
Planet Python
Last update: August 15, 2025 04:43 PM UTC
August 15, 2025
Real Python
The Real Python Podcast – Episode #261: Selecting Inheritance or Composition in Python
When considering an object-oriented programming problem, should you prefer inheritance or composition? Why wouldn't it just be simpler to use functions? Christopher Trudeau is back on the show this week, bringing another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Glyph Lefkowitz
The Futzing Fraction
The most optimistic vision of generative AI1 is that it will relieve us of the tedious, repetitive elements of knowledge work so that we can get to work on the really interesting problems that such tedium stands in the way of. Even if you fully believe in this vision, it’s hard to deny that today, some tedium is associated with the process of using generative AI itself.
Generative AI also isn’t free, and so, as responsible consumers, we need to ask: is it worth it? What’s the ROI of genAI, and how can we tell? In this post, I’d like to explore a logical framework for evaluating genAI expenditures, to determine if your organization is getting its money’s worth.
Perpetually Proffering Permuted Prompts
I think most LLM users would agree with me that a typical workflow with an LLM rarely involves prompting it only one time and getting a perfectly useful answer that solves the whole problem.
Generative AI best practices, even from the most optimistic vendors all suggest that you should continuously evaluate everything. ChatGPT, which is really the only genAI product with significantly scaled adoption, still says at the bottom of every interaction:
ChatGPT can make mistakes. Check important info.
If we have to “check important info” on every interaction, it stands to reason that even if we think it’s useful, some of those checks will find an error. Again, if we think it’s useful, presumably the next thing to do is to perturb our prompt somehow, and issue it again, in the hopes that the next invocation will, by dint of either:
- better luck this time with the stochastic aspect of the inference process,
- enhanced application of our skill to engineer a better prompt based on the deficiencies of the current inference, or
- better performance of the model by populating additional context in subsequent chained prompts.
Unfortunately, given the relative lack of reliable methods to re-generate the prompt and receive a better answer2, checking the output and re-prompting the model can feel like just kinda futzing around with it. You try, you get a wrong answer, you try a few more times, eventually you get the right answer that you wanted in the first place. It’s a somewhat unsatisfying process, but if you get the right answer eventually, it does feel like progress, and you didn’t need to use up another human’s time.
In fact, the hottest buzzword of the last hype cycle is “agentic”. While I have my own feelings about this particular word3, its current practical definition is “a generative AI system which automates the process of re-prompting itself, by having a deterministic program evaluate its outputs for correctness”.
A better term for an “agentic” system would be a “self-futzing system”.
However, the ability to automate some level of checking and re-prompting does not mean that you can fully delegate tasks to an agentic tool, either. It is, plainly put, not safe. If you leave the AI on its own, you will get terrible results that will at best make for a funny story45 and at worst might end up causing serious damage67.
Taken together, this all means that for any consequential task that you want to accomplish with genAI, you need an expert human in the loop. The human must be capable of independently doing the job that the genAI system is being asked to accomplish.
When the genAI guesses correctly and produces usable output, some of the human’s time will be saved. When the genAI guesses wrong and produces hallucinatory gibberish or even “correct” output that nevertheless fails to account for some unstated but necessary property such as security or scale, some of the human’s time will be wasted evaluating it and re-trying it.
Income from Investment in Inference
Let’s evaluate an abstract, hypothetical genAI system that can automate some work for our organization. To avoid implicating any specific vendor, let’s call the system “Mallory”.
Is Mallory worth the money? How can we know?
Logically, there are only two outcomes that might result from using Mallory to do our work.
- We prompt Mallory to do some work; we check its work, it is correct, and some time is saved.
- We prompt Mallory to do some work; we check its work, it fails, and we futz around with the result; this time is wasted.
As a logical framework, this makes sense, but ROI is an arithmetical concept, not a logical one. So let’s translate this into some terms.
In order to evaluate Mallory, let’s define the Futzing Fraction, “ FF ”, in terms of the following variables:
- H
-
the average amount of time a Human worker would take to do a task, unaided by Mallory
- I
-
the amount of time that Mallory takes to run one Inference8
- C
-
the amount of time that a human has to spend Checking Mallory’s output for each inference
- P
-
the Probability that Mallory will produce a correct inference for each prompt
- W
-
the average amount of time that it takes for a human to Write one prompt for Mallory
- E
-
since we are normalizing everything to time, rather than money, we do also have to account for the dollar of Mallory as as a product, so we will include the Equivalent amount of human time we could purchase for the marginal cost of one9 inference.
As in last week’s example of simple ROI arithmetic, we will put our costs in the numerator, and our benefits in the denominator.
The idea here is that for each prompt, the minimum amount of time-equivalent cost possible is W+I+C+E. The user must, at least once, write a prompt, wait for inference to run, then check the output; and, of course, pay any costs to Mallory’s vendor.
If the probability of a correct answer is P=13, then they will do this entire process 3 times10, so we put P in the denominator. Finally, we divide everything by H, because we are trying to determine if we are actually saving any time or money, versus just letting our existing human, who has to be driving this process anyway, do the whole thing.
If the Futzing Fraction evaluates to a number greater than 1, as previously discussed, you are a bozo; you’re spending more time futzing with Mallory than getting value out of it.
Figuring out the Fraction is Frustrating
In order to even evaluate the value of the Futzing Fraction though, you have to have a sound method to even get a vague sense of all the terms.
If you are a business leader, a lot of this is relatively easy to measure. You vaguely know what H is, because you know what your payroll costs, and similarly, you can figure out E with some pretty trivial arithmetic based on Mallory’s pricing table. There are endless YouTube channels, spec sheets and benchmarks to give you I. W is probably going to be so small compared to H that it hardly merits consideration11.
But, are you measuring C? If your employees are not checking the outputs of the AI, you’re on a path to catastrophe that no ROI calculation can capture, so it had better be greater than zero.
