
Planet Python
Last update: September 20, 2025 01:48 AM UTC
September 19, 2025
Data School
Book preview: Master Machine Learning with scikit-learn 📖

Last week, I posted this announcement on LinkedIn and Bluesky and X:
Dream unlocked: I&aposm publishing my first book! 🎉🎉🎉
— Kevin Markham (@justmarkham) September 11, 2025
It&aposs called "Master Machine Learning with scikit-learn: A Practical Guide to Building Better Models with Python"
Download the first 3 chapters right now:
👉 https://t.co/XojPPFaTns 👈
Thanks for your support 🙏 pic.twitter.com/U9QH0QrZBY
Reactions to the book have been excellent:
I thoroughly enjoyed the first three chapters, Kevin. Easy to read and refreshingly practical.
I fully intend to buy the book.
Thank you
— Andrew Lawrence (@altimeuk.bsky.social) September 13, 2025 at 7:39 AM
This has been a dream of mine for many years, and I&aposm so excited to get it into your hands! 🙌
The book is 99% complete, with the exception of the cover (which will look much nicer than what is shown in the video).
It&aposs titled Master Machine Learning with scikit-learn, and is an adaptation of the course of the same name that I meticulously developed over a span of 4 years (and released last year).
I’ve been teaching Machine Learning in the classroom and online for more than 10 years, and this book is a compilation of nearly everything I know about effective Machine Learning with scikit-learn!
My sincere hope is that it will help to transform you from a Machine Learning novice to a skilled Machine Learning practitioner.
You can download the first 3 chapters right now:
If you enter your email address above, I&aposll keep you updated as the book gets closer to launch! 🚀
In the meantime, please comment on LinkedIn or share this landing page with a friend if you want to help spread the word. 📢
Thank you!
September 19, 2025 04:56 PM UTC
Real Python
The Real Python Podcast – Episode #266: Dangers of Automatically Converting a REST API to MCP
When converting an existing REST API to the Model Context Protocol, what should you consider? What anti-patterns should you avoid to keep an AI agent’s context clean? This week on the show, Kyle Stratis returns to discuss his upcoming book, "AI Agents with MCP".
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 19, 2025 12:00 PM UTC
Go Deh
From all truths to (ir)relevancies

Following up on my previous post about truth tables, I now ask a subtler question: which inputs actually matter? Some variables, though present, leave no trace on the output. In this post, I uncover those quiet bits — the irrelevant inputs — and learn how to spot them with precision.
Building on the previous
The previous post showed that for a given number of inputs, there is a finite, but rapidly growing, number of possible truth tables. For two inputs, there are 16. For three inputs, there are 256. This leads to a powerful idea: we can create a standardized format for all truth tables and uniquely identify the parts in each one.
The Standardized Truth Table (STT) Format
i[1] i[0] : r
=================
0 0 : 0
0 1 : 0
1 0 : 0
1 1 : 1
Colour Key
- Inputs
- Input count
- Result, r
- Result vector: 0001
We have a standardized truth table with i inputs. Each row in the inputs section of the truth table is an increasing binary count from 0 to 2**i−1. The result column for the truth table has 2**i rows, leading to 2**(2**i) different possible truth table result vectors for i inputs.
Any one possible result, r, of the standardized truth table is read as the binary bits of the output going from the topmost row (where the inputs are all zero) down to the bottom-most row, in order. This single binary number, the "result number" or vector, uniquely identifies the truth table and the boolean function it represents.
Irrelevant Variables in Boolean Expressions
A variable in a boolean expression is considered irrelevant if its value has no effect on the final output. In a truth table, this means that changing the value of that input variable while all other inputs remain the same does not change the output.
While this is easy to understand, it can be difficult to spot for complex functions. This is where the standardized truth table format, STT, comes in handy.
Irrelevancy Calculation
For an i-input truth table with a 2**2**i bit result, r, we can efficiently check for irrelevant variables. The key insight is that for any single input variable, say i[n], the other input bits change in the exact same order when i[n]=0 as they do when i[n]=1, in the input count region of the STT.
Therefore, if the result bits for the rows where i[n]=0 are the same as the result bits for the rows where i[n]=1, then the input variable i[n] has no effect on the output and is therefore irrelevant.
Let's illustrate with an example for a 3-input truth table.
Example
| i[2] | i[1] | i[0] | : | Output |
|---|---|---|---|---|
| 0 | 0 | 0 | : | r0 |
| 0 | 0 | 1 | : | r1 |
| 0 | 1 | 0 | : | r2 |
| 0 | 1 | 1 | : | r3 |
| 1 | 0 | 0 | : | r4 |
| 1 | 0 | 1 | : | r5 |
| 1 | 1 | 0 | : | r6 |
| 1 | 1 | 1 | : | r7 |
Consider checking if i[1] is irrelevant. The values of the other inputs (i[2] and i[0]) follow the sequence 00, 01, 10, 11 both when i[1] is 0 and when i[1] is 1.
When i[1]=0, the corresponding output bits are r0,r1,r4,r5.
When i[1]=1, the corresponding output bits are r2,r3,r6,r7.
If the sequence of bits (r0,r1,r4,r5) is identical to the sequence of bits (r2,r3,r6,r7), then the input variable i[1] has no effect on the output and is therefore irrelevant.
This method allows for a very efficient, algorithmic approach to simplifying boolean expressions.
Relevant and irrelevant result vectors for STT's
I am interested in the truthtables/boolean expressions of an increasing number of inputs. Previously I was taking all the zero input STT, then all the 1-input, all the 2-input, ...
That had repetitions and irrelevancies. I can now take just the relevant result vectors for each case, or, take the maximum inputs I can handle and sort the result vectors so that those with the most irrelevancies for that maximum number of inputs, come first.
Here's the code I used to investigate these properties of irrelevances:
Irrelevances: Output
OEIS
The sequence of relevances: 2, 2, 10, 218, 64594 is already present as A000371 on OEIS.
The sequences of irelevances: 0, 2, 6, 38, 942 had no exact match although A005530 came close
END.
September 19, 2025 07:28 AM UTC
September 18, 2025
Real Python
Quiz: Ways to Start Interacting With Python
Want to revisit different ways to run Python code interactively? In this quiz, you’ll review concepts such as using the REPL, executing scripts, and working within IDEs.
Before starting, make sure you’ve gone through the Ways to Start Interacting With Python course to get the most from these questions.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 18, 2025 12:00 PM UTC
Python Insider
Python 3.14.0rc3 is go!
It’s 🪄 finally 🪄 the final 3.14 release candidate!
https://www.python.org/downloads/release/python-3140rc3/
Note: It’s another magic release. We fixed another
bug that required bumping the magic number stored in Python bytecode
(.pyc) files. This means file .pyc files
created for rc2 cannot be used for rc3, and they’ll be
recompiled.
The ABI isn’t changing. Wheels built for rc1 should be fine for rc2, rc3 and 3.14.x, so this shouldn’t affect too many people.
This release, 3.14.0rc3, is the final release preview. Entering the release candidate phase, only reviewed code changes which are clear bug fixes are allowed between this release candidate and the final release.
The next release of Python 3.14 will be the final release, 3.14.0, scheduled for Tuesday, 2025-10-07.
There will be no ABI changes from this point forward in the 3.14 series, and the goal is that there will be as few code changes as possible.
Call to action
We strongly encourage maintainers of third-party Python projects to prepare their projects for 3.14 during this phase, and publish Python 3.14 wheels on PyPI to be ready for the final release of 3.14.0, and to help other projects do their own testing. Any binary wheels built against Python 3.14.0 release candidates will work with future versions of Python 3.14. As always, report any issues to the Python bug tracker.
Please keep in mind that this is a preview release and while it’s as close to the final release as we can get it, its use is not recommended for production environments.
Core developers: time to work on documentation now
- Are all your changes properly documented?
- Are they mentioned in What’s New?
- Did you notice other changes you know of to have insufficient documentation?
Major new features of the 3.14 series, compared to 3.13
Some of the major new features and changes in Python 3.14 are:
New features
- PEP 779: Free-threaded Python is officially supported
- PEP 649: The evaluation of annotations is now deferred, improving the semantics of using annotations.
- PEP 750: Template string literals (t-strings) for custom string processing, using the familiar syntax of f-strings.
- PEP 734: Multiple interpreters in the stdlib.
- PEP
784: A new module
compression.zstdproviding support for the Zstandard compression algorithm. - PEP
758:
exceptandexcept*expressions may now omit the brackets. - Syntax highlighting in PyREPL, and support for color in unittest, argparse, json and calendar CLIs.
- PEP 768: A zero-overhead external debugger interface for CPython.
- UUID
versions 6-8 are now supported by the
uuidmodule, and generation of versions 3-5 are up to 40% faster. - PEP
765: Disallow
return/break/continuethat exit afinallyblock. - PEP 741: An improved C API for configuring Python.
- A new type of interpreter. For certain newer compilers, this interpreter provides significantly better performance. Opt-in for now, requires building from source.
- Improved error messages.
- Builtin implementation of HMAC with formally verified code from the HACL* project.
- A new command-line interface to inspect running Python processes using asynchronous tasks.
- The pdb module now supports remote attaching to a running Python process.
(Hey, fellow core developer, if a feature you find important is missing from this list, let Hugo know.)
For more details on the changes to Python 3.14, see What’s new in Python 3.14.
Build changes
- PEP 761: Python 3.14 and onwards no longer provides PGP signatures for release artifacts. Instead, Sigstore is recommended for verifiers.
- Official macOS and Windows release binaries include an experimental JIT compiler.
- Official Android binary releases are now available.
