their book Design Patterns: Elements of Reusable Object-Oriented Software.
The book describes design patterns as a core design solution to reoccurring problems in software and classifies each design pattern into categories according to the nature of the problem. Each pattern is given a name, a problem description, a design solution, and an explanation of the consequences of using it.
The GoF book describes Factory Method as a creational design pattern. Creational design patterns are related to the creation of objects, and Factory Method is a design pattern that creates objects with a common interface.
This is a recurrent problem that makes Factory Method one of the most widely used design patterns, and it’s very important to understand how it works and know how to apply it.
By the end of this video course, you’ll:
- Understand the components of Factory Method
- Recognize opportunities to use Factory Method in your applications
- Know how to modify existing code and improve its design by using the pattern
- Be able to identify opportunities where Factory Method is the appropriate design pattern
- Know how to choose an appropriate implementation of Factory Method
- Understand how to implement a reusable, general purpose solution of Factory Method
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Mike Driscoll
Creating a Website with Sphinx and Markdown
Sphinx is a Python-based documentation builder. The Python documentation is written using Sphinx. The Sphinx project supports using ReStructuredText and Markdown, or a mixture of the two. Each page of your documentation or website must be written using one of those two formats.
The original Python 101 website uses an old version of Sphinx, for example.
In this tutorial, you will learn how to use Sphinx to create a documentation site. Here is an overview of what you’ll learn:
- Getting the dependencies
- Setting up the site
- Making Markdown work in Sphinx
- Building your Sphinx site
- Adding content to your site
Let’s start by installing all the packages you need to get Sphinx working!
Getting the Dependencies
You will need the following packages to be able to use Sphinx and Markdown:
- sphinx
- myst-parser
You should install these package in a Python virtual environment. Open up your terminal and pick a location where you would like to create a new folder. Then run the following command:
python -m venv NAME_OF_VENV_FOLDER
Once you have the virtual environment, you need to activate it. Go into the Scripts folder and run the activate command in there.
Now you can install the dependencies that you need using pip, which will install them to your virtual environment.
Here’s how to install them using pip:
python -m pip install myst-parser sphinx
Once your packages are installed, you can learn how to set up your site!
Setting Up the Site
Now that your packages are installed, you must set up your Sphinx website. To create a barebones Sphinx site, run the following command inside your virtual environment:
sphinx-quickstart NAME_OF_SITE_FOLDER
It will ask you a series of questions. The Sphinx documentation recommends keeping the source and build folders separate. Otherwise, you can set the other fields as needed or accept the defaults.
You will now have the following tree structure in your SITE_FOLDER:

You will work with the files and directories in this structure for the rest of the tutorial.
The next step on your Sphinx journey is to enable Markdown support.
Making Markdown Work in Sphinx
Go into the source directory and open the conf.py file in your favorite Python IDE. Update the extensions and the source_suffix variables to the following (or add them if they do not exist):
extensions = ['myst_parser'] source_suffix = ['.rst', '.md']
These changes tell Sphinx to use the Myst parser for Markdown files. You also leave ReStructuredText files in there so that your Sphinx website can handle that format.
You now have enough of your site available to build it and ensure it works.
Building Your Sphinx Site
You can now build a simple site with only an index page and the auto-generated boilerplate content. In your terminal, run the following command in the root of your Sphinx folder:
sphinx-build -M html .\source\ .\build\
The HTML files will be created inside the build/html folder. If you open the index page, it will look something like this:

Good job! You now have a Sphinx website!
Now you need to add some custom content to it.
Adding Content to Your Site
You can add ReStructuredText or Markdown files for each page of your site. You must update your index.rst file to add those pages to your table of contents using the toctree section:
.. toctree:: :maxdepth: 2 :caption: Contents: SUB_FOLDER/acknowledgments.md doc_page1.md OTHER_FOLDER/sub_doc_page1.md
Let’s add some real content. Create a new file called decorators.md in the root folder that contains the index.rst file. Then enter the following text in your new Markdown file:
# Python: All About Decorators Decorators can be a bit mind-bending when first encountered and can also be a bit tricky to debug. But they are a neat way to add functionality to functions and classes. Decorators are also known as a “higher-order function”. This means that they can take one or more functions as arguments and return a function as its result. In other words, decorators will take the function they are decorating and extend its behavior while not actually modifying what the function itself does. There have been two decorators in Python since version 2.2, namely **classmethod()** and **staticmethod()**. Then PEP 318 was put together and the decorator syntax was added to make decorating functions and methods possible in Python 2.4. Class decorators were proposed in PEP 3129 to be included in Python 2.6. They appear to work in Python 2.7, but the PEP indicates they weren’t accepted until Python 3, so I’m not sure what happened there. Let’s start off by talking about functions in general to get a foundation to work from. ## The Humble Function A function in Python and in many other programming languages is just a collection of reusable code. Some programmers will take an almost bash-like approach and just write all their code in a file with no functions. The code just runs from top to bottom. This can lead to a lot of copy-and-paste spaghetti code. Whenever two pieces of code do the same thing, they can almost always be put into a function. This will make updating your code easier since you’ll only have one place to update them.
Make sure you save the file. Then, re-run the build command from the previous section. Now, when you open the index.html file, you should see your new Markdown file as a link that you click on and view.
Wrapping Up
Sphinx is a powerful way to create documentation for your projects. Sphinx has many plugins that you can use to make it even better. For example, you can use sphinx-apidoc to automatically generate documentation from your source code using the autodoc extension.
If you are an author and you want to share your books online, Sphinx is a good option for that as well. Having a built-in search functionality makes it even better. Give Sphinx a try and see what it can do for you!
The post Creating a Website with Sphinx and Markdown appeared first on Mouse Vs Python.
Zero to Mastery
[June 2025] Python Monthly Newsletter 🐍
67th issue of Andrei Neagoie's must-read monthly Python Newsletter: Fastest Python, MCP Eats The World, Optimize Your Python, and much more. Read the full newsletter to get up-to-date with everything you need to know from last month.
Tryton News
Newsletter July 2025

In the last month we focused on fixing bugs, improving the behaviour of things, speeding-up performance issues - building on the changes from our last release. We also added some new features which we would like to introduce to you in this newsletter.
For an in depth overview of the Tryton issues please take a look at our issue tracker or see the issues and merge requests filtered by label.
Changes for the User
Accounting, Invoicing and Payments
Now we provide a dedicated list view to display the children lines on budget forms.
As we do not need the full record name but just the current name when editing a child from its parent form.
User Interface
We now converted Unidentified Image Errors into more user friendly validation errors. The normalisation/preprocess of images using PIL (Python Image Library) may raise these exceptions.
Now we keep selected rows on xxx2Many widget on reload.
We now limit the height of the completion drop downs and the actions are set sticky to be always visible.
System Data and Configuration
In order to have always the same results no matter of the order of the lines, we now round the tax amount of each line before adding it to the total tax.
In the past we rounded the tax amount per line after it was added to the total tax. With the used bankers rounding the issue is that when the result is like .xy5 (if rounding precision is set to 2 digits) it may be rounded up or down depending if the y-digit is even or odd.
New Releases
We released bug fixes for the currently maintained long term support series
7.0 and 6.0, and for the penultimate series 7.6, 7.4 and 7.2.
1 post - 1 participant
Seth Michael Larson
Hand-drawn QR codes
I really like QR codes. Recently I purchased a new sticky-note-like pad from a new local stationery store in Minneapolis. The sheets have a 10x10 grid and 2x10 grid.

I knew what I wanted to do, I wanted to create a QR code on a sheet. The smallest QR code (besides micro QR codes) is "version 1" which uses 21x21 pixels. We'll have to split the squares in half and then use some of the margin.
Version 1 QR codes can hold URLs up to 17 bytes long using the lowest
data quality setting. Unfortunately https://sethmlarson.dev is 23 bytes
long, so I'll have to improvise. I went with sethmlarson.dev instead, as this
will prompt many QR code scanners to "search" for the term resulting in my website.