Are you measuring P? How often does the AI get it right on the first try?
Challenges to Computing Checking Costs
In the fraction defined above, the term C is going to be large. Larger than you think.
Measuring P and C with a high degree of precision is probably going to be very hard; possibly unreasonably so, or too expensive12 to bother with in practice. So you will undoubtedly need to work with estimates and proxy metrics. But you have to be aware that this is a problem domain where your normal method of estimating is going to be extremely vulnerable to inherent cognitive bias, and find ways to measure.
Margins, Money, and Metacognition
First let’s discuss cognitive and metacognitive bias.
My favorite cognitive bias is the availability heuristic and a close second is its cousin salience bias. Humans are empirically predisposed towards noticing and remembering things that are more striking, and to overestimate their frequency.
If you are estimating the variables above based on the vibe that you’re getting from the experience of using an LLM, you may be overestimating its utility.
Consider a slot machine.
If you put a dollar in to a slot machine, and you lose that dollar, this is an unremarkable event. Expected, even. It doesn’t seem interesting. You can repeat this over and over again, a thousand times, and each time it will seem equally unremarkable. If you do it a thousand times, you will probably get gradually more anxious as your sense of your dwindling bank account becomes slowly more salient, but losing one more dollar still seems unremarkable.
If you put a dollar in a slot machine and it gives you a thousand dollars, that will probably seem pretty cool. Interesting. Memorable. You might tell a story about this happening, but you definitely wouldn’t really remember any particular time you lost one dollar.
Luckily, when you arrive at a casino with slot machines, you probably know well enough to set a hard budget in the form of some amount of physical currency you will have available to you. The odds are against you, you’ll probably lose it all, but any responsible gambler will have an immediate, physical representation of their balance in front of them, so when they have lost it all, they can see that their hands are empty, and can try to resist the “just one more pull” temptation, after hitting that limit.
Now, consider Mallory.
If you put ten minutes into writing a prompt, and Mallory gives a completely off-the-rails, useless answer, and you lose ten minutes, well, that’s just what using a computer is like sometimes. Mallory malfunctioned, or hallucinated, but it does that sometimes, everybody knows that. You only wasted ten minutes. It’s fine. Not a big deal. Let’s try it a few more times. Just ten more minutes. It’ll probably work this time.
If you put ten minutes into writing a prompt, and it completes a task that would have otherwise taken you 4 hours, that feels amazing. Like the computer is magic! An absolute endorphin rush.
Very memorable. When it happens, it feels like P=1.
But... did you have a time budget before you started? Did you have a specified N such that “I will give up on Mallory as soon as I have spent N minutes attempting to solve this problem with it”? When the jackpot finally pays out that 4 hours, did you notice that you put 6 hours worth of 10-minute prompt coins into it in?
If you are attempting to use the same sort of heuristic intuition that probably works pretty well for other business leadership decisions, Mallory’s slot-machine chat-prompt user interface is practically designed to subvert those sensibilities. Most business activities do not have nearly such an emotionally variable, intermittent reward schedule. They’re not going to trick you with this sort of cognitive illusion.
Thus far we have been talking about cognitive bias, but there is a metacognitive bias at play too: while Dunning-Kruger, everybody’s favorite metacognitive bias does have some problems with it, the main underlying metacognitive bias is that we tend to believe our own thoughts and perceptions, and it requires active effort to distance ourselves from them, even if we know they might be wrong.
This means you must assume any intuitive estimate of C is going to be biased low; similarly P is going to be biased high. You will forget the time you spent checking, and you will underestimate the number of times you had to re-check.
To avoid this, you will need to decide on a Ulysses pact to provide some inputs to a calculation for these factors that you will not be able to able to fudge if they seem wrong to you.
Problematically Plausible Presentation
Another nasty little cognitive-bias landmine for you to watch out for is the authority bias, for two reasons:
- People will tend to see Mallory as an unbiased, external authority, and thereby see it as more of an authority than a similarly-situated human13.
- Being an LLM, Mallory will be overconfident in its answers14.
The nature of LLM training is also such that commonly co-occurring tokens in the training corpus produce higher likelihood of co-occurring in the output; they’re just going to be closer together in the vector-space of the weights; that’s, like, what training a model is, establishing those relationships.
If you’ve ever used an heuristic to informally evaluate someone’s credibility by listening for industry-specific shibboleths or ways of describing a particular issue, that skill is now useless. Having ingested every industry’s expert literature, commonly-occurring phrases will always be present in Mallory’s output. Mallory will usually sound like an expert, but then make mistakes at random.15.
While you might intuitively estimate C by thinking “well, if I asked a person, how could I check that they were correct, and how long would that take?” that estimate will be extremely optimistic, because the heuristic techniques you would use to quickly evaluate incorrect information from other humans will fail with Mallory. You need to go all the way back to primary sources and actually fully verify the output every time, or you will likely fall into one of these traps.
Mallory Mangling Mentorship
So far, I’ve been describing the effect Mallory will have in the context of an individual attempting to get some work done. If we are considering organization-wide adoption of Mallory, however, we must also consider the impact on team dynamics. There are a number of possible potential side effects that one might consider when looking at, but here I will focus on just one that I have observed.
I have a cohort of friends in the software industry, most of whom are individual contributors. I’m a programmer who likes programming, so are most of my friends, and we are also (sigh), charitably, pretty solidly middle-aged at this point, so we tend to have a lot of experience.
As such, we are often the folks that the team — or, in my case, the community — goes to when less-experienced folks need answers.
On its own, this is actually pretty great. Answering questions from more junior folks is one of the best parts of a software development job. It’s an opportunity to be helpful, mostly just by knowing a thing we already knew. And it’s an opportunity to help someone else improve their own agency by giving them knowledge that they can use in the future.
However, generative AI throws a bit of a wrench into the mix.