Incompatible changes, removals and new deprecations
- Incompatible changes
- Python removals and deprecations
- C API removals and deprecations
- Overview of all pending deprecations
Python install manager
The installer we offer for Windows is being replaced by our new install manager, which can be installed from the Windows Store or from its download page. See our documentation for more information. The JSON file available for download below contains the list of all the installable packages available as part of this release, including file URLs and hashes, but is not required to install the latest release. The traditional installer will remain available throughout the 3.14 and 3.15 releases.
More resources
- Online documentation
- PEP 745, 3.14 Release Schedule
- Report bugs at github.com/python/cpython/issues
- Help fund Python and its community
And now for something completely different
According to Pablo Galindo Salgado at PyCon Greece:
There are things that are supercool indeed, like for instance, this is one of the results that I’m more proud about. This equation over here, which you don’t need to understand, you don’t need to be scared about, but this equation here tells what is the maximum time that it takes for a ray of light to fall into a black hole. And as you can see the math is quite complicated but the answer is quite simple: it’s 2π times the mass of the black hole. So if you normalise by the mass of the black hole, the answer is 2π. And because there is nothing specific about your election of things in this formula, this formula is universal. It means it doesn’t depend on anything other than nature itself. Which means that you can use this as a definition of π. This is a valid alternative definition of the number π. It’s literally half the maximum time it takes to fall into a black hole, which is kind of crazy. So next time someone asks you what π means you can just drop this thing and impress them quite a lot. Maybe Hugo could use this information to put it into the release notes of πthon [yes, I can, thank you!].
Enjoy the new release
Thanks to all of the many volunteers who help make Python Development and these releases possible! Please consider supporting our efforts by volunteering yourself or through organisation contributions to the Python Software Foundation.
Regards from wonderful Cambridge,
Your release team,
Hugo van Kemenade @hugovk
Ned Deily @nad
Steve Dower @steve.dower
Łukasz Langa @ambv
September 18, 2025 08:06 AM UTC
Talk Python to Me
#519: Data Science Cloud Lessons at Scale
Today on Talk Python: What really happens when your data work outgrows your laptop. Matthew Rocklin, creator of Dask and cofounder of Coiled, and Nat Tabris a staff software engineer at Coiled join me to unpack the messy truth of cloud-scale Python. During the episode we actually spin up a 1,000 core cluster from a notebook, twice! We also discuss picking between pandas and Polars, when GPUs help, and how to avoid surprise bills. Real lessons, real tradeoffs, shared by people who have built this stuff. Stick around.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/seer'>Seer: AI Debugging, Code TALKPYTHON</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading">Links from the show</h2> <div><strong>Matthew Rocklin</strong>: <a href="https://x.com/mrocklin?featured_on=talkpython" target="_blank" >@mrocklin</a><br/> <strong>Nat Tabris</strong>: <a href="https://tabris.us?featured_on=talkpython" target="_blank" >tabris.us</a><br/> <br/> <strong>Dask</strong>: <a href="https://www.dask.org?featured_on=talkpython" target="_blank" >dask.org</a><br/> <strong>Coiled</strong>: <a href="https://coiled.io?featured_on=talkpython" target="_blank" >coiled.io</a><br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=omBibVGLzyo" target="_blank" >youtube.com</a><br/> <strong>Episode #519 deep-dive</strong>: <a href="https://talkpython.fm/episodes/show/519/data-science-cloud-lessons-at-scale#takeaways-anchor" target="_blank" >talkpython.fm/519</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/519/data-science-cloud-lessons-at-scale" target="_blank" >talkpython.fm</a><br/> <strong>Developer Rap Theme Song: Served in a Flask</strong>: <a href="https://talkpython.fm/flasksong" target="_blank" >talkpython.fm/flasksong</a><br/> <br/> <strong>--- Stay in touch with us ---</strong><br/> <strong>Subscribe to Talk Python on YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" >youtube.com</a><br/> <strong>Talk Python on Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm at bsky.app</a><br/> <strong>Talk Python on Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i>talkpython</a><br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes at bsky.app</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
September 18, 2025 08:00 AM UTC
September 17, 2025
Mirek Długosz
Found on web: Commoncog
Commoncog by Cedric Chin is probably the most influential resource I’ve discovered on the Internet in the last couple of years. It’s deep. It’s grounded. It’s deliberate. It’s insightful. It’s judicious. It’s nuanced. It’s well written. It’s practical. If I were stranded on a desert island and could only receive updates from five websites, Commoncog would be one of them. It’s that good.
Consider the series on putting mental models to practice. There’s a very compelling argument for limits of scientific knowledge from practical point of view in part two; and right away other types of knowledge are proposed to fill the gap. Some of them are collectively called Naturalistic Decision Making models, elaborated on in part four. Part five is a real treasure - it provides detailed, actionable advice on developing proficiency in expertise-driven decision making. The whole series gives both theoretical framework and practical guidance with a proven track record.
These themes are then echoed in The Secret at the Heart of Continuous Improvement, which covers Plan-Do-Study-Act model - something that you might have heard about before. Nonetheless, Cedric manages to really nail down the importance of how the stages support one another, and the entire model as a whole. He then delivers a knockout punch with revolutionary framing - PDSA provides a methodology for single subject studies. It’s the ultimate tool for finding and refining what works for you.
There’s also entire series on Cognitive Flexibility Theory, which tries to uncover how people are learning in ill-structured domains - and provides tools to accelerate that learning. One of them is case library, which is explained in depth in How Note Taking Can Help You Become an Expert. It acknowledges the messiness of the real world and builds on the insight that experts are pattern-matching novel situations against all the cases they experienced or heard of, identifying similarities and differences. Becoming an expert is largely about growing this body of cases you can reference.
I’m truly captivated by these ideas. Where I stand right now, I believe that one of the most beneficial learning resources for testers is building a shared case library. I’ve been modestly contributing to that in this very blog. If this is something you would be interested in and would like to work on together, just send me a message.
Meanwhile, be sure to check out existing Commoncog article base and subscribe to their newsletter or RSS feed.
September 17, 2025 04:24 PM UTC
Real Python
Python 3.14 Preview: REPL Autocompletion and Highlighting
Python 3.14 introduces improvements to its interactive shell (REPL), bringing a more modern, colorful, and user-friendly environment. The new features make the Python 3.14 REPL a powerful tool for experimentation. Whether you’re testing a quick idea, exploring a new library, or debugging a tricky snippet, the REPL gives you instant feedback—no files, no setup, just type and run.
The default CPython REPL intentionally kept things minimal. It was fast, reliable, and available everywhere, but it lacked the richer, more ergonomic features found in tools like IPython or ptpython. That began to change in Python 3.13, when CPython adopted a modern PyREPL-based shell by default, adding multiline editing, better history navigation, and smarter Tab completion.
By the end of this tutorial, you’ll understand that:
- In Python 3.14’s REPL, autocompletion is on by default. You just need to press Tab in the context of an
importstatement to see possible completion suggestions. - The REPL highlights Python syntax in real time if your terminal supports ANSI colors.
- Python 3.14 allows you to customize the color theme with the
_colorize.set_theme()experimental API and thePYTHONSTARTUPscript. - You can disable the syntax highlighting by setting
NO_COLOR=1orPYTHON_COLORS=0in your environment.
Autocompleting module names during import statements makes interactive coding smoother and faster, especially for learning or exploratory tasks. In addition, the colored syntax in the REPL improves readability, making it easier to spot typos and syntax issues.
Get Your Code: Click here to download the free sample code that you’ll use to learn about REPL autocompletion and highlighting in Python 3.14.
Take the Quiz: Test your knowledge with our interactive “Python 3.14 Preview: REPL Autocompletion and Highlighting” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Python 3.14 Preview: REPL Autocompletion and HighlightingTake this quiz to explore Python 3.14's REPL upgrades! Test your knowledge of new autocompletion tools and built-in syntax highlighting.
The Interactive REPL Before Python 3.14
When you first install Python, one of the most immediate ways to try it out is through the interactive REPL (Read–Eval–Print Loop) in your command line or terminal. The REPL is a shell that lets you type Python code, run it instantly, and see the result. It’s a quick-start environment perfect for experimentation, learning, and debugging without the overhead of creating and running separate scripts.
For years, the default CPython REPL kept things lightweight and fairly minimal, with very few features. In contrast, tools like IPython, bpython, and ptpython have offered richer interactive experiences.
This landscape has been changing lately. Starting in Python 3.13, the default REPL is based on PyPy’s pyrepl, which is written in Python and designed for extensibility and safety. It’s also a more capable interactive shell with a modern set of features:
- Color by default: Take advantage of colorized prompts and tracebacks. You can also control this behavior with the
PYTHON_COLORSorNO_COLORenvironment variables. - Quick REPL commands: Use
exit,quit,help, andclearas commands rather than function calls with parentheses. - Built‑in help browser: Press F1 to open a help viewer in your pager so you can browse docs for Python, modules, and objects.
- Persistent history browser: Press F2 to open your command history in a pager and keep it across sessions so you can copy and reuse code.
- Multiline editing: Edit and rerun entire code blocks—functions, classes, loops—as a single unit. The block structure is preserved in your history.
- Robust pasting and paste mode: Paste whole scripts or larger code blocks reliably by default. Optionally, you can access paste mode with F3, although direct pasting usually works without issue.
- Smarter Tab completion: Completions update as you type and hide irrelevant suggestions to reduce noise.
In Python 3.14, the REPL has taken another leap forward by including the following improvements:
- Extended autocompletion that now covers module and submodule names in
importstatements - Live syntax highlighting that makes your interactive code as readable as in your favorite code editor or IDE
You don’t need to perform any extra installation or configuration to start using these new features as long as your terminal supports ANSI color output.