Note that a lovely reader informed me shortly after publication that indeed I can include my full domain name in a version 1 QR code by using all capital letters instead of lowercase. TIL that the "alphanumeric" character set for QR codes actually contains symbols for URLs like
:and/.Expect an updated QR code published after lunch today. :)
I created my reference using the qrcode package on the Python Package Index. Don't forget
the -n option with echo to not include a trailing newline.
$ echo -n "HTTPS://SETHMLARSON.DEV" | qr --error-correction=L
I drew the corner squares (known as "position patterns") and then started trying to scan the QR code as a gradually filled in other pixels. Once I had drawn the "timing lines" between the top left and bottom left position I could see that my scanner "wanted" to see something in my drawing.

I continued adding the top timing line and data and then the scanner could start to see the whole square as a QR code. If you look closely I even made a mistake here in the data a bit, but in the end this didn't matter even on the lowest error-correction level.

Finally, my QR code was complete! Scanning the QR code was quite finicky because the paper was curling up off the flat surface. I could only get the scan to work when I held the paper flat. However, hanging the QR code from my monitor worked extremely well, even when scanning from a distance.

I hope this inspires you to try hand-drawing something on grid paper 🖤🤍 If you're looking for more grid-based inspiration, take a look at GRID WORLD, a web art piece by Alexander Miller.
June 30, 2025
Real Python
Use TorchAudio to Prepare Audio Data for Deep Learning
Ever wondered how machine learning models process audio data? How do you handle different audio lengths, convert sound frequencies into learnable patterns, and make sure your model is robust? This tutorial will show you how to handle audio data using TorchAudio, a PyTorch-based toolkit.
You’ll work with real speech data to learn essential techniques like converting waveforms to spectrograms, standardizing audio lengths, and adding controlled noise to build machine and deep learning models.
By the end of this tutorial, you’ll understand that:
- TorchAudio processes audio data for deep learning, including tasks like loading datasets and augmenting data with noise.
- You can load audio data in TorchAudio using the
torchaudio.load()function, which returns a waveform tensor and sample rate. - TorchAudio normalizes audio by default during loading, scaling waveform amplitudes between -1.0 and 1.0.
- A spectrogram visually represents the frequency spectrum of an audio signal over time, aiding in frequency analysis.
- You can pad and trim audio in TorchAudio using
torch.nn.functional.pad()and sequence slicing for uniform audio lengths.
Dive into the tutorial to explore these concepts and learn how they can be applied to prepare audio data for deep learning tasks using TorchAudio.
Take the Quiz: Test your knowledge with our interactive “Use TorchAudio to Prepare Audio Data for Deep Learning” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Use TorchAudio to Prepare Audio Data for Deep LearningTest your grasp of audio fundamentals and working with TorchAudio in Python! You'll cover loading audio datasets, transforms, and more.
Learn Essential Technical Terms
Before diving into the technical details of audio processing with TorchAudio, take a moment to review some key terms. They’ll help you grasp the basics of working with audio data.
Waveform
A waveform is the visual representation of sound as it travels through air over time. When you speak, sing, or play music, you create vibrations that move through the air as waves. These waves can be captured and displayed as a graph showing how the sound’s pressure changes over time. Here’s an example:
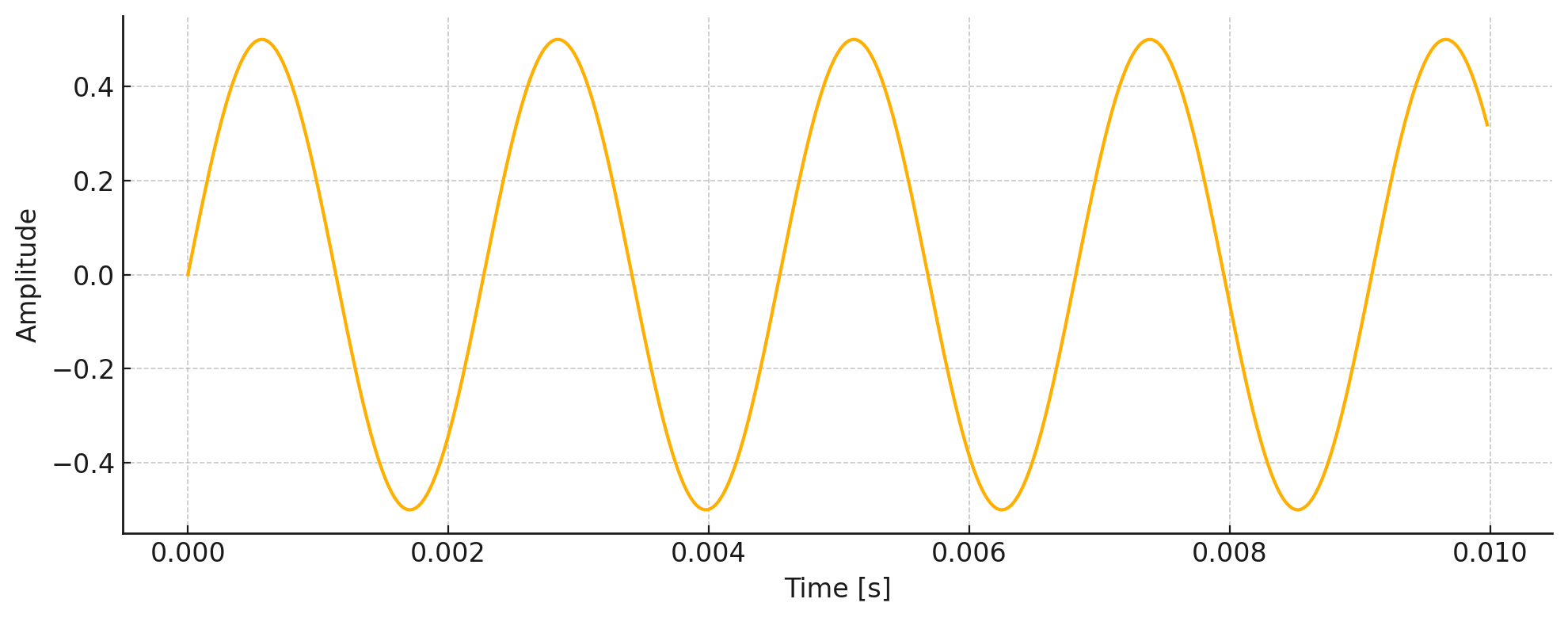 A Sample Waveform of a 440 Hz Wave
A Sample Waveform of a 440 Hz Wave
This is a waveform of a 440 Hz wave, plotted over a short duration of 10 milliseconds (ms). This is called a time-domain representation, showing how the wave’s amplitude changes over time. This waveform shows the raw signal as it appears in an audio editor. The ups and downs reflect changes in loudness.
Amplitude
Amplitude is the strength or intensity of a sound wave—in other words, how loud the sound is to the listener. In the previous image, it’s represented by the height of the wave from its center line.
A higher amplitude means a louder sound, while a lower amplitude means a quieter sound. When you adjust the volume on your device, you’re actually changing the amplitude of the audio signal. In digital audio, amplitude is typically measured in decibels (dB) or as a normalized value between -1 and 1.
Frequency
Frequency is how many times a sound wave repeats itself in one second, measured in hertz (Hz). For example, a low bass note is a sound wave that repeats slowly, about 50–100 Hz. In contrast, a high-pitched whistle has a wave that repeats much faster, around 2000–3000 Hz.