Let’s imagine a scenario where we have 2 developers: Alice, a staff engineer who has a good understanding of the system being built, and Bob, a relatively junior engineer who is still onboarding.
The traditional interaction between Alice and Bob, when Bob has a question, goes like this:
- Bob gets confused about something in the system being developed, because Bob’s understanding of the system is incorrect.
- Bob formulates a question based on this confusion.
- Bob asks Alice that question.
- Alice knows the system, so she gives an answer which accurately reflects the state of the system to Bob.
- Bob’s understanding of the system improves, and thus he will have fewer and better-informed questions going forward.
You can imagine how repeating this simple 5-step process will eventually transform Bob into a senior developer, and then he can start answering questions on his own. Making sufficient time for regularly iterating this loop is the heart of any good mentorship process.
Now, though, with Mallory in the mix, the process now has a new decision point, changing it from a linear sequence to a flow chart.
We begin the same way, with steps 1 and 2. Bob’s confused, Bob formulates a question, but then:
- Bob asks Mallory that question.
Here, our path then diverges into a “happy” path, a “meh” path, and a “sad” path.
The “happy” path proceeds like so:
- Mallory happens to formulate a correct answer.
- Bob’s understanding of the system improves, and thus he will have fewer and better-informed questions going forward.
Great. Problem solved. We just saved some of Alice’s time. But as we learned earlier,
Mallory can make mistakes. When that happens, we will need to check important info. So let’s get checking:
- Mallory happens to formulate an incorrect answer.
- Bob investigates this answer.
- Bob realizes that this answer is incorrect because it is inconsistent with some of his prior, correct knowledge of the system, or his investigation.
- Bob asks Alice the same question; GOTO traditional interaction step 4.
On this path, Bob spent a while futzing around with Mallory, to no particular benefit. This wastes some of Bob’s time, but then again, Bob could have ended up on the happy path, so perhaps it was worth the risk; at least Bob wasn’t wasting any of Alice’s much more valuable time in the process.16
Notice that beginning at the start of step 4, we must begin allocating all of Bob’s time to C, so C already starts getting a bit bigger than if it were just Bob checking Mallory’s output specifically on tasks that Bob is doing.
That brings us to the “sad” path.
- Mallory happens to formulate an incorrect answer.
- Bob investigates this answer.
- Bob does not realize that this answer is incorrect because he is unable to recognize any inconsistencies with his existing, incomplete knowledge of the system.
- Bob integrates Mallory’s incorrect information of the system into his mental model.
- Bob proceeds to make a larger and larger mess of his work, based on an incorrect mental model.
- Eventually, Bob asks Alice a new, worse question, based on this incorrect understanding.
- Sadly we cannot return to the happy path at this point, because now Alice must unravel the complex series of confusing misunderstandings that Mallory has unfortunately conveyed to Bob at this point. In the really sad case, Bob actually doesn’t believe Alice for a while, because Mallory seems unbiased17, and Alice has to waste even more time convincing Bob before she can simply explain to him.
Now, we have wasted some of Bob’s time, and some of Alice’s time. Everything from step 5-10 is C, and as soon as Alice gets involved, we are now adding to C at double real-time. If more team members are pulled in to the investigation, you are now multiplying C by the number of investigators, potentially running at triple or quadruple real time.
But That’s Not All
Here I’ve presented a brief selection reasons why C will be both large, and larger than you expect. To review:
- Gambling-style mechanics of the user interface will interfere with your own self-monitoring and developing a good estimate.
- You can’t use human heuristics for quickly spotting bad answers.
- Wrong answers given to junior people who can’t evaluate them will waste more time from your more senior employees.
But this is a small selection of ways that Mallory’s output can cost you money and time. It’s harder to simplistically model second-order effects like this, but there’s also a broad range of possibilities for ways that, rather than simply checking and catching errors, an error slips through and starts doing damage. Or ways in which the output isn’t exactly wrong, but still sub-optimal in ways which can be difficult to notice in the short term.
For example, you might successfully vibe-code your way to launch a series of applications, successfully “checking” the output along the way, but then discover that the resulting code is unmaintainable garbage that prevents future feature delivery, and needs to be re-written18. But this kind of intellectual debt isn’t even specific to technical debt while coding; it can even affect such apparently genAI-amenable fields as LinkedIn content marketing19.
Problems with the Prediction of P
C isn’t the only challenging term though. P, is just as, if not more important, and just as hard to measure.
LLM marketing materials love to phrase their accuracy in terms of a percentage. Accuracy claims for LLMs in general tend to hover around 70%20. But these scores vary per field, and when you aggregate them across multiple topic areas, they start to trend down. This is exactly why “agentic” approaches for more immediately-verifiable LLM outputs (with checks like “did the code work”) got popular in the first place: you need to try more than once.
Independently measured claims about accuracy tend to be quite a bit lower21. The field of AI benchmarks is exploding, but it probably goes without saying that LLM vendors game those benchmarks22, because of course every incentive would encourage them to do that. Regardless of what their arbitrary scoring on some benchmark might say, all that matters to your business is whether it is accurate for the problems you are solving, for the way that you use it. Which is not necessarily going to correspond to any benchmark. You will need to measure it for yourself.
With that goal in mind, our formulation of P must be a somewhat harsher standard than “accuracy”. It’s not merely “was the factual information contained in any generated output accurate”, but, “is the output good enough that some given real knowledge-work task is done and the human does not need to issue another prompt”?
Surprisingly Small Space for Slip-Ups
The problem with reporting these things as percentages at all, however, is that our actual definition for P is 1attempts, where attempts for any given attempt, at least, must be an integer greater than or equal to 1.
Taken in aggregate, if we succeed on the first prompt more often than not, we could end up with a P>12, but combined with the previous observation that you almost always have to prompt it more than once, the practical reality is that P will start at 50% and go down from there.