In the sections ahead, you’ll explore what these improvements look like in practice, learn how to use them in your workflow, and pick up some troubleshooting tips for when things don’t behave quite as expected.
Autocompletion Improvements
Python 3.14 extends the autocompletion logic to recognize import contexts and suggest module or package names accordingly. Now, when you type an import or from ... import statement and press Tab, the REPL will search the import path for available module names matching the partial text.
For example, if you type import and then press Tab twice, you’ll get the complete list of currently available modules and packages. If you start typing a module’s name like pat and press Tab, the REPL will automatically complete the pathlib name because it matches uniquely with the partial text.
Read the full article at https://realpython.com/python-repl-autocompletion-highlighting/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 17, 2025 02:00 PM UTC
Quiz: Python 3.14 Preview: REPL Autocompletion and Highlighting
In this quiz, you’ll test your understanding of Python 3.14 Preview: REPL Autocompletion and Highlighting.
With these skills, you’ll be able to take advantage of smarter autocompletion in import statements, real-time syntax highlighting, and even customize or disable the colors to fit your workflow.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 17, 2025 12:00 PM UTC
Django Weblog
Django 6.0 alpha 1 released
Django 6.0 alpha 1 is now available. It represents the first stage in the 6.0 release cycle and is an opportunity to try out the changes coming in Django 6.0.
Django 6.0 assembles a mosaic of modern tools and thoughtful design, which you can read about in the in-development 6.0 release notes.
This alpha milestone marks the feature freeze. The current release schedule calls for a beta release in about a month and a release candidate roughly a month after that. We'll only be able to keep this schedule with early and frequent testing from the community. Updates on the release schedule are available on the Django forum.
As with all alpha and beta packages, this release is not for production use. However, if you'd like to take some of the new features for a spin, or help find and fix bugs (which should be reported to the issue tracker), you can grab a copy of the alpha package from our downloads page or on PyPI.
The PGP key ID used for this release is Natalia Bidart: 2EE82A8D9470983E
September 17, 2025 11:00 AM UTC
Python Morsels
Nested list comprehensions
Nested list comprehensions in Python can look complex, but with thoughtful whitespace, they can be pretty readable!

Table of contents
Nested list comprehensions
Here's a nested list comprehension:
>>> scores_by_group = [[85, 92, 78], [91, 88, 95], [77, 82, 90]]
>>> percentages = [[score/100 for score in group_scores] for group_scores in scores_by_group]
This is a list comprehension with another list comprehension inside its mapping part.
List comprehensions create a new list, and since we've embedded a comprehension within a comprehension, this code creates a list-of-lists:
>>> percentages
[[0.85, 0.92, 0.78], [0.91, 0.88, 0.95], [0.77, 0.82, 0.9]]
I don't find this code very readable:
>>> percentages = [[score/100 for score in group_scores] for group_scores in scores_by_group]
But I don't think the comprehensions are the problem here. The problem is our use of whitespace.
Here's the same code broken up over multiple lines:
>>> percentages = [
... [score/100 for score in group_scores]
... for group_scores in scores_by_group
... ]
>>> percentages
[[0.85, 0.92, 0.78], [0.91, 0.88, 0.95], [0.77, 0.82, 0.9]]
I find this code much more readable.
But is it more or less readable than an equivalent for loop would be?
Nested for loops
Here's the same code without …
Read the full article: https://www.pythonmorsels.com/nested-list-comprehensions/
September 17, 2025 02:52 AM UTC
Stéphane Wirtel
How about checking out the upcoming interesting conferences?
Here are the upcoming conferences that interest me.
-
Odoo Experience 2025: I think I’ll go tomorrow, it’s been a long time since I last attended. The last time I was part of the team was back in 2014, when I posted a picture of myself as an Odoo Warrior ;-). And I went back in 2015 just to say hello to my former colleagues. I often think about my old coding buddies, and I’ll try to visit them tomorrow.
September 17, 2025 12:00 AM UTC
September 16, 2025
PyCoder’s Weekly
Issue #700: Special Issue #700! (Sept. 16, 2025)
#700 – SEPTEMBER 16, 2025
View in Browser »

Nope, you’re not seeing double, this is the second delivery of PyCoder’s this week. In celebration of our 700th issue we’re sending you a little extra Python goodness.
We’re so glad to have you all as readers and to be part of the vibrant Python community. As always, we’re looking for content, so if you see something you think should be shared, send it to us.
We’d also like to thank our sponsor CodeRabbit for making the extra issue possible!
Happy Pythoning!
— The PyCoder’s Weekly Team
Christopher Trudeau, Curator
Dan Bader, Editor
CodeRabbit: Free AI Code Reviews in CLI
CodeRabbit CLI gives instant code reviews in your terminal. It plugs into any AI coding CLI and catches bugs, security issues, and AI hallucinations before they reach your codebase.
CODERABBIT sponsor
Sprints Are the Best Part of a Conference
This post talks about just what happens at a PyCon sprint and why you might want to join the next one. Last year 370 new PRs were opened at PyCon US and almost another 300 got merged into the code.
PYTHON SOFTWARE FOUNDATION
Rate Limiting for Django Websites
Traffic spikes on your site can consume a lot of resources, making it unusable for legitimate users. This post shows you how to use Nginx’s rate limiting capabilities with your Django project.
AIDAS BENDORAITIS
SCREAM CIPHER (“ǠĂȦẶAẦ ĂǍÄẴẶȦ”)
Seth discovered that there are more accented Latin A characters than letters in the 26 letters in the Roman alphabet. So what’s a guy to do but create a cipher?
SETH LARSON
What Does -> Mean in Python Function Definitions?
Wondering what the arrow notation means in Python? Discover how -> is used in type hints, functions, and more with simple explanations and examples.
REAL PYTHON
Go From Zero to Confident Python in 8 Weeks
Get a clear, day-by-day plan, hands-on exercises, and instructor-led sessions that connect the core pieces of Python. Each week blends concise lessons with coding exercises, live Q&As, and a mini-project to cement core ideas. The final capstone demonstrates you can design and implement a complete program. See the week-by-week curriculum →
REAL PYTHON sponsor
The Peril of Unquoted Arguments
Exploring the dangerous power of unquoted Python strings, and how they caused CVE-2024-9287
SUBSTACK.COM • Shared by Vivis Dev
Quiz: Python Project Management With uv
Test your skills with uv, the fast Python project manager. Practice setup, package installs, and key files created by uv.
REAL PYTHON
Projects & Code
Events
PyCon UK 2025
September 19 to September 23, 2025
PYCONUK.ORG
PyCon Ghana 2025
September 25 to September 28, 2025
PYCON.ORG
PyCon JP 2025
September 26 to September 28, 2025
PYCON.JP
PyBeach 2025
September 27 to September 28, 2025
PYBEACH.ORG
Happy Pythoning!
This was PyCoder’s Weekly Issue #700.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
September 16, 2025 07:30 PM UTC
Real Python
Python Project Management With uv
The uv tool is a high-speed package and project manager for Python. It’s written in Rust and designed to streamline your workflow. It offers fast dependency installation and integrates various functionalities into a single tool.
With uv, you can install and manage multiple Python versions, create virtual environments, efficiently handle project dependencies, reproduce working environments, and even build and publish a project. These capabilities make uv an all-in-one tool for Python project management.
By the end of this video course, you’ll understand that:
uvis a Python package and project manager that integrates multiple functionalities into one tool, offering a comprehensive solution for managing Python projects.uvis used for fast dependency installation, virtual environment management, Python version management, and project initialization, enhancing productivity and efficiency.uvcan build and publish Python packages to package repositories like PyPI, supporting a streamlined process from development to distribution.uvautomatically handles virtual environments, creating and managing them as needed to ensure clean and isolated project dependencies.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 16, 2025 02:00 PM UTC
Python Software Foundation
Announcing the 2025 PSF Board Election Results!
The 2025 election for the PSF Board created an opportunity for conversations about the PSF's work to serve the global Python community. We appreciate community members' perspectives, passion, and engagement in the election process this year.
We want to send a big thanks to everyone who ran and was willing to serve on the PSF Board. Even if you were not elected, we appreciate all the time and effort you put into thinking about how to improve the PSF and represent the parts of the community you participate in. We hope that you will continue to think about these issues, share your ideas, and join a PSF Work Group or PSF initiative if you feel called to do so.
Board Members Elect
Congratulations to our two new and two returning Board members who have been elected!
- Abigail Dogbe
- Jannis Leidel
- Sheena O’Connell
- Simon Willison
We’ll be in touch with all the elected candidates shortly to schedule onboarding. Newly elected PSF Board members are provided orientation for their service and will be joining the upcoming board meeting.
Thank you!
We’d like to take this opportunity to thank our outgoing board members. Kushal Das has been serving on the PSF Board for over ten years– WOW! Kushal has been a part of change after change for the PSF and Python community, serving in PSF Board officer positions, and we are incredibly grateful for his contributions. Dawn Wages quickly became an integral part of the Board during her tenure, stepping up as Treasurer and then Board Chair. Dawn helped guide us through a period of major change– navigating a difficult economy, adapting to the rise of AI, and supporting important shifts in our programs. Thank you, Kushal and Dawn, for your leadership and dedication to the PSF and the Python community. You will be missed and are deeply appreciated!
Our heartfelt thanks go out to each of you who took the time to review the candidates and submit your votes. Your participation helps the PSF represent our community. We received 683 total ballots, easily reaching quorum–1/3 of affirmed voting members (929). We’re especially grateful for your patience with continuing to navigate the changes to the election processes and schedule, which allows for a valid election and a more sustainable election system.