In music, different frequencies create different musical notes. For instance, the A4 note that musicians use to tune their instruments is exactly 440 Hz. Now, if you were to look at the frequency plot of the 440 Hz waveform from before, here’s what you’d see:
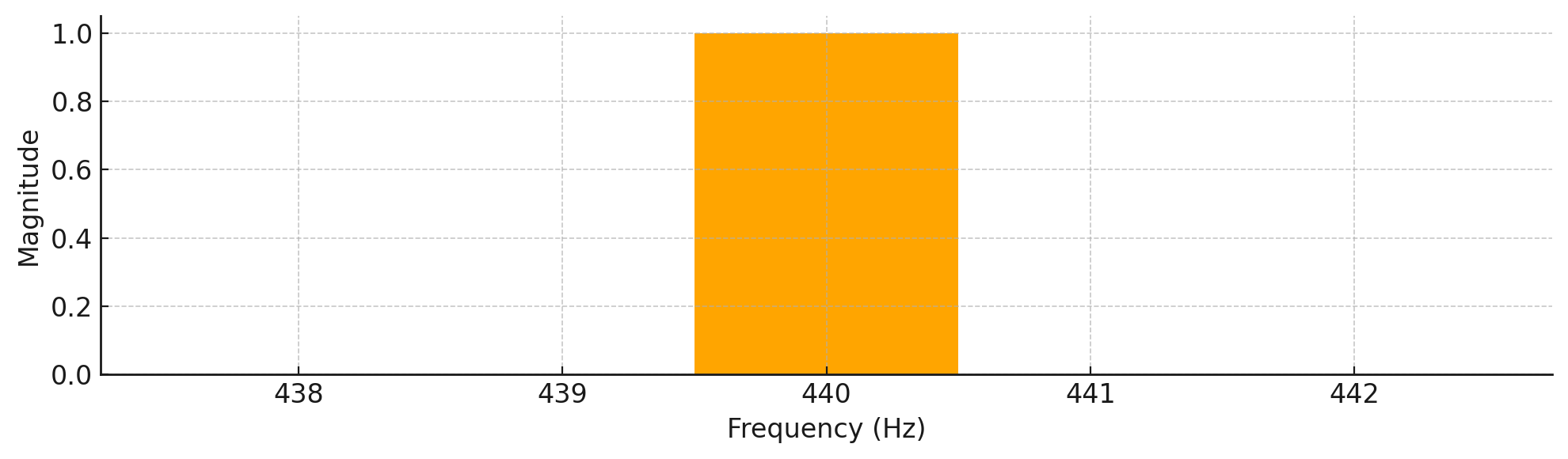 A Frequency Domain Plot of a 440 Hz Wave
A Frequency Domain Plot of a 440 Hz Wave
This plot displays the signal in the frequency domain, which shows how much of each frequency is present in the sound. The distinct peak at 440 Hz indicates that this is the dominant frequency in the signal, which is exactly what you’d expect from a pure tone. While time-domain plots—like the one you saw earlier—reveal how the sound’s amplitude changes over time, frequency-domain plots help you understand which frequencies make up the sound.
The waveform you just explored was from a 440 Hz wave. You’ll soon see that many examples in audio processing also deal with this mysterious frequency. So, what makes it so special?
Note: The 440 Hz frequency (A4 note) is the international standard pitch reference for tuning instruments. Its clear, single-frequency nature makes it great for audio tasks. These include sampling, frequency analysis, and waveform representation.
Now that you understand frequency and how it relates to sound waves, you might be wondering how computers actually capture and store these waves.
Sampling
When you record sound digitally, you’re taking snapshots of the audio wave many times per second. Each snapshot measures the wave’s amplitude at that instant. This is called sampling. The number of snapshots taken per second is the sampling rate, measured in hertz (Hz).
Read the full article at https://realpython.com/python-torchaudio/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Quiz: Use TorchAudio to Prepare Audio Data for Deep Learning
In this quiz, you’ll test your understanding of audio fundamentals and how to Use TorchAudio to Prepare Audio Data for Deep Learning.
You’ll revisit fundamental terminology and how to:
- Install and import TorchAudio
- Load audio waveform datasets
- Apply signal transforms
Work through these questions to check your knowledge about building audio workflows for machine learning in Python.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Django Weblog
Our 2024 Annual Impact Report
Django has always been more than just a web framework; it’s a testament to what a dedicated community can build together. Behind every Django release, bug fix, or DjangoCon is a diverse network of people working steadily to strengthen our open-source ecosystem. To celebrate our collective effort, the Django Software Foundation (DSF) is excited to share our 2024 Annual Impact Report 🎉
In this report, you’ll discover key milestones, narratives of community folks, the impact of the events running throughout the year, and much more, ramping up to how we’re laying the groundwork for an even more resilient and inclusive Django community.
Why we publish this report
Transparency is essential for our community-driven organization. Everyone deserves to know how our work and investments translate into real impact. It’s more than just statistics. It’s our way to:
- Show how your contributions make a difference, with vibrant highlights from the past year.
- Reflect on community progress, recognizing the people and ideas that keep Django thriving.
- Invite more individuals and organizations to get involved.
Looking ahead: call to action
As we make progress through 2025, the Django Software Foundation remains dedicated to strengthening the ecosystem that supports developers, contributors, and users around the world. With a growing network of working groups, community initiatives, and the commitment of volunteers, we’re focused on nurturing the people and executing ideas that make Django what it is: the web framework for perfectionists with deadlines.
Help keep this momentum strong by supporting Django through any of the following ways:
- Donate to Django to support future development
- Convince your company to become a Corporate Member
- Join the Foundation as an Individual Member
- Get involved with the working groups
- Join our community on the Django Forum or Discord server.
- Follow and re-share our posts on Mastodon, on Bluesky, or on X.
- Follow our page on LinkedIn.
Thank you, everyone, for your dedication and efforts. Here’s to another year of collaboration, contribution, and shared success!
Python Bytes
#438 Motivation time
<strong>Topics covered in this episode:</strong><br> <ul> <li><em>* <a href="https://www.pythonmorsels.com/articles/cheat-sheet/?featured_on=pythonbytes">Python Cheat Sheets from Trey Hunner</a></em>*</li> <li><em>* <a href="https://automatisch.io?featured_on=pythonbytes">Automatisch</a></em>*</li> <li><em>* <a href="https://github.com/hbmartin/mureq-typed?featured_on=pythonbytes">mureq-typed</a></em>*</li> <li><em>* <a href="https://frankwiles.com/posts/my-cli-world/?featured_on=pythonbytes">My CLI World</a></em>*</li> <li><strong>Extras</strong></li> <li><strong>Joke</strong></li> </ul><a href='https://www.youtube.com/watch?v=CJdZvyoftDE' style='font-weight: bold;'data-umami-event="Livestream-Past" data-umami-event-episode="438">Watch on YouTube</a><br> <p><strong>About the show</strong></p> <p><strong>Sponsored by</strong> <strong>Posit:</strong> <a href="https://pythonbytes.fm/connect">pythonbytes.fm/connect</a></p> <p><strong>Connect with the hosts</strong></p> <ul> <li>Michael: <a href="https://fosstodon.org/@mkennedy">@mkennedy@fosstodon.org</a> / <a href="https://bsky.app/profile/mkennedy.codes?featured_on=pythonbytes">@mkennedy.codes</a> (bsky)</li> <li>Brian: <a href="https://fosstodon.org/@brianokken">@brianokken@fosstodon.org</a> / <a href="https://bsky.app/profile/brianokken.bsky.social?featured_on=pythonbytes">@brianokken.bsky.social</a></li> <li>Show: <a href="https://fosstodon.org/@pythonbytes">@pythonbytes@fosstodon.org</a> / <a href="https://bsky.app/profile/pythonbytes.fm">@pythonbytes.fm</a> (bsky)</li> </ul> <p>Join us on YouTube at <a href="https://pythonbytes.fm/stream/live"><strong>pythonbytes.fm/live</strong></a> to be part of the audience. Usually <strong>Monday</strong> at 10am PT. Older video versions available there too.</p> <p>Finally, if you want an artisanal, hand-crafted digest of every week of the show notes in email form? Add your name and email to <a href="https://pythonbytes.fm/friends-of-the-show">our friends of the show list</a>, we'll never share it.