If we plug in some numbers, trying to be as extremely optimistic as we can, and say that we have a uniform stream of tasks, every one of which can be addressed by Mallory, every one of which:
- we can measure perfectly, with no overhead
- would take a human 45 minutes
- takes Mallory only a single minute to generate a response
- Mallory will require only 1 re-prompt, so “good enough” half the time
- takes a human only 5 minutes to write a prompt for
- takes a human only 5 minutes to check the result of
- has a per-prompt cost of the equivalent of a single second of a human’s time
Thought experiments are a dicey basis for reasoning in the face of disagreements, so I have tried to formulate something here that is absolutely, comically, over-the-top stacked in favor of the AI optimist here.
Would that be a profitable? It sure seems like it, given that we are trading off 45 minutes of human time for 1 minute of Mallory-time and 10 minutes of human time. If we ask Python:
1 2 3 4 5 | |
We get a futzing fraction of about 0.4896. Not bad! Sounds like, at least under these conditions, it would indeed be cost-effective to deploy Mallory. But… realistically, do you reliably get useful, done-with-the-task quality output on the second prompt? Let’s bump up the denominator on P just a little bit there, and see how we fare:
1 2 | |
Oof. Still cost-effective at 0.734, but not quite as good. Where do we cap out, exactly?
1 2 3 4 5 6 7 8 9 | |
With this little test, we can see that at our next iteration we are already at 0.9792, and by 5 tries per prompt, even in this absolute fever-dream of an over-optimistic scenario, with a futzing fraction of 1.2240, Mallory is now a net detriment to our bottom line.
Harm to the Humans
We are treating H as functionally constant so far, an average around some hypothetical Gaussian distribution, but the distribution itself can also change over time.
Formally speaking, an increase to H would be good for our fraction. Maybe it would even be a good thing; it could mean we’re taking on harder and harder tasks due to the superpowers that Mallory has given us.
But an observed increase to H would probably not be good. An increase could also mean your humans are getting worse at solving problems, because using Mallory has atrophied their skills23 and sabotaged learning opportunities2425. It could also go up because your senior, experienced people now hate their jobs26.
For some more vulnerable folks, Mallory might just take a shortcut to all these complex interactions and drive them completely insane27 directly. Employees experiencing an intense psychotic episode are famously less productive than those who are not.
This could all be very bad, if our futzing fraction eventually does head north of 1 and you need to reconsider introducing human-only workflows, without Mallory.
Abridging the Artificial Arithmetic (Alliteratively)
To reiterate, I have proposed this fraction:
which shows us positive ROI when FF is less than 1, and negative ROI when it is more than 1.
This model is heavily simplified. A comprehensive measurement program that tests the efficacy of any technology, let alone one as complex and rapidly changing as LLMs, is more complex than could be captured in a single blog post.
Real-world work might be insufficiently uniform to fit into a closed-form solution like this. Perhaps an iterated simulation with variables based on the range of values seem from your team’s metrics would give better results.
However, in this post, I want to illustrate that if you are going to try to evaluate an LLM-based tool, you need to at least include some representation of each of these terms somewhere. They are all fundamental to the way the technology works, and if you’re not measuring them somehow, then you are flying blind into the genAI storm.
I also hope to show that a lot of existing assumptions about how benefits might be demonstrated, for example with user surveys about general impressions, or by evaluating artificial benchmark scores, are deeply flawed.
Even making what I consider to be wildly, unrealistically optimistic assumptions about these measurements, I hope I’ve shown:
- in the numerator, C might be a lot higher than you expect,
- in the denominator, P might be a lot lower than you expect,
- repeated use of an LLM might make H go up, but despite the fact that it's in the denominator, that will ultimately be quite bad for your business.
Personally, I don’t have all that many concerns about E and I. E is still seeing significant loss-leader pricing, and I might not be coming down as fast as vendors would like us to believe, if the other numbers work out I don’t think they make a huge difference. However, there might still be surprises lurking in there, and if you want to rationally evaluate the effectiveness of a model, you need to be able to measure them and incorporate them as well.
In particular, I really want to stress the importance of the influence of LLMs on your team dynamic, as that can cause massive, hidden increases to C. LLMs present opportunities for junior employees to generate an endless stream of chaff that will simultaneously:
- wreck your performance review process by making them look much more productive than they are,
- increase stress and load on senior employees who need to clean up unforeseen messes created by their LLM output,
- and ruin their own opportunities for career development by skipping over learning opportunities.
If you’ve already deployed LLM tooling without measuring these things and without updating your performance management processes to account for the strange distortions that these tools make possible, your Futzing Fraction may be much, much greater than 1, creating hidden costs and technical debt that your organization will not notice until a lot of damage has already been done.
If you got all the way here, particularly if you’re someone who is enthusiastic about these technologies, thank you for reading. I appreciate your attention and I am hopeful that if we can start paying attention to these details, perhaps we can all stop futzing around so much with this stuff and get back to doing real work.
Acknowledgments
Thank you to my patrons who are supporting my writing on this blog. If you like what you’ve read here and you’d like to read more of it, or you’d like to support my various open-source endeavors, you can support my work as a sponsor!