We also want to thank everyone who helped promote this year’s board election, especially Board Members Cristián Maureira-Fredes and Georgi Ker, who took the initiative to cover this year’s election and produced informational videos for our candidates. This promotional effort was inspired by the work of Python Community News in 2023. We also want to highlight the PSF staff members and PSF Board members who put in tons of effort each year as we work to continually improve the PSF elections.
What’s next?
If you’re interested in the complete tally, make sure to check the Python Software Foundation Board of Directors Election 2025 Results page. These results will be available until Nov 11, 2025.
The PSF Election team will conduct a retrospective of this year’s election process to ensure we are improving year over year. We received valuable feedback about the process and tooling. We hope to be able to implement more changes for next year to ensure a smooth and accessible election process for everyone in our community.
Finally, it might feel a little early to mention this, but we will have at least 3 seats open again next year. If you're interested in running or learning more, we encourage you to contact a current PSF Board member or two this year and ask them about their experience serving on the board.
September 16, 2025 01:11 PM UTC
Tryton News
Security Release for issue #14220
Luis Falcon has found that trytond may log sensitive data like passwords when the logging level is set to INFO.
Impact
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: High
- User Interaction: None
- Scope: Unchanged
- Confidentiality: High
- Integrity: None
- Availability: None
Workaround
Increasing the logging level above INFO prevents logging of the sensitive data.
Resolution
All affected users should upgrade trytond to the latest version.
Affected versions per series:
trytond:- 7.6: <= 7.6.6
- 7.4: <= 7.4.16
- 7.0: <= 7.0.35
Non affected versions per series:
trytond:- 7.6: >= 7.6.7
- 7.4: >= 7.4.17
- 7.0: >= 7.0.36
Reference
Concerns?
Any security concerns should be reported on the bug-tracker at https://bugs.tryton.org/ with the confidential checkbox checked.
1 post - 1 participant
September 16, 2025 06:00 AM UTC
September 15, 2025
Jacob Perkins
Python Async Gather in Batches
Python’s asyncio.gather function is great for I/O bound parallel processing. There’s a simple utility function I like to use that I call gather_in_batches:
async def gather_in_batches(tasks, batch_size=100, return_exceptions=False):
for i in range(0, len(tasks), batch_size):
batch = tasks[i:i+batch_size]
for result in await asyncio.gather(*batch, return_exceptions=return_exceptions):
yield resultThe way you use it is
- Generate a list of tasks
- Gather your results
Here’s some simple sample code to demonstrate:
tasks = [process_async(obj) for obj in objects]
return [result async for result in gather_in_batches(tasks)]objects could be all sorts of things:
- records from a database
- urls to scrape
- filenames to read
And process_async is an async function that would just do whatever processing you need to do on that object. Assuming it is mostly I/O bound, then this is very simple and effective method to process data in parallel, without getting into threads, multi-processing, greenlets, or any other method.
You’ll need to experiment to figure out what the optimal batch_size is for your use case. And unless you don’t care about errors, you should set return_exceptions=True, then check if isinstance(result, Exception) to do proper error handling.
September 15, 2025 08:30 PM UTC
PyCoder’s Weekly
Issue #699: Feature Flags, Type Checker Showdown, Null in pandas, and More (Sept. 15, 2025)
#699 – SEPTEMBER 15, 2025
View in Browser »
Feature Flags in Depth
Feature flags are a way to enable or disable blocks of code without needing to re-deploy your software. This post shows you several different approaches to feature flags.
RAPHAEL GASCHIGNARD
A Deep Dive Into Ty, Pyrefly, and Zuban
A comparison of three new Rust-based Python type checkers through the lens of typing spec conformance: Astral’s ty, Meta’s pyrefly, and David Halter’s zuban
ROB HAND
Building and Monitoring AI Agents and MCP Servers [Free Workshop]

Get hands-on with agent monitoring, deep dive into MCP debugging, and use Sentry’s Seer to resolve elusive AI crashes and failures →
SENTRY sponsor
How to Drop Null Values in pandas
Learn how to use .dropna() to drop null values from pandas DataFrames so you can clean missing data and keep your Python analysis accurate.
REAL PYTHON
Quiz: How to Drop Null Values in pandas
Quiz yourself on pandas .dropna(): remove nulls, clean missing data, and prepare DataFrames for accurate analysis.
REAL PYTHON
Articles & Tutorials
Production-Grade Python Logging Made Easier With Loguru
While Python’s standard logging module is powerful, navigating its system of handlers, formatters, and filters can often feel like more work than it should be. This article describes how to achieve the same (and better) results with a fraction of the complexity using Loguru.
AYOOLUWA ISAIAH • Shared by Ayooluwa Isaiah
Simplify IPs, Networks, and Subnets With the ipaddress
Python’s built-in ipaddress module makes handling IP addresses and networks clean and reliable. This article shows how to validate, iterate, and manage addresses and subnets while avoiding common pitfalls of string-based handling.
MOHAMED HAZIANE • Shared by Mohamed Haziane
Boost Agent Resilience with the OpenAI Agents SDK + Temporal Integration

Join our live webinar with OpenAI to see how the Agents SDK and Temporal’s Python integration make AI agents resilient, scalable, and easy to debug. Watch a live multi-agent demo and learn how Durable Execution powers production-ready systems →
TEMPORAL sponsor
Django: Overriding Translations From Dependencies
When building a multi-lingual website in Django, you may end up encountering translated strings in a third party language that don’t match you site’s languages. This post tells you how to deal with that.
GONÇALO VALÉRIO
Creating a Website With Sphinx and Markdown
Sphinx is a Python-based documentation builder and in fact, the Python documentation itself is written using Sphinx. Learn how to build a static site with RST or Markdown and Sphinx.
MIKE DRISCOLL
Python REPL Shortcuts & Features
Discover Python REPL features from keyboard shortcuts to block navigation, this reference guide will help you better utilize Python’s interactive shell.
TREY HUNNER
uv Cheatsheet
A cheatsheet with the most common and useful uv commands to manage projects and dependencies, publish projects, manage tools, and more.
RODRIGO GIRÃO SERRÃO
Python String Splitting
Master Python string splitting with .split() and re.split() to handle whitespace, delimiters & multiline text.
REAL PYTHON course
CodeRabbit: Free AI Code Reviews in CLI
CodeRabbit CLI gives instant code reviews in your terminal. It plugs into any AI coding CLI and catches bugs, security issues, and AI hallucinations before they reach your codebase.
CODERABBIT sponsor
The Most Popular Python Frameworks and Libraries in 2025
Discover the top Python frameworks and libraries based on insights from over 30,000 Python developers.
EVGENIA VERBINA
Benchmarking MicroPython
This post compares the performance of running Python on several microcontroller boards.
MIGUEL GRINBERG
Projects & Code
Hexora: Static Analysis Tool for Malicious Python Scripts
GITHUB.COM/RUSHTER • Shared by Artem Golubin
Async-Native WebTransport Implementation
GITHUB.COM/LEMONSTERFY • Shared by lemonsterfy
Events
Weekly Real Python Office Hours Q&A (Virtual)
September 17, 2025
REALPYTHON.COM
PyData Bristol Meetup
September 18, 2025
MEETUP.COM
PyLadies Dublin
September 18, 2025
PYLADIES.COM
PyCon UK 2025
September 19 to September 23, 2025
PYCONUK.ORG
Chattanooga Python User Group
September 19 to September 20, 2025
MEETUP.COM
PyDelhi User Group Meetup
September 20, 2025
MEETUP.COM
PyCon Ghana 2025
September 25 to September 28, 2025
PYCON.ORG
PyCon JP 2025
September 26 to September 28, 2025
PYCON.JP
Happy Pythoning!
This was PyCoder’s Weekly Issue #699.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
September 15, 2025 07:30 PM UTC
Python Engineering at Microsoft
Python in Visual Studio Code – September 2025 Release
We’re excited to announce the September 2025 release of the Python, Pylance and Jupyter extensions for Visual Studio Code!
This release includes the following announcements:
- Experimental AI-powered hover summaries with Pylance
- Run Code Python Snippet AI tool
- Python Environments extension improvements, including pipenv support
If you’re interested, you can check the full list of improvements in our changelogs for the Python, Jupyter and Pylance extensions.