</p> <p><strong>Brian #1: <a href="https://www.pythonmorsels.com/articles/cheat-sheet/?featured_on=pythonbytes">Python Cheat Sheets from Trey Hunner</a></strong></p> <ul> <li>Some fun sheets <ul> <li><a href="https://www.pythonmorsels.com/string-formatting/?featured_on=pythonbytes">Python f-string tips & cheat sheets</a></li> <li><a href="https://www.pythonmorsels.com/pathlib-module/?featured_on=pythonbytes">Python's pathlib module</a></li> <li><a href="https://www.pythonmorsels.com/cli-tools/?featured_on=pythonbytes">Python's many command-line utilities</a></li> </ul></li> </ul> <p><strong>Michael #2: <a href="https://automatisch.io?featured_on=pythonbytes">Automatisch</a></strong></p> <ul> <li>Open source Zapier alternative</li> <li>Automatisch helps you to automate your business processes without coding.</li> <li>Use their affordable cloud solution or self-host on your own servers.</li> <li>Automatisch allows you to store your data on your own servers, good for companies dealing with sensitive user data, particularly in industries like healthcare and finance, or those based in Europe bound by General Data Protection Regulation (GDPR).</li> </ul> <p><strong>Michael #3: <a href="https://github.com/hbmartin/mureq-typed?featured_on=pythonbytes">mureq-typed</a></strong></p> <ul> <li>Single file, zero-dependency alternative to requests. Fully typed. Modern Python tooling.</li> <li>Typed version of mureq (covered in 2022 on episode 268)</li> <li>Intended to be vendored in-tree by Linux systems software and other lightweight applications.</li> <li><code>mureq-typed</code> is a drop-in, fully API compatible replacement for mureq updated with modern Python tooling:</li> <li>Type checked with mypy, ty, and pyrefly.</li> <li>Formatted with black, no ignore rules necessary.</li> <li>Linted with ruff (add <a href="https://github.com/hbmartin/mureq-typed/blob/master/ruff.toml#L11">these rules</a> for <code>mureq.py</code> to your <code>per-file-ignores</code>).</li> </ul> <p><strong>Brian #4: <a href="https://frankwiles.com/posts/my-cli-world/?featured_on=pythonbytes">My CLI World</a></strong></p> <ul> <li>Frank Wiles</li> <li>Encouragement to modify your command line environment</li> <li>Some of Franks tools <ul> <li><a href="https://direnv.net?featured_on=pythonbytes">direnv</a>, <a href="https://github.com/ajeetdsouza/zoxide?featured_on=pythonbytes">zoxide</a>, <a href="https://github.com/sharkdp/fd?featured_on=pythonbytes">fd</a>, <a href="https://beyondgrep.com/documentation/?featured_on=pythonbytes">ack</a>, <a href="https://atuin.sh?featured_on=pythonbytes">atuin</a>, <a href="https://just.systems/man/en/?featured_on=pythonbytes">just</a></li> </ul></li> <li>Also some aliases, like <a href="https://frankwiles.com/posts/two-handy-git-aliases/?featured_on=pythonbytes">gitpulllog</a></li> <li>Notes <ul> <li>We covered <a href="https://poethepoet.natn.io/index.html?featured_on=pythonbytes">poethepoet</a> recently, if just just isn’t cutting it for you.</li> <li>I tried to ilke starship, bit for some reason with my setup, it slows down the shell too much.</li> </ul></li> </ul> <p><strong>Extras</strong></p> <p>Brian:</p> <ul> <li>Interesting read of the week: <a href="https://phys.org/news/2025-06-theory-dimensions-space-secondary-effect.html?featured_on=pythonbytes"><strong>New theory proposes time has three dimensions, with space as a secondary effect</strong></a></li> <li>Michael's: <a href="https://phys.org/news/2025-05-quantum-theory-gravity-sought-crucial.html?featured_on=pythonbytes"><strong>New quantum theory of gravity brings long-sought 'theory of everything' a crucial step closer</strong></a></li> </ul> <p><strong>Joke:</strong></p> <ul> <li><p>Brian read a few quotes from the book </p> <p>Disappointing Affirmations, by Dave Tarnowski</p> <ul> <li>“You are always just a moment away from your next worst day ever. Or your next best day ever, but let’s be realistic.”</li> <li>“You can be anything you want. And yet you keep choosing to be you. I admire your dedication to the role.”</li> <li>“Today I am letting go of the things that are holding me back from the life that I want to live. Then I’m picking them all up again because I have separation anxiety.”</li> </ul></li> </ul>
June 27, 2025
Hugo van Kemenade
Run coverage on tests
I recommend running coverage on your tests.
Here’s a couple of reasons why, from the past couple of months.
Example one #
When writing tests, it’s common to copy and paste test functions, but sometimes you forget to rename the new one (see also: the Last Line Effect).
For example:
def test_get_install_to_run_with_platform(patched_installs):
i = installs.get_install_to_run("<none>", None, "1.0-32")
assert i["id"] == "PythonCore-1.0-32"
assert i["executable"].match("python.exe")
i = installs.get_install_to_run("<none>", None, "2.0-arm64")
assert i["id"] == "PythonCore-2.0-arm64"
assert i["executable"].match("python.exe")
def test_get_install_to_run_with_platform(patched_installs):
i = installs.get_install_to_run("<none>", None, "1.0-32", windowed=True)
assert i["id"] == "PythonCore-1.0-32"
assert i["executable"].match("pythonw.exe")
i = installs.get_install_to_run("<none>", None, "2.0-arm64", windowed=True)
assert i["id"] == "PythonCore-2.0-arm64"
assert i["executable"].match("pythonw.exe")
The tests pass, but the first one is never run because its name is redefined. This clearly shows up as a non-run test in the coverage report. In this case, we only need to rename one of them, and both are covered and pass.
But sometimes there’s a bug in the test which would cause it to fail, but we just don’t know because it’s not run.
Example two #
This is more subtle:
im = Image.new("RGB", (1, 1))
for colors in (("#f00",), ("#f00", "#0f0")):
append_images = (Image.new("RGB", (1, 1), color) for color in colors)
im_reloaded = roundtrip(im, save_all=True, append_images=append_images)
assert_image_equal(im, im_reloaded)
assert isinstance(im_reloaded, MpoImagePlugin.MpoImageFile)
assert im_reloaded.mpinfo is not None
assert im_reloaded.mpinfo[45056] == b"0100"
for im_expected in append_images:
im_reloaded.seek(im_reloaded.tell() + 1)
assert_image_similar(im_reloaded, im_expected, 1)
It’s not so obvious when looking at the code, but Codecov highlights a problem:
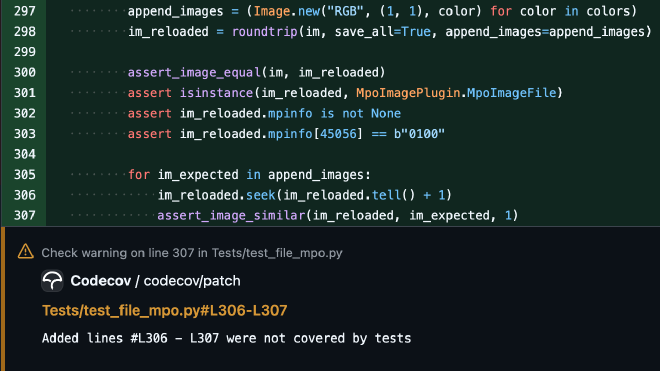
The append_images generator is being consumed inside roundtrip(), so we have nothing
to iterate over in the for loop – hence no coverage. The
fix is to
use a list instead of a generator.
Header photo: Misplaced manhole cover (CC BY-NC-SA 2.0 Hugo van Kemenade).
Real Python
The Real Python Podcast – Episode #255: Structuring Python Scripts & Exciting Non-LLM Software Trends
What goes into crafting an effective Python script? How do you organize your code, manage dependencies with PEP 723, and handle command-line arguments for the best results? Christopher Trudeau is back on the show this week, bringing another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Luke Plant
Statically checking Python dicts for completeness
In Python, I often have the situation where I create a dictionary, and want to ensure that it is complete – it has an entry for every valid key.