-
I do not share this optimism, but I want to try very hard in this particular piece to take it as a given that genAI is in fact helpful. ↩
-
If we could have a better prompt on demand via some repeatable and automatable process, surely we would have used a prompt that got the answer we wanted in the first place. ↩
-
The software idea of a “user agent” straightforwardly comes from the legal principle of an agent, which has deep roots in common law, jurisprudence, philosophy, and math. When we think of an agent (some software) acting on behalf of a principal (a human user), this historical baggage imputes some important ethical obligations to the developer of the agent software. genAI vendors have been as eager as any software vendor to dodge responsibility for faithfully representing the user’s interests even as there are some indications that at least some courts are not persuaded by this dodge, at least by the consumers of genAI attempting to pass on the responsibility all the way to end users. Perhaps it goes without saying, but I’ll say it anyway: I don’t like this newer interpretation of “agent”. ↩
-
“Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents”, Axel Backlund, Lukas Petersson, Feb 20, 2025 ↩
-
“random thing are happening, maxed out usage on api keys”, @leojr94 on Twitter, Mar 17, 2025 ↩
-
“New study sheds light on ChatGPT’s alarming interactions with teens” ↩
-
“Lawyers submitted bogus case law created by ChatGPT. A judge fined them $5,000”, by Larry Neumeister for the Associated Press, June 22, 2023 ↩
-
During which a human will be busy-waiting on an answer. ↩
-
Given the fluctuating pricing of these products, and fixed subscription overhead, this will obviously need to be amortized; including all the additional terms to actually convert this from your inputs is left as an exercise for the reader. ↩
-
I feel like I should emphasize explicitly here that everything is an average over repeated interactions. For example, you might observe that a particular LLM has a low probability of outputting acceptable work on the first prompt, but higher probability on subsequent prompts in the same context, such that it usually takes 4 prompts. For the purposes of this extremely simple closed-form model, we’d still consider that a P of 25%, even though a more sophisticated model, or a monte carlo simulation that sets progressive bounds on the probability, might produce more accurate values. ↩
-
No it isn’t, actually, but for the sake of argument let’s grant that it is. ↩
-
It’s worth noting that all this expensive measuring itself must be included in C until you have a solid grounding for all your metrics, but let’s optimistically leave all of that out for the sake of simplicity. ↩
-
“AI Company Poll Finds 45% of Workers Trust the Tech More Than Their Peers”, by Suzanne Blake for Newsweek, Aug 13, 2025 ↩
-
AI Chatbots Remain Overconfident — Even When They’re Wrong by Jason Bittel for the Dietrich College of Humanities and Social Sciences at Carnegie Mellon University, July 22, 2025 ↩
-
AI Mistakes Are Very Different From Human Mistakes by Bruce Schneier and Nathan E. Sanders for IEEE Spectrum, Jan 13, 2025 ↩
-
Foreshadowing is a narrative device in which a storyteller gives an advance hint of an upcoming event later in the story. ↩
-
“People are worried about the misuse of AI, but they trust it more than humans” ↩
-
“Why I stopped using AI (as a Senior Software Engineer)”, theSeniorDev YouTube channel, Jun 17, 2025 ↩
-
“I was an AI evangelist. Now I’m an AI vegan. Here’s why.”, Joe McKay for the greatchatlinkedin YouTube channel, Aug 8, 2025 ↩
-
“Study Finds That 52 Percent Of ChatGPT Answers to Programming Questions are Wrong”, by Sharon Adarlo for Futurism, May 23, 2024 ↩
-
“Off the Mark: The Pitfalls of Metrics Gaming in AI Progress Races”, by Tabrez Syed on BoxCars AI, Dec 14, 2023 ↩
-
“I tried coding with AI, I became lazy and stupid”, by Thomasorus, Aug 8, 2025 ↩
-
“How AI Changes Student Thinking: The Hidden Cognitive Risks” by Timothy Cook for Psychology Today, May 10, 2025 ↩
-
“Increased AI use linked to eroding critical thinking skills” by Justin Jackson for Phys.org, Jan 13, 2025 ↩
-
“AI could end my job — Just not the way I expected” by Manuel Artero Anguita on dev.to, Jan 27, 2025 ↩
-
“The Emerging Problem of “AI Psychosis”” by Gary Drevitch for Psychology Today, July 21, 2025. ↩
Seth Michael Larson
Nintendo Switch Online + Expansion Pack is great for digital and physical GameCube players
Nintendo just announced that the GameCube game “Chibi Robo!” would be coming in exactly one week to Nintendo Switch Online + Expansion Pack (NSO+). Chibi Robo is known for being a hidden gem in the GameCube library, and thus quite expensive to obtain a physical copy. This made me think about what other games Nintendo had announced for NSO+ “GameCube Classics”, and I noticed an interesting trend...
5 of the 7 most expensive first-party GameCube titles are either planned or already available on NSO+. The only other title that hasn't been mentioned yet is “Legend of Zelda: Twilight Princess”. Take a look at the table of all 53 first-party GameCube titles below, green (✅) means the game is already available on NSO+ and blue (🔄) means the game is announced but not yet available:
| NSO+ | Game |
|---|
As much as I am a lover of physical media, the reality is that collecting physical copies of some GameCube titles is prohibitively expensive. I was never going to shell out over $125 to play Chibi Robo. $50 for a year of NSO+ means that I and many others can experience new games in the GameCube library for the first time.
Rare games being made available digitally also tends to reduce the price of physical games. If a game hasn't been released in any format except the original, anyone who wants to play the game legally has to buy a physical copy. If that same game is also available digitally, then the physical game doesn't have nearly as much demand.
We saw this occur just last year with “Paper Mario: The Thousand Year Door” which saw a ~60% price drop after the Switch remake was published, going from $90 in April 2023 to $35 today. This is a boon for collectors and players that are interested in the physical media.
I'll try to keep this table updated as more games are made available and announced. We'll see where the prices of top GameCube titles go from here. If you're interested, here is my script for generating the above table.
Thanks for keeping RSS alive! ♥
August 14, 2025
Python Insider
Python 3.14.0rc2 and 3.13.7 are go!
Not one but two expedited releases! 🎉 🎉
Python 3.14.0rc2
It’s the
final 🪄 penultimate 🪄 3.14 release candidate!
https://www.python.org/downloads/release/python-3140rc2/
Note: rc2 was originally planned for 2025-08-26, but we fixed
a bug that required bumping the magic number stored in Python
bytecode (.pyc) files. This means .pyc
files created for rc1 cannot be used for rc2, and they’ll be
recompiled.