This month you can also help shape the future of Python typing by filling out the 2025 Python Type System and Tooling Survey: https://jb.gg/d7dqty
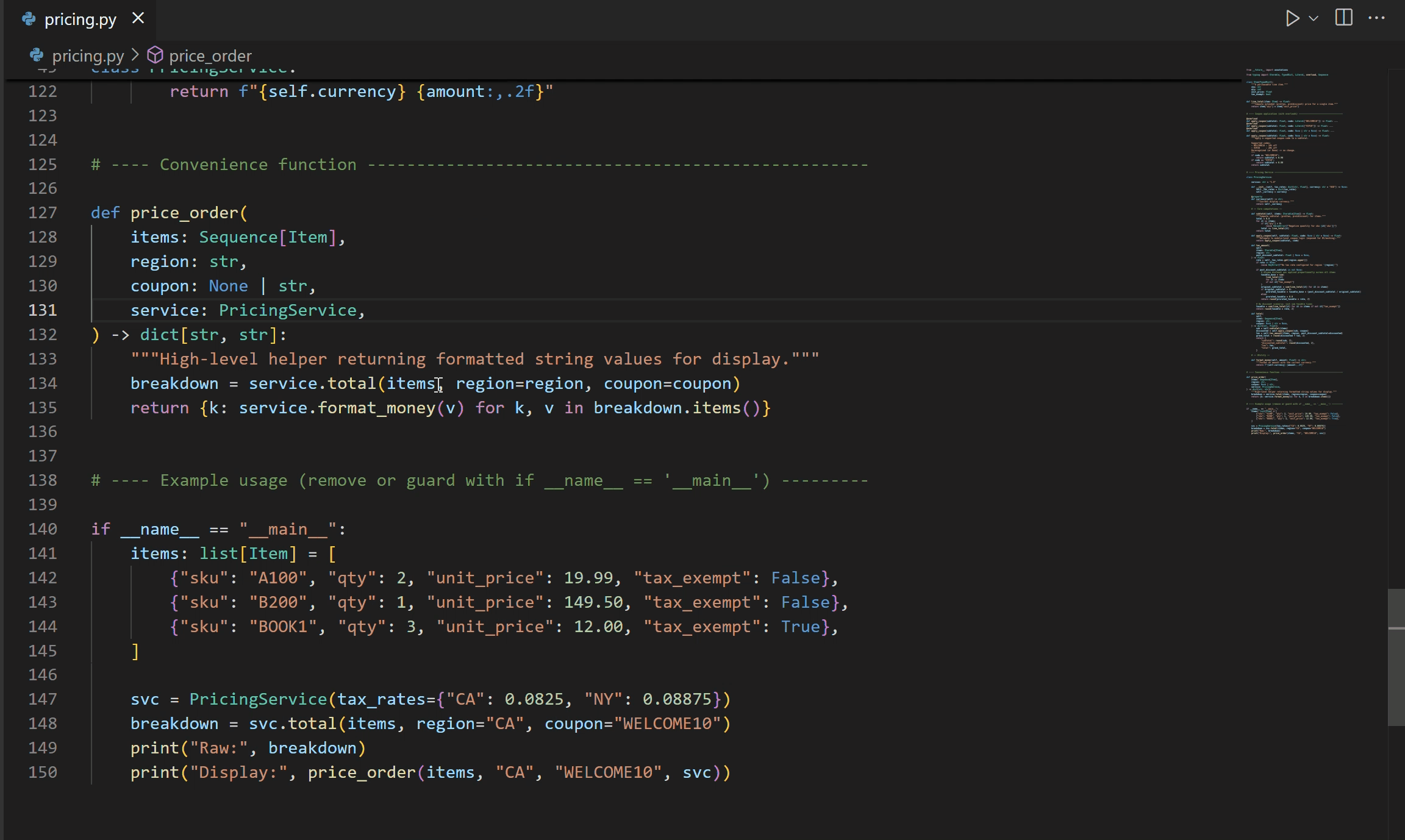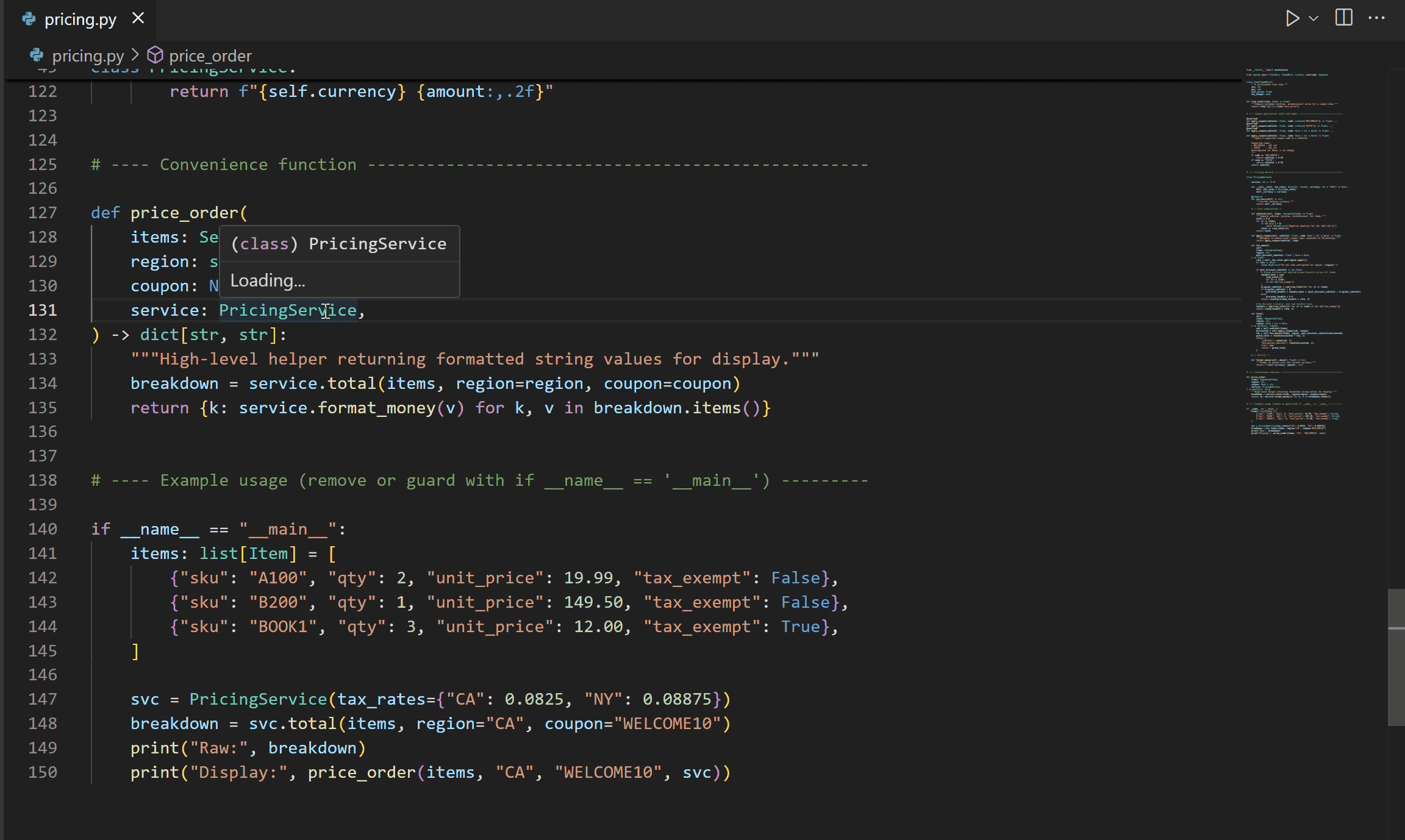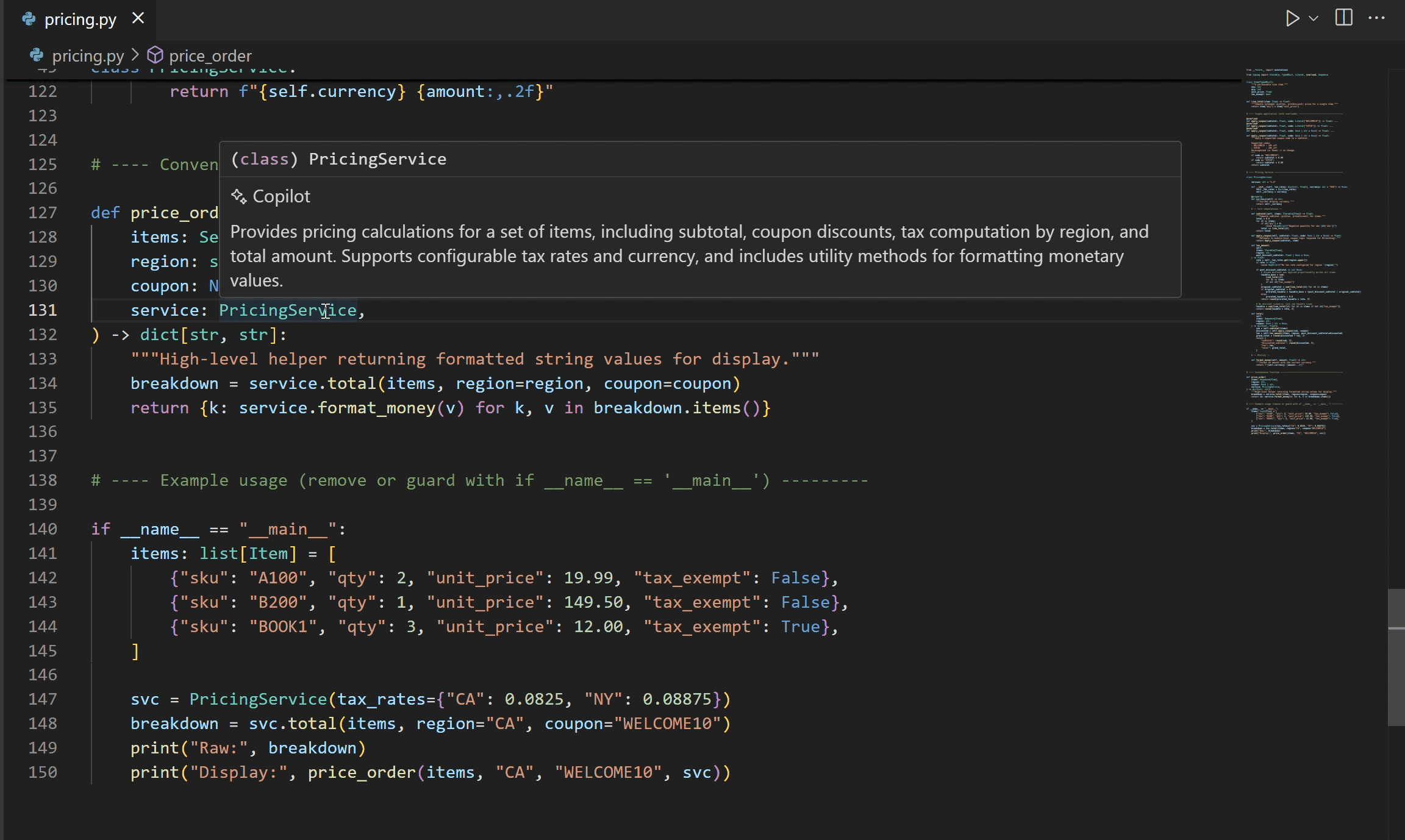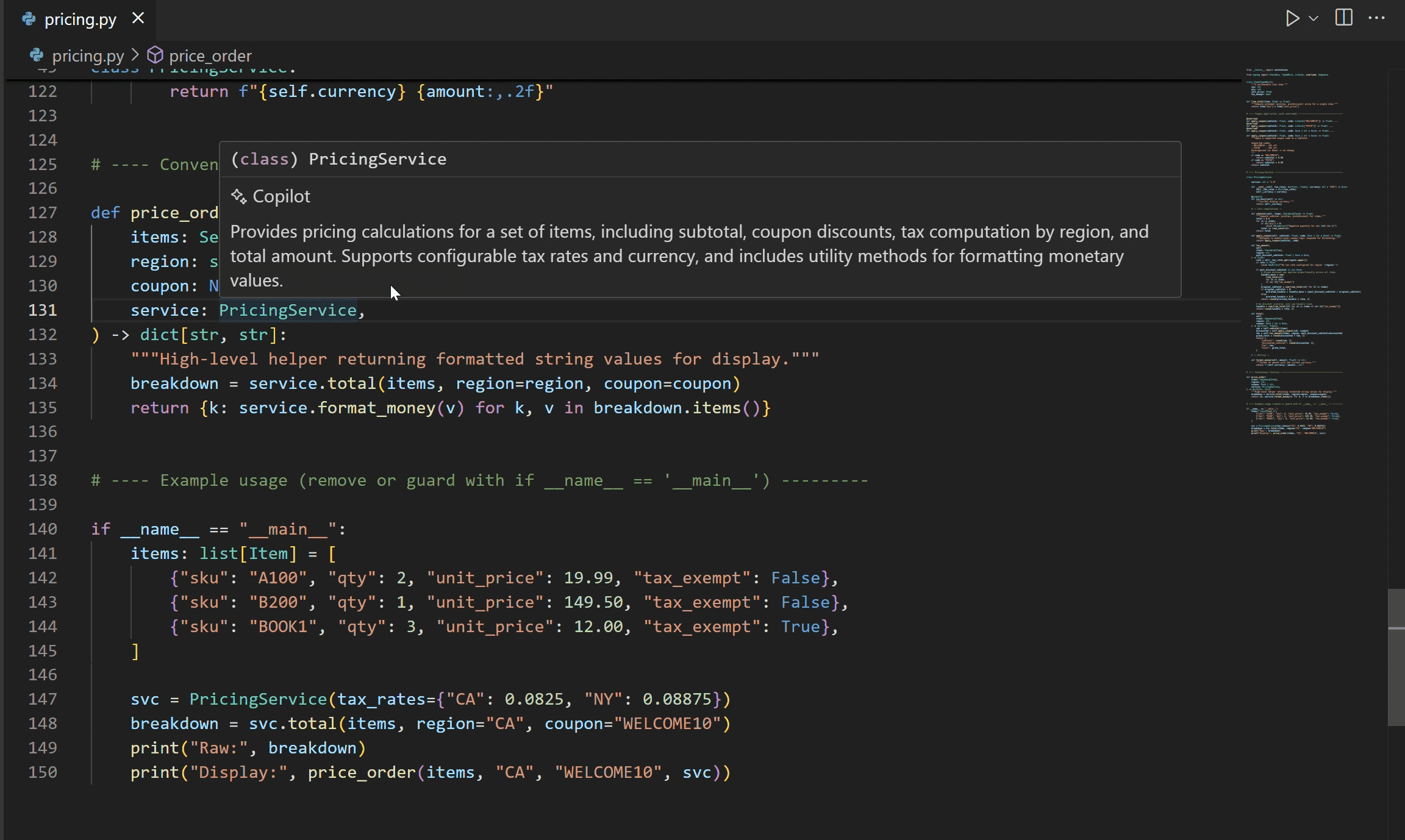
Experimental AI-powered hover summaries with Pylance
A new experimental AI Hover Summaries feature is now available for Python files when using the pre-release version of Pylance with GitHub Copilot. When you enable the setting(python.analysis.aiHoverSummaries) setting, you can get helpful summaries on the fly for symbols that do not already have documentation. This makes it easier to understand unfamiliar code and boosts productivity as you explore Python projects. At the moment, AI Hover Summaries are currently available to GitHub Copilot Pro, Pro+, and Enterprise users.
We look forward to bringing this experimental experience to the stable version soon!
Run Code Snippet AI tool
The Pylance Run Code Snippets tool is a powerful feature designed to streamline your Python experience with GitHub Copilot. Instead of relying on terminal commands like python -c "code" or creating temporary files to be executed, this tool allows GitHub Copilot to execute Python snippets entirely in memory. It automatically uses the correct Python interpreter configured for your workspace, and it eliminates common issues with shell escaping and quoting that sometimes arise during terminal execution.
One of the standout benefits is the clean, well-formatted output it provides, with both stdout and stderr interleaved for clarity. This makes it ideal when using Agent mode with GitHub Copilot to test small blocks of code, run quick scripts, validate Python expressions, or checking imports, all within the context of your workspace.
To try it out, make sure you’re using the latest pre-release version of Pylance. Then, you can select the pylancerunCodeSnippet tool via the Add context… menu in the VS Code Chat panel.
Note: As with all AI-generated code, please make sure to inspect the generated code before allowing this tool to be executed. Reviewing the logic and intent of the code ensures it aligns with your project’s goals and maintains safety and correctness.
Python Environments extension improvements
We appreciate your feedback and are excited to share several enhancements to the Python Environments extension. Thank you to everyone who submitted bug reports and suggestions to help us improve!
Improvements to Conda experience
We focused on removing friction and unexpected behavior when working with Conda environments:
- When creating a new Conda environment through the UI, you can now pick the Python version up front.
- Conda activation and sourcing has been improved across different OS and shell types, with clearer logging.
- The Copy Interpreter Path action now returns the actual Python binary instead of a
conda runwrapper - The proper Conda and Pixi executables are used when debugging.
Pipenv support
Pipenv environments are now discovered and listed in the Environments Manager view.
Better diagnostics and control
We’ve made it easier to identify and resolve environment-related issues. When there are issues with the default environment manager, such as missing executables, clear warnings are now surfaced to guide you through resolution.
Additionally, there’s a new Run Python Environment Tool (PET) in Terminal command which gives you direct access to running the back-end environment tooling by hand. This tool simplifies troubleshooting by allowing you to manually trigger detection operations, making it easier to diagnose and fix edge cases in environment setup.