Let’s say for my (currently hypothetical) automatic squirrel-deterring water gun system, I have a number of different states the water tank can be in, defined using an enum:
from enum import StrEnum class TankState(StrEnum): FULL = "FULL" HALF_FULL = "HALF_FULL" NEARLY_EMPTY = "NEARLY_EMPTY" EMPTY = "EMPTY"
In a separate bit of code, I define an RGB colour for each of these states, using a simple dict.
TANK_STATE_COLORS = { TankState.FULL: 0x00FF00, TankState.HALF_FULL: 0x28D728, TankState.NEARLY_EMPTY: 0xFF9900, TankState.EMPTY: 0xFF0000, }
This is deliberately distinct from my TankState code and related definitions, because it relates to a different part of the project - the user interface. The UI concerns shouldn’t be mixed up with the core logic.
This dict is fine, and currently complete. But I’d like to ensure that if I add a new item to TankState, I don’t forget to update the TANK_STATE_COLORS dict.
With a growing ability to do static type checks in Python, some people have asked how we can ensure this using static type checks. The short answer is, we can’t (at least at the moment).
But the better question is “how can we (somehow) ensure we don’t forget?” It doesn’t have to be a static type check, as long as it’s very hard to forget, and if it preferably runs as early as possible.
Instead of shoe-horning everything into static type checks, let’s just make use of the fact that this is Python and we can write any code we want at module level. All we need to do is this:
TANK_STATE_COLORS = { # … } for val in TankState: assert val in TANK_STATE_COLORS, f"TANK_STATE_COLORS is missing an entry for {val}"
That’s it, that’s the whole technique. I’d argue that this is a pretty much optimal, Pythonic solution to the problem. No clever type tricks to debug later, just 2 lines of plain simple code, and it’s impossible to import your code until you fix the problem, which means you get the early checking you want. Plus you get exactly the error message you want, not some obscure compiler output, which is also really important.
It can also be extended if you want to do something more fancy (e.g. allow some values of the enum to be missing), and if it does get in your way, you can turn it off temporarily by just commenting out a couple of lines.
That’s not quite it
OK, in a project where I’m using this a lot, I did eventually get bored of this small bit of boilerplate. So, as a Pythonic extension of this Pythonic solution, I now do this:
TANK_STATE_COLORS: dict[TankState, int] = { TankState.FULL: 0x00FF00, TankState.HALF_FULL: 0x28D728, TankState.NEARLY_EMPTY: 0xFF9900, TankState.EMPTY: 0xFF0000, } assert_complete_enumerations_dict(TANK_STATE_COLORS)
Specifically, I’m adding:
a type hint on the constant
a call to a clever utility function that does just the right amount of Python magic.
This function needs to be “magical” because we want it to produce good error messages, like we had before. This means it needs to get hold of the name of the dict in the calling module, but functions don’t usually have access to that.
In addition, it wants to get hold of the type hint (although there would be other ways to infer it without a type hint, there are advantages this way), for which we also need the name.
The specific magic we need is:
the clever function needs to get hold of the module that called it
it then looks through the module dictionary to get the name of the object that has been passed in
then it can find type hints, and do the checking.
So, because you don’t want to write all that yourself, the code is below. It also supports:
having a tuple of
Enumtypes as the keyallowing some items to be missing
using
Literalas the key. So you can do things like this:
It’s got a ton of error checking, because once you get magical then you really don’t want to be debugging obscure messages.
Enjoy!
import inspect import itertools import sys import typing from collections.abc import Mapping, Sequence from enum import Enum from frozendict import frozendict def assert_complete_enumerations_dict[T](the_dict: Mapping[T, object], *, allowed_missing: Sequence[T] = ()): """ Magically assert that the dict in the calling module has a value for every item in an enumeration. The dict object must be bound to a name in the module. It must be type hinted, with the key being an Enum subclass, or Literal. The key may also be a tuple of Enum subclasses If you expect some values to be missing, pass them in `allowed_missing` """ assert isinstance(the_dict, Mapping), f"{the_dict!r} is not a dict or mapping, it is a {type(the_dict)}" frame_up = sys._getframe(1) # type: ignore[reportPrivateUsage] assert frame_up is not None module = inspect.getmodule(frame_up) assert module is not None, f"Couldn't get module for frame {frame_up}" msg_prefix = f"In module `{module.__name__}`," module_dict = frame_up.f_locals name: str | None = None # Find the object: names = [k for k, val in module_dict.items() if val is the_dict] assert names, f"{msg_prefix} there is no name for {the_dict}, please check" # Any name that has a type hint will do, there will usually be one. hints = typing.get_type_hints(module) hinted_names = [name for name in names if name in hints] assert ( hinted_names ), f"{msg_prefix} no type hints were found for {', '.join(names)}, they are needed to use assert_complete_enumerations_dict" name = hinted_names[0] hint = hints[name] origin = typing.get_origin(hint) assert origin is not None, f"{msg_prefix} type hint for {name} must supply arguments" assert origin in ( dict, typing.Mapping, Mapping, frozendict, ), f"{msg_prefix} type hint for {name} must be dict/frozendict/Mapping with arguments to use assert_complete_enumerations_dict, not {origin}" args = typing.get_args(hint) assert len(args) == 2, f"{msg_prefix} type hint for {name} must have two args" arg0, _ = args arg0_origin = typing.get_origin(arg0) if arg0_origin is tuple: # tuple of Enums enum_list = typing.get_args(arg0) for enum_cls in enum_list: assert issubclass( enum_cls, Enum ), f"{msg_prefix} type hint must be an Enum to use assert_complete_enumerations_dict, not {enum_cls}" items = list(itertools.product(*(list(enum_cls) for enum_cls in enum_list))) elif arg0_origin is typing.Literal: items = typing.get_args(arg0) else: assert issubclass( arg0, Enum ), f"{msg_prefix} type hint must be an Enum to use assert_complete_enumerations_dict, not {arg0}" items = list(arg0) for item in items: if item in allowed_missing: continue # This is the assert we actually want to do, everything else is just error checking: assert item in the_dict, f"{msg_prefix} {name} needs an entry for {item}"
PyPodcats
Episode 9: With Tamara Atanasoska
Learn about Tamara's journey. Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.Learn about Tamara's journey. Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.
We interviewed Tamara Atanasoska.
Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.
She is now a maintainer of Fairlearn, an open-source, community-driven project to help data scientists improve fairness of AI systems.
Hear how Django helps her feel empowered, and how the PyLadies Berlin community has helped her feel welcomed as a new immigrant in Germany.
In this episode, Tamara shares perspective about open source contributions, maintain, mentorship, and her experience in running beginner-friendly sprints.
Be sure to listen to the episode to learn all about Tamara’s inspiring story!
Topic discussed
- Introductions
- Getting to know Tamara
- Her role at :probabl.
- Her role as an open source maintainer for Fairlearn
- What is Fairlearn and discussion about fairness in AI
- The challenges in getting feedback from the users about the Fairlearn project
- How she get started with Python and Django
- Her political participation that led her to contributing to civic engagement open source project during Google Summer of Code
- How Django helps her feel empowered
- Her experience with hacker spaces
- How the Python and PyLadies Berlin community helps her feel welcomed as a new immigrant in Berlin
- How she gives back to the community by speaking, mentoring, and leading sprints
- How she approaches mentorship, and why it is part of her core values.
- Her ideas about leading beginner-friendly sprints
- Her future endeavors
Note
This episode was recorded in March 2025. Tamara is still a software engineer, but no longer works at probabl.
To find out more about what she is currently up to, check her LinkedIn profile.