The ABI isn’t changing. Wheels built for rc1 should be fine for rc2, rc3 and 3.14.x. So this shouldn’t affect too many people but let’s get this out for testing sooner.
Due to this early release, we’ll also add a third release candidate between now and the final 3.14.0 release, with no planned change to the final release date.
This release, 3.14.0rc2, is the penultimate release preview. Entering the release candidate phase, only reviewed code changes which are clear bug fixes are allowed between this release candidate and the final release.
The next pre-release of Python 3.14 will be the final release candidate, 3.14.0rc3, scheduled for 2025-09-16; the official release of 3.14.0 is scheduled for Tuesday, 2025-10-07.
There will be no ABI changes from this point forward in the 3.14 series, and the goal is that there will be as few code changes as possible.
Call to action
We strongly encourage maintainers of third-party Python projects to prepare their projects for 3.14 during this phase, and publish Python 3.14 wheels on PyPI to be ready for the final release of 3.14.0, and to help other projects do their own testing. Any binary wheels built against Python 3.14.0 release candidates will work with future versions of Python 3.14. As always, report any issues to the Python bug tracker.
Please keep in mind that this is a preview release and while it’s as close to the final release as we can get it, its use is not recommended for production environments.
Core developers: time to work on documentation now
- Are all your changes properly documented?
- Are they mentioned in What’s New?
- Did you notice other changes you know of to have insufficient documentation?
Major new features of the 3.14 series, compared to 3.13
Some of the major new features and changes in Python 3.14 are:
New features
- PEP 779: Free-threaded Python is officially supported
- PEP 649: The evaluation of annotations is now deferred, improving the semantics of using annotations.
- PEP 750: Template string literals (t-strings) for custom string processing, using the familiar syntax of f-strings.
- PEP 734: Multiple interpreters in the stdlib.
- PEP
784: A new module
compression.zstdproviding support for the Zstandard compression algorithm. - PEP
758:
exceptandexcept*expressions may now omit the brackets. - Syntax highlighting in PyREPL, and support for color in unittest, argparse, json and calendar CLIs.
- PEP 768: A zero-overhead external debugger interface for CPython.
- UUID
versions 6-8 are now supported by the
uuidmodule, and generation of versions 3-5 are up to 40% faster. - PEP
765: Disallow
return/break/continuethat exit afinallyblock. - PEP 741: An improved C API for configuring Python.
- A new type of interpreter. For certain newer compilers, this interpreter provides significantly better performance. Opt-in for now, requires building from source.
- Improved error messages.
- Builtin implementation of HMAC with formally verified code from the HACL* project.
- A new command-line interface to inspect running Python processes using asynchronous tasks.
- The pdb module now supports remote attaching to a running Python process.
(Hey, fellow core developer, if a feature you find important is missing from this list, let Hugo know.)
For more details on the changes to Python 3.14, see What’s new in Python 3.14.
Build changes
Note that Android binaries are new in rc2!
- PEP 761: Python 3.14 and onwards no longer provides PGP signatures for release artifacts. Instead, Sigstore is recommended for verifiers.
- Official macOS and Windows release binaries include an experimentalJIT compiler.
- Official Android binary releases are now available.
Incompatible changes, removals and new deprecations
- Incompatible changes
- Python removals and deprecations
- C API removals and deprecations
- Overview of all pending deprecations
Python install manager
The installer we offer for Windows is being replaced by our new install manager, which can be installed from the Windows Store or from its download page. See our documentation for more information. The JSON file available for download below contains the list of all the installable packages available as part of this release, including file URLs and hashes, but is not required to install the latest release. The traditional installer will remain available throughout the 3.14 and 3.15 releases.
Python 3.13.7
This is the seventh maintenance release of Python 3.13
https://www.python.org/downloads/release/python-3137/
Python 3.13 is the newest major release of the Python programming language, and it contains many new features and optimizations compared to Python 3.12. 3.13.7 is the seventh maintenance release of 3.13.
3.13.7 is an expedited release to fix a significant issue with the 3.13.6 release:
- gh-137583: Regression in ssl module between 3.13.5 and 3.13.6: reading from a TLS-encrypted connection blocks
A few other bug fixes (which would otherwise have waited until the next release) are also included.
More resources
- 3.14 online documentation
- 3.13 online documentation
- PEP 719, 3.14 release schedule
- PEP 745, 3.13 release schedule
- Report bugs at github.com/python/cpython/issues
- Help fund Python and its community
And now for something completely different
The magpie, Pica pica in Latin, is a black and white bird in the crow family, known for its chattering call.
The first-known use in English is from a 1589 poem, where magpie is spelled “magpy” and cuckoo is “cookow”:
Th[e]y fly to wood like breeding hauke,
And leave old neighbours loue,
They pearch themselves in syluane lodge,
And soare in th' aire aboue.
There : magpy teacheth them to chat,
And cookow soone doth hit them pat.
The name comes from Mag, short for Margery or Margaret (compare robin redbreast, jenny wren, and its corvid relative jackdaw); and pie, a magpie or other bird with black and white (or pied) plumage. The sea-pie (1552) is the oystercatcher, the grey pie (1678) and murdering pie (1688) is the great grey shrike. Others birds include the yellow and black pie, red-billed pie, wandering tree-pie, and river pie. The rain-pie, wood-pie and French pie are woodpeckers.
Pie on its own dates to before 1225, and comes from the Latin name for the bird, pica.
Enjoy the new releases
Thanks to all of the many volunteers who help make Python Development and these releases possible! Please consider supporting our efforts by volunteering yourself or through organisation contributions to the Python Software Foundation.
Regards from a busy Helsinki on Night of the Arts,
Your release team,
Hugo van Kemenade
Thomas Wouters
Ned Deily
Steve Dower
Łukasz Langa
Python Software Foundation
Announcing the PSF Board Candidates for 2025!