Quality of life improvements
We also reduced paper cuts to make your experience with the extension smoother. These include:
- Add as Python project menu item is now always available, enabling a more consistent flow for setting a folder as a Python project.
- Interpreter paths with spaces are now properly handled when debugging.
- Environments are now always refreshed on new project creation.
- Conda activation logic is consolidated with clearer logging.
- We audited and removed shell profile edits which are outdated or no longer needed given VS Code core shell integration improvements.
- We tightened the logic that resolves the default interpreter so it honors your defaultInterpreterPath (including script wrappers) without silently “correcting” it.
- We have a new setting called
python.useEnvFilewhich controls whether environment variables from.envfiles and thepython.envFilesetting are injected into terminals when the Python Environments extension is enabled. - venvFolders are now included in the extension’s search path. Please note that we plan to deprecate the
python.venvFolderssetting in favour of a new one in the future, to enable better flexibility when setting up environment search paths.
We are continuing to roll-out the extension. To use it, make sure the extension is installed and add the following to your VS Code settings.json file: "python.useEnvironmentsExtension": true. If you are experiencing issues with the extension, please report issues in our repo, and you can disable the extension by setting "python.useEnvironmentsExtension": false in your settings.json file.
Call for Community Feedback
This month, the Python community is coming together to gather insights on how type annotations are used in Python. Whether you’re a seasoned user or have never used types at all, your input is valuable! Take a few minutes to help shape the future of Python typing by participating in the 2025 Python Type System and Tooling Survey: https://jb.gg/d7dqty.
Other Changes and Enhancements
We have also added small enhancements and fixed issues requested by users that should improve your experience working with Python and Jupyter Notebooks in Visual Studio Code. Some notable changes include:
- The
python.analysis.supportAllPythonDocumentssetting has been removed, making Pylance IntelliSense now enabled in all Python documents by default, including diff views and Python terminals.
We would also like to extend special thanks to this month’s contributors:
- @almarouk Enhanced conda executable retrieval with path existence checks in vscode-python-environments#677
- @osiewicz Fixed prefix of attach shared library for Windows in debugpy#1939
- @sjsikora Stricter pip list Package Parsing in vscode-python-environments#698
- @timrid Check if
os.__file__is available before using it in debugpy#1944
Try out the new improvements by downloading the Python extension and the Jupyter extension from the Marketplace, or install them directly from the extensions view in Visual Studio Code (Ctrl + Shift + X or ⌘ + ⇧ + X). You can learn more about Python support in Visual Studio Code in the documentation. If you run into any problems or have suggestions, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – September 2025 Release appeared first on Microsoft for Python Developers Blog.
September 15, 2025 06:22 PM UTC
Real Python
What Does -> Mean in Python Function Definitions?