Links from the show
- Fairlearn: https://fairlearn.org/
- Fairlearn Community Survey: https://docs.google.com/forms/d/e/1FAIpQLSeOTRNgAc2RYnDDO5-GE7scMysPHrBLs8XV21ZP--XATr34aA/viewform
- :probabl.: https://probabl.ai/
- scikit-learn: https://scikit-learn.org/
- e-cidadania GitHub repository: https://github.com/cidadania/e-cidadania
- Google Summer of Code 2012: https://opensource.googleblog.com/2012/05/macedonia-google-summer-of-code-meetups.html
- PyLadies Berlin: https://berlin.pyladies.com/en/
- Tamara’s Substack: https://holophrase.substack.com/
- Tamara’s website: https://tamaraatanasoska.github.io/about/
Django Weblog
Watch the DjangoCon Europe 2025 talks
They’re now all available to watch on YouTube, with a dedicated playlist ⭐️ DjangoCon Europe 2025 Dublin. For more quality Django talks in 2025, check out our next upcoming events!
All the DjangoCon Europe talks
 Welcome Session
Welcome Session
 Keynote: Django needs you! (to do code review)
Keynote: Django needs you! (to do code review)
 End-to-end testing Django applications using Pytest with Playwright
End-to-end testing Django applications using Pytest with Playwright
 Turn back time: Converting integer fields to bigint using Django migrations at scale
Turn back time: Converting integer fields to bigint using Django migrations at scale
 Data-Oriented Django Drei
Data-Oriented Django Drei
 The fine print in Django release notes
The fine print in Django release notes
 Django + HTMX: Patterns to Success
Django + HTMX: Patterns to Success
 How to solve a Python mystery
How to solve a Python mystery
 Bulletproof Data Pipelines: Django, Celery, and the Power of Idempotency
Bulletproof Data Pipelines: Django, Celery, and the Power of Idempotency
 Logs, shells, caches and other strange words we use daily
Logs, shells, caches and other strange words we use daily
 Day 1 Lightning Talks
Day 1 Lightning Talks
 How to Enjoy Debugging in Production
How to Enjoy Debugging in Production
 KEYNOTE: The Most Bizarre Software Bugs in History
KEYNOTE: The Most Bizarre Software Bugs in History
 Passkeys in Django: the best of all possible worlds
Passkeys in Django: the best of all possible worlds
 How we make decisions in Django
How we make decisions in Django
 100 Million Parking Transactions Per Year with Django
100 Million Parking Transactions Per Year with Django
 One more time about µDjango
One more time about µDjango
 Steering Council introduction
Steering Council introduction
 Supporting Adult Career Switchers: The Unbootcamp Method
Supporting Adult Career Switchers: The Unbootcamp Method
 How to get Foreign Keys horribly wrong in Django
How to get Foreign Keys horribly wrong in Django
 Zango: Accelerating Business App Development with an Opinionated Django Meta
Zango: Accelerating Business App Development with an Opinionated Django Meta
 Dynamic models without dynamic models
Dynamic models without dynamic models
 Evolving Django: What We Learned by Integrating MongoDB
Evolving Django: What We Learned by Integrating MongoDB
 Feature Flags: Deploy to some of the people all of the time, and all of the
Feature Flags: Deploy to some of the people all of the time, and all of the
 Day 2 Lightning Talks
Day 2 Lightning Talks
 KEYNOTE: Django for Data Science: Deploying Machine Learning Models with Django
KEYNOTE: Django for Data Science: Deploying Machine Learning Models with Django
 The incredible Djangonaut Space project
The incredible Djangonaut Space project
 Anatomy of a Database Operation
Anatomy of a Database Operation
 One Thousand and One Django Sites
One Thousand and One Django Sites
 Django Admin at Scale: From Milliseconds to Microseconds 🚀
Django Admin at Scale: From Milliseconds to Microseconds 🚀
 Just-in-Time Development with Django and HTMX: Faster, Leaner, and Smarter
Just-in-Time Development with Django and HTMX: Faster, Leaner, and Smarter
 Europe, Django and two-factor authentication
Europe, Django and two-factor authentication
 Closing session
Closing session
 Day 3 Lightning Talks
Day 3 Lightning Talks
June 25, 2025
TestDriven.io
Building a Multi-tenant App with Django
This tutorial looks at how to implement multi-tenancy in Django.
Peter Bengtsson
Native connection pooling in Django 5 with PostgreSQL
Enabling native connection pooling in Django 5 gives me a 5.4x speedup.
Real Python
Your Guide to the Python print() Function
If you’re like most Python users, then you probably started your Python journey by learning about print(). It helped you write your very own “Hello, World!” one-liner and brought your code to life on the screen. Beyond that, you can use it to format messages and even find some bugs. But if you think that’s all there is to know about Python’s print() function, then you’re missing out on a lot!
Keep reading to take full advantage of this seemingly boring and unappreciated little function. This tutorial will get you up to speed with using Python print() effectively. However, be prepared for a deep dive as you go through the sections. You may be surprised by how much print() has to offer!
By the end of this tutorial, you’ll understand that:
- The
print()function can handle multiple arguments and custom separators to format output effectively. - You can redirect
print()output to files or memory buffers using thefileargument, enhancing flexibility. - Mocking
print()in unit tests helps verify code behavior without altering the original function. - Using the
flushargument ensures immediate output, overcoming buffering delays in certain environments. - Thread-safe printing is achievable by implementing locks to prevent output interleaving.
If you’re just getting started with Python, then you’ll benefit most from reading the first part of this tutorial, which illustrates the essentials of printing in Python. Otherwise, feel free to skip ahead and explore the sections that interest you the most.
Get Your Code: Click here to download the free sample code that shows you how to use the print() function in Python.
Take the Quiz: Test your knowledge with our interactive “The Python print() Function” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
The Python print() FunctionIn this quiz, you'll test your understanding of Python's built-in print() function, covering how to format output, specify custom separators, and more.
Printing in a Nutshell
It’s time to jump in by looking at a few real-life examples of printing in Python. By the end of this section, you’ll know every possible way of calling print().
Producing Blank Lines
The simplest example of using Python print() requires just a few keystrokes:
print()
This produces an invisible newline character, which in turn causes a blank line to appear on your screen. To add vertical space, you can call print() multiple times in a row like this:
print()
print()
print()
It’s just as if you were hitting Enter on your keyboard in a word processor program or a text editor.
While you don’t pass any arguments to print(), you still need to put empty parentheses at the end of the line to tell Python to actually execute that function rather than just refer to it by name. Without parentheses, you’d obtain a reference to the underlying function object:
>>> print()
>>> print
<built-in function print>
The code snippet above runs within an interactive Python REPL, as indicated by the prompt (>>>). Because the REPL executes each line of Python code immediately, you see a blank line right after calling print(). On the other hand, when you skip the trailing parentheses, you get to see a string representation of the print() function itself.
As you just saw, calling print() without arguments results in a blank line, which is a line comprised solely of the newline character. Don’t confuse this with an empty string, which doesn’t contain any characters at all, not even the newline!
You can use Python’s string literals to visualize these two:
- Blank Line:
"\n" - Empty String:
""
The first string literal is exactly one character long, whereas the second one has no content—it’s empty.
Note: To remove the newline character from a string in Python, use its .rstrip() method, like this:
>>> "A line of text.\n".rstrip()
'A line of text.'
This strips any trailing whitespace from the right edge of the string of characters. To learn more about .rstrip(), check out the How to Strip Characters From a Python String tutorial.
Even though Python usually takes care of the newline character for you, it helps to understand how to deal with it yourself.
Dealing With Newlines
Read the full article at https://realpython.com/python-print/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Mike Driscoll
An Intro to ty – The Extremely Fast Python type checker
Ty is a brand new, extremely fast Python type checker written in Rust from the fine folks at Astral, the makers of Ruff. Ty is in preview and is not ready for production use, but you can still try it out on your code base to see how it compares to Mypy or other popular Python type checkers.
Getting Started with ty
You can try out ty using the online playground, or run ty with uvx to get started quickly:
uvx ty
If you prefer to install ty, you can use pip:
python -m pip install ty
Astral provides other installation methods as well.