What an exciting list! Please take a look at who is running for the PSF Board this year on the 2025 Nominees page. This year there are 4 seats open on the PSF Board. You can see who is currently on the board on the PSF Officers & Directors page. (Dawn Wages, Jannis Leidel, Kushal Das, and Simon Willison are at the end of their current terms.)
Board Election Timeline:
- Nominations open: Tuesday, July 29th, 2:00 pm UTC
- Nomination cut-off: Tuesday, August 12th, 2:00 pm UTC
- Announce candidates: Thursday, August 14th
- Voter affirmation cut-off: Tuesday, August 26th, 2:00 pm UTC
- Voting start date: Tuesday, September 2nd, 2:00 pm UTC
- Voting end date: Tuesday, September 16th, 2:00 pm UTC
Not sure what UTC is for you locally? Check this time converter!
Reminder to affirm your intention to vote!
If you wish to vote in this year’s election, you must affirm your intention to vote no later than Tuesday, August 26th, 2:00 pm UTC, to participate in this year’s election. This year’s Board Election vote begins Tuesday, September 2nd, 2:00 pm UTC, and closes on Tuesday, September 16th, 2:00 pm UTC.
Every PSF Voting Member (Supporting, Contributing, and Fellow) needs to affirm their membership to vote in this year’s election. You should have received an email from "psf@psfmember.org <Python Software Foundation>" with the subject "[Action Required] Affirm your PSF Membership voting intention for 2025 PSF Board Election" that contains information on how to affirm your voting status.
Find more information, including step-by-step instructions on voting affirmation, in our ‘Affirm Your PSF Membership Voting Status” blog post. If you run into any issues, please email psf-elections@pyfound.org.
Voting: what to expect
If you are a voting member of the PSF that affirmed your intention to participate in this year’s election, you will receive an email from “OpaVote Voting Link <noreply@opavote.com>” with your ballot, the subject line will read “Python Software Foundation Board of Directors Election 2025” on September 2nd. If you don’t receive a ballot as expected, please first check your spam folder for a message from “noreply@opavote.com”. If you don’t see anything get in touch by emailing psf-elections@pyfound.org so we can look into your account and make sure we have the most up-to-date email for you.
If you have questions about your membership status or the election, please email psf-elections@pyfound.org. You are welcome to join the discussion about the 2025 PSF Board election on the Python Discuss forum.
August 13, 2025
Ari Lamstein
🚀 Join Me Tonight for a Hands-On Streamlit Workshop!
I’m excited to announce that I’ll be running a live workshop tonight on Streamlit—the Python framework that makes it easy to build interactive web apps for data projects.
This session is designed for those with an interest in data apps and no prior experience with Streamlit. You will walk through the fundamentals with a practical, beginner-friendly tutorial. We’ll cover:
 The problem Streamlit solves
The problem Streamlit solves How to structure a basic Streamlit app
How to structure a basic Streamlit app Hands-on exercises for improving a simple app
Hands-on exercises for improving a simple app Deploying your finished app to the internet
Deploying your finished app to the internet
All participants will leave with a finished app deployed to the internet, which you can share with friends.
The workshop is hosted by SF Python and kicks off tonight. You can RSVP and find all the event details here.
To follow along or preview the content, check out the workshop’s GitHub repo. This repo includes the full codebase, setup instructions, and exercises we’ll be working through. Feel free to fork and clone it ahead of time and come with questions!
Looking forward to seeing you there and building something great together.
Django Weblog
Building better APIs: from Django to client libraries with OpenAPI
tl;dr
A summary of resources and learnings related to building REST API I put together over the last couple of years. Complete API development workflow from Django backend to frontend clients using Django REST Framework, drf-spectacular for OpenAPI spec generation, and automated client generation with openapi-generator. Big productivity boost!
There is a lot of discussion about frameworks for building REST APIs, some of them being even able to generate OpenAPI specs directly for you. Django is not quite known for that, but there are ways of doing this by automating most of the process while being very productive and offering your team a clean developer experience.
Overview
The stack I prefer makes use of several additional modules you will require: django-rest-framework and drf-spectacular alongside Django. REST Framework helps you extend your application in order to have a REST API, while drf-spectacular will help you the ability to generate the OpenAPI spec (standalone post: Create OpenAPI spec for Django REST Framework APIs.
After having the OpenAPI spec, you can generate clients with openapi-generator. Here is an example I mapped out of generating an Angular client:
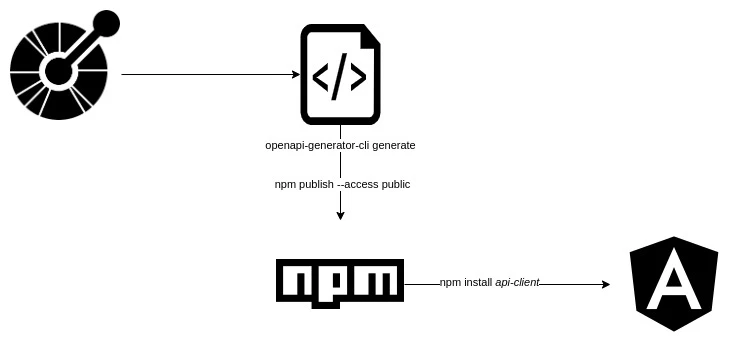
Step-by-step process
There is also a recording from my GLT 2025 talk where I summarize most of these ideas.
 Building Better APIs - From Django to Client Libraries with OpenAPI
Building Better APIs - From Django to Client Libraries with OpenAPI
In case you want to follow along, here is a step-by-step guide from the repository I showed during the presentation:
- Create a Django project
- Add a Django app
- Models and database migrations
- DRF serializers
- DRF views
- Configure URLs
- Add and configure drf spectacular
- Generate OpenAPI
From the last step, you can generate the API clients for the platform you require. You can follow the README and the examples available in my glt25-client repository.