In Python, the arrow symbol (->) appears in function definitions as a notation to indicate the expected return type. This notation is optional, but when you include it, you clarify what data type a function should return:
>>> def get_number_of_titles(titles: list[str]) -> int:
... return len(titles)
...
You may have observed that not all Python code includes this particular syntax. What does the arrow notation mean? In this tutorial, you’ll learn what it is, how to use it, and why its usage sometimes seems so inconsistent.
Get Your Code: Click here to download the free sample code that you’ll use to learn what -> means in Python function definitions.
Take the Quiz: Test your knowledge with our interactive “What Does -> Mean in Python Function Definitions?” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
What Does -> Mean in Python Function Definitions?Test your understanding of Python return type hints and learn how to use the -> arrow, annotate containers, and check code with static tools.
In Short: The -> Notation Indicates a Function’s Return Type in Python
In Python, every value stored in a variable has a type. Because Python is dynamically typed, variables themselves don’t have fixed types—they can hold values of any type at different times. This means the same variable might store an integer at one moment and a string the next. In contrast, statically typed languages like C++ or Java require explicit type declarations, and variables are bound to a specific type throughout their lifetime.
You can see an example of a dynamically typed Python variable in the following code example:
>>> my_number = 32
>>> my_number = "32"
You start by declaring a variable called my_number, and setting it to the integer value 32. You then change the variable’s value to the string value "32". When you run this code in a Python environment, you don’t encounter any problems with the value change.
Dynamic typing also means you might not always know what data type a Python function will return, if it returns anything at all. Still, it’s often useful to know the return type. To address this, Python 3.5 introduced optional type hints, which allow developers to specify return types. To add a type hint, you place a -> after a function’s parameter list and write the expected return type before the colon.
You can also add type hints to function parameters. To do this, place a colon after the parameter’s name, followed by the expected type—for example, int or str.
Basic Type Hint Examples
To further explore type hints, suppose that you’re creating a Python application to manage inventory for a video game store. The program stores a list of game titles, tracks how many copies are in stock, and suggests new games for customers to try.
You’ve already seen the type hint syntax in the code example introduced earlier, which returns the number of titles in a list of games that the game store carries:
>>> def get_number_of_titles(titles: list[str]) -> int:
... return len(titles)
...
>>> games = ["Dragon Quest", "Final Fantasy", "Age of Empires"]
>>> print("Number of titles:", get_number_of_titles(games))
Number of titles: 3
Here you see a type hint. You define a function called get_number_of_titles(), which takes a list of game titles as input. Next, you add a type hint for the titles parameter, indicating that the function takes a list of strings. Finally, you also add another type hint for the return type, specifying that the function returns an int value.
The function returns the length of the list, which is an integer. You test this out in the next line, where you create a variable that stores a list of three game titles. When you invoke the function on the list, you verify that the output is 3.
Note that in a real-world application, creating a separate function just to return a list’s length might be redundant. However, for instructional purposes, the function shown in the example is a straightforward way to demonstrate the type hint concept.
You can use type hints with any Python type. You’ve already seen an example with an int return type, but consider another example with a str return type. Suppose you want to recommend a random game for a customer to try. You could do so with the following short example function:
Read the full article at https://realpython.com/what-does-arrow-mean-in-python/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 15, 2025 02:00 PM UTC
Mike Driscoll
Erys – A TUI for Jupyter Notebooks
Have you ever thought to yourself: “Wouldn’t it be nice to run Jupyter Notebooks in my terminal?” Well, you’re in luck. The new Erys project not only makes running Jupyter Notebooks in your terminal a reality, but Erys also lets you create and edit the notebooks in your terminal!
Erys is written using the fantastic Textual package. While Textual handles the front-end in much the same way as your browser would normally do, the jupyter-client handles the backend, which executes your code and manages your kernel.
Let’s spend a few moments learning more about Erys and taking it for a test drive.
Installation
The recommended method of installing Erys is to use the uv package manager. If you have uv installed, you can run the following command in your terminal to install the Erys application:
$ uv tool install erys
Erys also supports using pipx to install it, if you prefer.
Once you have Erys installed, you can run it in your terminal by executing the erys command.
Using Notebooks in Your Terminal
When you run Erys, you will see something like the following in your terminal:

This is an empty Jupyter Notebook. If you would prefer to open an existing notebook, you would run the following command:
erys PATH_TO_NOTEBOOK
If you passed in a valid path to a Notebook, you will see one loaded. Here is an example using my Python Logging talk Notebook:

You can now run the cells, edit the Notebook and more!
Wrapping Up
Erys is a really neat TUI application that gives you the ability to view, create, and edit Jupyter Notebooks and other text files in your terminal. It’s written in Python using the Textual package.
The full source code is on GitHub, so you can check it out and learn how it does all of this or contribute to the application and make it even better.
Check it out and give it a try!
The post Erys – A TUI for Jupyter Notebooks appeared first on Mouse Vs Python.
September 15, 2025 12:35 PM UTC
Real Python
Quiz: Python Project Management With uv
In this quiz, you will review how to use uv, the high-speed Python package and project manager. You will practice key commands, explore the files uv creates for you, and work with project setup tasks.
This is a great way to reinforce project management basics with uv and get comfortable with its streamlined workflows.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 15, 2025 12:00 PM UTC
Quiz: What Does -> Mean in Python Function Definitions?
In this quiz, you will revisit how Python uses the arrow notation (->) in function signatures to provide return type hints. Practice identifying correct syntax, annotating containers, and understanding the role of tools like mypy.
Brush up on key concepts, clarify where and how to use return type hints, and see practical examples in What Does -> Mean in Python Function Definitions?.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
September 15, 2025 12:00 PM UTC
Python Bytes
#449 Suggestive Trove Classifiers
<strong>Topics covered in this episode:</strong><br> <ul> <li><em>* <a href="https://news.itsfoss.com/mozilla-lifeline-is-safe/?featured_on=pythonbytes">Mozilla’s Lifeline is Safe After Judge’s Google Antitrust Ruling</a></em>*</li> <li><em>* <a href="https://github.com/adamghill/troml?featured_on=pythonbytes">troml - suggests or fills in trove classifiers for your projects</a></em>*</li> <li><em>* <a href="https://github.com/manojkarthick/pqrs?featured_on=pythonbytes">pqrs: Command line tool for inspecting Parquet files</a></em>*</li> <li><em>* Testing for Python 3.14</em>*</li> <li><strong>Extras</strong></li> <li><strong>Joke</strong></li> </ul><a href='https://www.youtube.com/watch?v=ZpGE9jkRCvk' style='font-weight: bold;'data-umami-event="Livestream-Past" data-umami-event-episode="449">Watch on YouTube</a><br> <p><strong>About the show</strong></p> <p>Sponsored by us! Support our work through:</p> <ul> <li>Our <a href="https://training.talkpython.fm/?featured_on=pythonbytes"><strong>courses at Talk Python Training</strong></a></li> <li><a href="https://courses.pythontest.com/p/the-complete-pytest-course?featured_on=pythonbytes"><strong>The Complete pytest Course</strong></a></li> <li><a href="https://www.patreon.com/pythonbytes"><strong>Patreon Supporters</strong></a></li> </ul> <p><strong>Connect with the hosts</strong></p> <ul> <li>Michael: <a href="https://fosstodon.org/@mkennedy">@mkennedy@fosstodon.org</a> / <a href="https://bsky.app/profile/mkennedy.codes?featured_on=pythonbytes">@mkennedy.codes</a> (bsky)</li> <li>Brian: <a href="https://fosstodon.org/@brianokken">@brianokken@fosstodon.org</a> / <a href="https://bsky.app/profile/brianokken.bsky.social?featured_on=pythonbytes">@brianokken.bsky.social</a></li> <li>Show: <a href="https://fosstodon.org/@pythonbytes">@pythonbytes@fosstodon.org</a> / <a href="https://bsky.app/profile/pythonbytes.fm">@pythonbytes.fm</a> (bsky)</li> </ul> <p>Join us on YouTube at <a href="https://pythonbytes.fm/stream/live"><strong>pythonbytes.fm/live</strong></a> to be part of the audience. Usually <strong>Monday</strong> at 10am PT. Older video versions available there too.</p> <p>Finally, if you want an artisanal, hand-crafted digest of every week of the show notes in email form? Add your name and email to <a href="https://pythonbytes.fm/friends-of-the-show">our friends of the show list</a>, we'll never share it.</p> <p><strong>Michael #1: <a href="https://news.itsfoss.com/mozilla-lifeline-is-safe/?featured_on=pythonbytes">Mozilla’s Lifeline is Safe After Judge’s Google Antitrust Ruling</a></strong></p> <ul> <li>A judge lets Google <em>keep</em> paying Mozilla to make Google the default search engine but only if those deals aren’t exclusive.</li> <li>More than 85% of Mozilla’s revenue comes from Google search payments.</li> <li>The ruling forbids Google from making exclusive contracts for Search, Chrome, Google Assistant, or Gemini, and forces data sharing and search syndication so rivals get a fighting chance.</li> </ul> <p><strong>Brian #2: <a href="https://github.com/adamghill/troml?featured_on=pythonbytes">troml - suggests or fills in trove classifiers for your projects</a></strong></p> <ul> <li>Adam Hill</li> <li>This is super cool and so welcome.