Using the ty Type Checker
Want to give ty a try? You can run it in much the same way as you would Ruff. Open up your terminal and navigate to your project’s top-level directory. Then run the following command:
ty check
If ty finds anything, you will quickly see the output in your terminal.
Astral has also provided a way to exclude files from type checking. By default, ty ignores files listed in an .ignore or .gitignore file.
Adding ty to Your IDE
The Astral team maintains an official VS Code extension for ty. You can get it from the VS Code Marketplace. Their documentation states that other IDEs can also use ty if they support the language server protocol.
Wrapping Up
Ruff is a great tool and has been adopted by many teams since its release. Ty will likely follow a similar trajectory if it as fast and useful as Ruff has been. Only time will tell. However, these new developments in Python tooling are exciting and will be fun to try. If you have used ty, feel free to jump into the comments and let me know what you think.
The post An Intro to ty – The Extremely Fast Python type checker appeared first on Mouse Vs Python.
Real Python
Quiz: The Python print() Function
In this quiz, you’ll test your understanding of Your Guide to the Python print() Function.
The print() function outputs objects to the console or a specified file-like stream. You’ll practice:
- Printing multiple values with custom separators
- Changing the end-of-line character
- Redirecting output using the
fileparameter - Forcing immediate output with the
flushparameter
Work through these questions to reinforce your knowledge of print()’s parameters and best practices for clear, formatted I/O.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyPodcats
Trailer: Episode 9 With Tamara Atanasoska
A preview of our chat with Tamara Atanasoska. Watch the full episode on June 27, 2025A preview of our chat with Tamara Atanasoska. Watch the full episode on June 27, 2025
Sneak Peek of our chat with Tamara Atanasoska, hosted by Georgi Ker and Mariatta Wijaya.
Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.
She is now a maintainer of Fairlearn, an open-source, community-driven project to help data scientists improve fairness of AI systems.
Hear how Django helps her feel empowered, and how the PyLadies Berlin community has helped her feel welcomed as a new immigrant in Germany.
In this episode, Tamara shares perspective about open source contributions, maintain, mentorship, and her experience in running beginner-friendly sprints.
Full episode is coming on June 27, 2025! Subscribe to our podcast now!
Talk Python to Me
#511: From Notebooks to Production Data Science Systems
If you're doing data science and have mostly spent your time doing exploratory or just local development, this could be the episode for you. We are joined by Catherine Nelson to discuss techniques and tools to move your data science game from local notebooks to full-on production workflows.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/agntcy'>Agntcy</a><br> <a href='https://talkpython.fm/sentry'>Sentry Error Monitoring, Code TALKPYTHON</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading">Links from the show</h2> <div><strong>New Course: LLM Building Blocks for Python</strong>: <a href="https://training.talkpython.fm/courses/llm-building-blocks-for-python" target="_blank" >training.talkpython.fm</a><br/> <br/> <strong>Catherine Nelson LinkedIn Profile</strong>: <a href="https://www.linkedin.com/in/catherinenelson1/?featured_on=talkpython" target="_blank" >linkedin.com</a><br/> <strong>Catherine Nelson Bluesky Profile</strong>: <a href="https://bsky.app/profile/catnelson.bsky.social?featured_on=talkpython" target="_blank" >bsky.app</a><br/> <strong>Enter to win the book</strong>: <a href="https://forms.gle/1okKtSdSNTtAd4SRA?featured_on=talkpython" target="_blank" >forms.google.com</a><br/> <strong>Going From Notebooks to Scalable Systems - PyCon US 2025</strong>: <a href="https://us.pycon.org/2025/schedule/presentation/51/?featured_on=talkpython" target="_blank" >us.pycon.org</a><br/> <strong>Going From Notebooks to Scalable Systems - Catherine Nelson – YouTube</strong>: <a href="https://www.youtube.com/watch?v=o4hyA4hotxw&ab_channel=PyConUS" target="_blank" >youtube.com</a><br/> <strong>From Notebooks to Scalable Systems Code Repository</strong>: <a href="https://github.com/catherinenelson1/from_notebooks_to_scalable?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Building Machine Learning Pipelines Book</strong>: <a href="https://www.oreilly.com/library/view/building-machine-learning/9781492053187/?featured_on=talkpython" target="_blank" >oreilly.com</a><br/> <strong>Software Engineering for Data Scientists Book</strong>: <a href="https://www.oreilly.com/library/view/software-engineering-for/9781098136192/?featured_on=talkpython" target="_blank" >oreilly.com</a><br/> <strong>Jupytext - Jupyter Notebooks as Markdown Documents</strong>: <a href="https://github.com/mwouts/jupytext?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Jupyter nbconvert - Notebook Conversion Tool</strong>: <a href="https://github.com/jupyter/nbconvert?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Awesome MLOps - Curated List</strong>: <a href="https://github.com/visenger/awesome-mlops?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=n2WFfVIqlDw" target="_blank" >youtube.com</a><br/> <strong>Episode #511 deep-dive</strong>: <a href="https://talkpython.fm/episodes/show/511/from-notebooks-to-production-data-science-systems#takeaways-anchor" target="_blank" >talkpython.fm/511</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/511/from-notebooks-to-production-data-science-systems" target="_blank" >talkpython.fm</a><br/> <br/> <strong>--- Stay in touch with us ---</strong><br/> <strong>Subscribe to Talk Python on YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" >youtube.com</a><br/> <strong>Talk Python on Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm at bsky.app</a><br/> <strong>Talk Python on Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i>talkpython</a><br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes at bsky.app</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
June 24, 2025
PyCoder’s Weekly
Issue #687: Scaling With Kubernetes, Substrings, Big-O, and More (June 24, 2025)
#687 – JUNE 24, 2025
View in Browser »
Scaling Web Applications With Kubernetes and Karpenter
What goes into scaling a Python web application today? What are resources for learning and practicing DevOps skills? This week on the show, Calvin Hendryx-Parker is back to discuss the tools and infrastructure for autoscaling web applications with Kubernetes and Karpenter.
REAL PYTHON podcast
The Fastest Way to Detect a Vowel in a String
If you need to find the vowels in a string there are several different approaches you could take. This article covers 11 different ways and how each performs.
AUSTIN Z. HENLEY
Prevent Postgres Slowdowns on Python Apps with this Check List

Avoid performance regressions in your Python app by staying on top of Postgres maintenance. This monthly check list outlines what to monitor, how to catch slow queries early, and ways to ensure indexes, autovacuum, and I/O are performing as expected →
PGANALYZE sponsor
O(no) You Didn’t
A deep dive into why real-world performance often defies Big-O expectations and why context and profiling matter more than theoretical complexity
MRSHINY608
Discussions
Python Jobs
Sr. Software Developer (Python, Healthcare) (USA)
Articles & Tutorials
The PSF’s 2024 Annual Impact Report Is Here!
The Python Software Foundation releases a report every year on the state of the PSF and our community. This year’s report gives a run down of the successes of the language, key highlights of PyCon US, updates from the developers in residence, and more.
PYTHON SOFTWARE FOUNDATION
Are Python Dictionaries Ordered Data Structures?
Although dictionaries have maintained insertion order since Python 3.6, they aren’t strictly speaking ordered data structures. Read on to find out why and how the edge cases can be important depending on your use case.
STEPHEN GRUPPETTA
10 Polars Tools and Techniques to Level Up Your Data Science
Are you using Polars for your data science work? There are many libraries out there that might help you write less code. Talk Python interviews Christopher Trudeau and they talk about the Polars ecosystem.
KENNEDY & TRUDEAU podcast
Cut Django DB Latency With Native Connection Pooling
“Deploy Django 5.1’s native connection pooling in 10 minutes to cut database latency by 50-70ms, reduce connection overhead by 60-80%, and improve response times by 10-30% with zero external dependencies.”
SAURABH KUMAR
Will AI Replace Junior Developers?
At PyCon US this year, Adarsh chatted with various Python folks about one big question: will AI replace junior developers? He spoke with Guido van Rossum, Anthony Shaw, Simon Willison, and others.