</li> <li>Trove Classifiers are things like <a href="https://pypi.org/search/?c=Programming+Language+%3A%3A+Python+%3A%3A+3.14&featured_on=pythonbytes"><code>Programming Language :: Python :: 3.14</code></a> that allow for some fun stuff to show up in PyPI, like the versions you support, etc.</li> <li>Note that just saying you require 3.9+ doesn’t tell the user that you’ve actually tested stuff on 3.14. I like to keep Trove Classifiers around for this reason.</li> <li>Also, <a href="https://peps.python.org/pep-0639/#deprecate-license-classifiers">License classifier is deprecated</a>, and if you include it, it shows up in two places, in Meta, and in the Classifiers section. Probably good to only have one place. So I’m going to be removing it from classifiers for my projects.</li> <li>One problem, classifier text has to be an exact match to something in the <a href="https://pypi.org/classifiers/?featured_on=pythonbytes">classifier list</a>, so we usually recommend copy/pasting from that list.</li> <li>But no longer! Just use troml!</li> <li>It just fills it in for you (if you run <code>troml suggest --fix</code>). How totally awesome is that!</li> <li>I tried it on <a href="https://pypi.org/project/pytest-check/?featured_on=pythonbytes">pytest-check</a>, and it was mostly right. It suggested me adding 3.15, which I haven’t tested yet, so I’m not ready to add that just yet. :)</li> <li>BTW, <a href="https://pythontest.com/testandcode/episodes/197-python-project-trove-classifiers-do-you-need-this-bit-of-pyproject-toml-metadata/?featured_on=pythonbytes">I talked with Brett Cannon about classifiers back in ‘23</a> if you want some more in depth info on trove classifiers.</li> </ul> <p><strong>Michael #3: <a href="https://github.com/manojkarthick/pqrs?featured_on=pythonbytes">pqrs: Command line tool for inspecting Parquet files</a></strong></p> <ul> <li><code>pqrs</code> is a command line tool for inspecting <a href="https://parquet.apache.org/?featured_on=pythonbytes">Parquet</a> files</li> <li>This is a replacement for the <a href="https://github.com/apache/parquet-mr/tree/master/parquet-tools-deprecated?featured_on=pythonbytes">parquet-tools</a> utility written in Rust</li> <li>Built using the Rust implementation of <a href="https://github.com/apache/arrow-rs/tree/master/parquet?featured_on=pythonbytes">Parquet</a> and <a href="https://github.com/apache/arrow-rs/tree/master/arrow?featured_on=pythonbytes">Arrow</a></li> <li><code>pqrs</code> roughly means "parquet-tools in rust"</li> <li>Why Parquet? <ul> <li>Size <ul> <li>A 200 MB CSV will usually shrink to somewhere between about <strong>20-100 MB</strong> as Parquet depending on the data and compression. Loading a Parquet file is typically <strong>several times faster</strong> than parsing CSV, often <strong>2x-10x faster</strong> for a full-file load and much faster when you only read some columns.</li> </ul></li> <li>Speed <ul> <li><strong>Full-file load into pandas</strong>: Parquet with pyarrow/fastparquet is usually <strong>2x–10x faster</strong> than reading CSV with pandas because CSV parsing is CPU intensive (text tokenizing, dtype inference). <ul> <li>Example: if <code>read_csv</code> is 10 seconds, <code>read_parquet</code> might be ~1–5 seconds depending on CPU and codec.</li> </ul></li> <li><strong>Column subset</strong>: Parquet is <strong>much faster</strong> if you only need some columns — often <strong>5x–50x</strong> faster because it reads only those column chunks.</li> <li><strong>Predicate pushdown & row groups</strong>: When using dataset APIs (pyarrow.dataset) you can push filters to skip row groups, reducing I/O dramatically for selective queries.</li> <li><strong>Memory usage</strong>: Parquet avoids temporary string buffers and repeated parsing, so peak memory and temporary allocations are often lower.</li> </ul></li> </ul></li> </ul> <p><strong>Brian #4: Testing for Python 3.14</strong></p> <ul> <li>Python 3.14 is just around the corner, with a final release scheduled for October.</li> <li><a href="https://docs.python.org/3.14/whatsnew/3.14.html#what-s-new-in-python-3-14">What’s new in Python 3.14</a></li> <li><a href="https://peps.python.org/pep-0745/?featured_on=pythonbytes">Python 3.14 release schedule</a></li> <li>Adding 3.14 to your CI tests in GitHub Actions <ul> <li>Add “3.14” and optionally “3.14t” for freethreaded</li> <li>Add the line <code>allow-prereleases: true</code></li> </ul></li> <li>I got stuck on this, and asked folks on <a href="https://fosstodon.org/@brianokken/115205427424856431">Mastdon</a> and <a href="https://bsky.app/profile/brianokken.bsky.social/post/3lytjr224gs24?featured_on=pythonbytes">Bluesky</a></li> <li>A couple folks suggested the <code>allow-prereleases: true</code> step. Thank you!</li> <li>Ed Rogers also suggested Hugo’s article <a href="https://hugovk.dev/blog/2025/free-threaded-python-on-github-actions/?featured_on=pythonbytes">Free-threaded Python on GitHub Actions</a>, which I had read and forgot about. Thanks Ed! And thanks Hugo!</li> </ul> <p><strong>Extras</strong></p> <p>Brian:</p> <ul> <li><a href="https://github.com/adamghill/dj-toml-settings?featured_on=pythonbytes"><strong>dj-toml-settings</a> :</strong> Load Django settings from a TOML file. - Another cool project from Adam Hill</li> <li><a href="https://github.com/samhenrigold/LidAngleSensor?featured_on=pythonbytes">LidAngleSensor for Mac</a> - from Sam Henri Gold, with examples of <a href="https://hachyderm.io/@samhenrigold/115159295473019599?featured_on=pythonbytes">creaky door</a> and <a href="https://hachyderm.io/@samhenrigold/115159854830332329?featured_on=pythonbytes">theramin</a></li> <li>Listener Bryan Weber found a Python version via Changelog, <a href="https://github.com/tcsenpai/pybooklid?featured_on=pythonbytes">pybooklid</a>, from tcsenpai</li> <li>Grab PyBay</li> </ul> <p>Michael:</p> <ul> <li>Ready prek go! <a href="https://mastodon.social/@hugovk/115175447890438321?featured_on=pythonbytes">by Hugo van Kemenade</a></li> </ul> <p><strong>Joke: <a href="https://x.com/pr0grammerhum0r/status/1964901542395347027?s=12&featured_on=pythonbytes">Console Devs Can’t Find a Date</a></strong></p>
September 15, 2025 08:00 AM UTC
September 14, 2025
Armin Ronacher
What’s a Foreigner?
Across many countries, resistance to immigration is rising — even places with little immigration, like Japan, now see rallies against it. I’m not going to take a side here. I want to examine a simpler question: who do we mean when we say “foreigner”?
I would argue there isn’t a universal answer. Laws differ, but so do social definitions. In Vienna, where I live, immigration is visible: roughly half of primary school children don’t speak German at home. Austria makes citizenship hard to obtain. Many people born here aren’t citizens; at the same time, EU citizens living here have broad rights and labor-market access similar to native Austrians. Over my lifetime, the fear of foreigners has shifted: once aimed at nearby Eastern Europeans, it now falls more on people from outside the EU, often framed through religion or culture. Practically, “foreigner” increasingly ends up meaning “non-EU.” Keep in mind that over the last 30 years the EU went from 12 countries to 27. That’s a signifcant increase in social mobility.
I believe this is quite different from what is happening in the United States. The present-day US debate is more tightly tied to citizenship and allegiance, which is partly why current fights there include attempts to narrow who gets citizenship at birth. The worry is less about which foreigners come and more about the terms of becoming American and whether newcomers will embrace what some define as American values.
Inside the EU, the concept of EU citizenship changes social reality. Free movement, aligned standards, interoperable social systems, and easier labor mobility make EU citizens feel less “foreign” to each other — despite real frictions. The UK before Brexit was a notable exception: less integrated in visible ways and more hostile to Central and Eastern European workers. Perhaps another sign that the level of integration matters. In practical terms, allegiances are also much less clearly defined in the EU. There are people who live their entire live in other EU countries and whos allegiance is no longer clearly aligned to any one country.
Legal immigration itself is widely misunderstood. Most systems are both far more restrictive in some areas and far more permissive than people assume. On the one hand, what’s called “illegal” is often entirely lawful. Many who are considered “illegal” are legally awaiting pending asylum decisions or are accepted refugees. These are processes many think shouldn’t exist, but they are, in fact, legal. On the other hand, the requirements for non-asylum immigration are very high, and most citizens of a country themselves would not qualify for skilled immigration visas. Meanwhile, the notion that a country could simply “remove all foreigners” runs into practical and ethical dead ends. Mobility pressures aren’t going away; they’re reinforced by universities, corporations, individual employers, demographics, and geopolitics.
Citizenship is just a small wrinkle. In Austria, you generally need to pass a modest German exam and renounce your prior citizenship. That creates odd outcomes: native-born non-citizens who speak perfect German but lack a passport, and naturalized citizens who never fully learned the language. Legally clear, socially messy — and not unique to Austria. The high hurdle to obtaining a passport also leads many educated people to intentionally opt out of becoming citizens. The cost that comes with renouncing a passport is not to be underestimated.
Where does this leave us? The realities of international mobility leave our current categories of immigration straining and misaligned with what the population at large thinks immigration should look like. Economic anxiety, war, and political polarization are making some groups of foreigners targets, while the deeper drivers behind immigration will only keep intensifying.
Perhaps we need to admit that we’re all struggling with these questions. The person worried about their community or country changing too quickly and the immigrant seeking a better life are both responding to forces larger than themselves. In a world where capital moves freely but most people cannot, where climate change might soon displace millions, and where birth rates are collapsing in wealthy nations, our immigration systems will be tested and stressed, and our current laws and regulations are likely inadequate.