ADARSH DIVAKARAN • Shared by Adarsh Divakaran
PEP 779: Free-Threaded Python (Accepted)
Free-threaded Python has been upgraded from experimental to part of the supported build. This quick quote from a longer discussion covers exactly what that means.
SIMON WILSON
PSF Board Election Schedule
It is time for the Python Software Foundation Board elections. Nominations are due by July 29th. See the article for the full election schedule and deadlines.
PYTHON SOFTWARE FOUNDATION
Exploring Python’s list Data Type With Examples
In this video course, you’ll dive deep into Python’s lists: how to create them, update their content, populate and grow them - with practical code examples.
REAL PYTHON course
Write Pythonic and Clean Code With namedtuple
Discover how Python’s namedtuple lets you create simple, readable data structures with named fields you can access using dot notation.
REAL PYTHON
Execute Your Python Scripts With a Shebang
In this video course, you’ll learn when and how to use the shebang line in your Python scripts to execute them from a Unix-like shell.
REAL PYTHON course
All About the TypedDict
Are you fan of type hinting in Python? Learn how to add typing to a dictionary with different types of keys.
MIKE DRISCOLL
Projects & Code
Events
Weekly Real Python Office Hours Q&A (Virtual)
June 25, 2025
REALPYTHON.COM
PyCamp Leipzig 2025
June 28 to June 30, 2025
BARCAMPS.EU
Launching Python Katsina Community
June 28 to June 29, 2025
PYTHONKATSINA.ORG
PyDelhi User Group Meetup
June 28, 2025
MEETUP.COM
Workshop: Creating Python Communities
June 29 to June 30, 2025
PYTHON-GM.ORG
PyCon Colombia 2025
July 4 to July 7, 2025
PYCON.CO
Happy Pythoning!
This was PyCoder’s Weekly Issue #687.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Real Python
Starting With DuckDB and Python
The DuckDB database provides a seamless way to handle large datasets in Python with Online Analytical Processing (OLAP) optimization. You can create databases, verify data imports, and perform efficient data queries using both SQL and DuckDB’s Python API.
By the end of this video course, you’ll understand that:
- You can create a DuckDB database by reading data from files like Parquet, CSV, or JSON and saving it to a table.
- You query a DuckDB database using standard SQL syntax within Python by executing queries through a DuckDB connection object.
- You can also use DuckDB’s Python API, which uses method chaining for an object-oriented approach to database queries.
- Concurrent access in DuckDB allows multiple reads but restricts concurrent writes to ensure data integrity.
- DuckDB integrates with pandas and Polars by converting query results into DataFrames using the
.df()or.pl()methods.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
June 23, 2025
Real Python
Python enumerate(): Simplify Loops That Need Counters
Python’s enumerate() function helps you with loops that require a counter by adding an index to each item in an iterable. This is particularly useful when you need both the index and value while iterating, such as listing items with their positions. You can also customize the starting index with the start argument, offering flexibility in various scenarios.
By the end of this tutorial, you’ll understand that:
enumerate()in Python adds a counter to an iterable and returns it as anenumerateobject, pairing each item with an index.enumerate()accepts an iterable and an optionalstartargument to set the initial index value.- The advantage of
enumerate()is that it provides both index and value pairs without manual counter management. - You can use
zip()or slicing as alternatives toenumerate()for iterating multiple sequences or selecting specific elements.
Explore how to implement your own version of enumerate() and discover alternative methods like zip() and itertools for more complex iteration patterns.
Get Your Code: Click here to download the free sample code you’ll use to explore how enumerate() works in Python.
Using Python’s enumerate()
There are situations when you need both the index and the value of items in an iterable. That’s when Python’s enumerate() function can come in handy for you.
Python’s enumerate() function adds a counter to an iterable and returns it in the form of an enumerate object, which can be used directly in loops. For example, when you want to display the winners of a race, you might write:
>>> runners = ["Lenka", "Martina", "Gugu"]
>>> for winner in enumerate(runners):
... print(winner)
...
(0, 'Lenka')
(1, 'Martina')
(2, 'Gugu')
Since enumerate() is a built-in function, you can use it right away without importing it. When you use enumerate() in a for loop, you get pairs of count and value from the iterable.
Note: If you’re coming from languages like C, Java, or JavaScript, you might be tempted to use range(len()) to get both the index and value in a loop. While this works in Python, enumerate() is considered a more Pythonic and preferred approach.
In the example above, you’re storing the position and the runner’s name in a variable named winner, which is a tuple. To display the position and the name right away, you can unpack the tuple when you define the for loop:
>>> runners = ["Lenka", "Martina", "Gugu"]
>>> for position, name in enumerate(runners):
... print(position, name)
...
0 Lenka
1 Martina
2 Gugu
Just like the winner variable earlier, you can name the unpacked loop variables whatever you want. You use position and name in this example, but they could just as easily be named i and value, or any other valid Python names.
When you use enumerate() in a for loop, you typically tell Python to use two variables: one for the count and one for the value itself. You’re able to do this by applying a Python concept called tuple unpacking.
Unpacking is the idea that a tuple—or another type of a Python sequence—can be split into several variables depending on the length of that sequence. For instance, you can unpack a tuple of two elements into two variables:
>>> cart_item = ("Wireless Mouse", 2)
>>> product_name, quantity_ordered = cart_item
>>> product_name
'Wireless Mouse'
>>> quantity_ordered
2
First, you create a tuple with two elements, "Wireless Mouse" and 2. Then, you unpack that tuple into product_name and quantity_ordered, which are each assigned one of the values from the tuple.
When you call enumerate() and pass a sequence of values, Python returns an iterator. When you ask the iterator for its next value, it yields a tuple with two elements. The first element of the tuple is the count, and the second element is the value from the sequence that you passed:
>>> values = ["first", "second"]
>>> enumerate_instance = enumerate(values)
>>> print(enumerate_instance)
<enumerate at 0x7fe75d728180>
>>> next(enumerate_instance)
(0, 'first')
>>> next(enumerate_instance)
(1, 'second')
>>> next(enumerate_instance)
Traceback (most recent call last):
File "<python-input-5>", line 1, in <module>
next(enumerate_instance)
~~~~^^^^^^^^^^^^^^^
StopIteration
In this example, you create a Python list called values with two elements, "first" and "second". Then, you pass values to enumerate() and assign the return value to enumerate_instance. When you print enumerate_instance, you’ll see that it’s an enumerate object with a particular memory address.
Then, you use Python’s built-in next() to get the next value from enumerate_instance. The first value that enumerate_instance returns is a tuple with the count 0 and the first element from values, which is "first".
Calling next() again on enumerate_instance yields another tuple—this time, with the count 1 and the second element from values, "second". Finally, calling next() one more time raises a StopIteration exception since there are no more values to be returned from enumerate_instance.
When an iterable is used in a for loop, Python automatically calls next() at the start of every iteration until StopIteration is raised. Python assigns the value it retrieves from the iterable to the loop variable.
By default, the count of enumerate() starts at 0. This isn’t ideal when you want to display the winners of a race. Luckily, Python’s enumerate() has one additional argument that you can use to control the starting value of the count.
When you call enumerate(), you can use the start argument to change the starting count:
>>> runners = ["Lenka", "Martina", "Gugu"]
>>> for position, name in enumerate(runners, start=1):
... print(position, name)
...
1 Lenka
2 Martina
3 Gugu
In this example, you pass start=1, which initializes position with the value 1 on the first loop iteration.
You should use enumerate() anytime you need to use the count and an item in a loop. Keep in mind that enumerate() increments the count by one on every iteration. However, this only slightly limits your flexibility. Since the count is a standard Python integer, you can use it in many ways.
Practicing With Python enumerate()
Now that you’ve explored the basics of enumerate(), it’s time to practice using enumerate() with some real-world examples.
Read the full article at https://realpython.com/python-enumerate/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]