Maintaining compatibility over time
The final tool you can use is openapi-diff, which will help you keep your documentation compatible. This is very important once your REST API is used in production:
Example of a compatible change: glt25-demo v1 to v2
docker run --rm -t openapitools/openapi-diff:latest https://github.com/nezhar/glt25-demo/releases/download/v1/openapi.yaml https://github.com/nezhar/glt25-demo/releases/download/v2/openapi.yaml
Example of a breaking change: glt25-demo v2 to v3
docker run --rm -t openapitools/openapi-diff:latest https://github.com/nezhar/glt25-demo/releases/download/v2/openapi.yaml https://github.com/nezhar/glt25-demo/releases/download/v3/openapi.yaml
Automating the maintenance
The process can be automated even further using GitHub Actions and Dependabot. Here are what the steps look like with this full continuous delivery setup:

Takeways
Building a complete API development workflow from Django to client libraries using OpenAPI creates a powerful and maintainable development experience. By combining Django REST Framework with drf-spectacular for automatic OpenAPI spec generation and openapi-generator for client creation, you can eliminate manual API documentation and reduce integration errors.
If you want to go even further, you can automate the integration of error codes inside the OpenAPI spec. This way you can better support languages that are even more strict when consuming the REST API!
Thank you to Harald Nezbeda for proposing this guest post on the Django blog!
Real Python
Python's with Statement: Manage External Resources Safely
Python’s with statement allows you to manage external resources safely by using objects that support the context manager protocol. These objects automatically handle the setup and cleanup phases of common operations.
By using the with statement alongside appropriate context managers, you can focus on your core logic while the context managers prevent resource leaks like unclosed files, unreleased memory, or dangling network connections.
By the end of this tutorial, you’ll understand that:
- Python’s
withstatement automates the process of setting up and tearing down computational resources using context managers. - Using
withreduces code complexity and prevents resource leaks by ensuring proper resource release, even if exceptions occur. - A context manager in Python is an object that implements
.__enter__()and.__exit__()methods to manage resources safely.
Get ready to learn how Python’s with statement and context managers streamline the setup and teardown phases of resource management so you can write safer, more reliable code.
Get Your Code: Click here to download the free sample code that shows you how to use Python’s with statement to manage external resources safely.
Take the Quiz: Test your knowledge with our interactive “Context Managers and Python's with Statement” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Context Managers and Python's with StatementTest your knowledge of Python's with statement and context managers to write cleaner code and manage resources safely and efficiently.
Managing External Resources in Python
Properly managing external resources, such as files, locks, and network connections, is a common requirement in programming. Sometimes, a program uses a given resource and doesn’t release the associated memory when it no longer needs the resource. This kind of issue is called a memory leak because the available memory shrinks every time you create a new instance of a resource without releasing the unneeded ones.
Managing resources properly is often a tricky task. It requires setup and teardown phases. The latter phase requires you to perform cleanup actions, like closing a file, releasing a lock, or closing a network connection. If you forget to perform these cleanup actions, then your application keeps the resource occupied. This behavior might compromise valuable system resources, such as memory and network bandwidth.
For example, say that a program that uses databases keeps creating new connections without releasing the old ones or reusing them. In that case, the database back end can stop accepting new connections. This might require an administrator to log in and manually terminate those stale connections to make the database usable again.
Another common issue occurs when developers work with files. Writing text to files is usually a buffered operation. This means that calling .write() on a file won’t immediately result in writing text to the physical file, but to a temporary buffer. Sometimes, when the buffer isn’t full, developers forget to call .close() and part of the data can be lost.
Another possibility is that your application runs into errors or exceptions that cause the control flow to bypass the code responsible for releasing the resource at hand. Here’s an example where you use the built-in open() function to write some text to a file:
file = open("hello.txt", "w")
file.write("Hello, World!")
file.close()
This code doesn’t guarantee the file will be closed if an exception occurs during the call to .write(). In this situation, the code might never call .close(), and your program will leak a file descriptor. Failing to release a file descriptor on some operating systems can prevent other programs from accessing the underlying file.
Note: To learn more about closing files, check out the Why Is It Important to Close Files in Python? tutorial.
In Python, you can use a couple of general approaches to deal with resource management. You can wrap your code in:
- A
try…finallyconstruct - A
withconstruct
The first approach is quite generic and allows you to provide setup and teardown code to manage any kind of resource. However, it’s a little bit verbose, and you might forget some cleanup actions if you use this construct in several places.
The second approach provides a straightforward way to provide and reuse setup and teardown code. In this case, you’ll have the limitation that the with statement only works with context managers. In the next two sections, you’ll learn how to use both approaches in your code.
The try … finally Construct
Working with files is probably the most common example of resource management in programming. In Python, you can use a try … finally construct to handle opening and closing files properly:
file = open("hello.txt", "w")
try:
file.write("Hello, World!")
finally:
file.close()
In this example, you open the hello.txt file using open(). To write some text into the file, you wrap the call to .write() in a try statement with a finally clause. This clause guarantees that the file is properly closed by calling .close(), even if an exception occurs during the call to .write() in the try clause. Remember that the finally clause always runs.
When managing external resources in Python, you can use the construct in the previous example to handle setup and teardown logic. The setup logic might include opening the file and writing content to it, while the teardown logic might consist of closing the file to release the acquired resources.
Read the full article at https://realpython.com/python-with-statement/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyCharm
Lightning-Fast Python: Mastering the uv Package Manager
Check out our recent livestream from August 7 on uv, a next-generation Python package manager revolutionizing Python development with speeds 10-100x faster than pip. Released just last year and written in Rust, uv replaces long-standing Python dependency management challenges with a single, lightning-fast tool that just works.
Our speakers:
* Michael Kennedy, host of Talk Python and Python Bytes podcasts, founder of Talk Python Training
* William Vincent, PyCharm Developer Advocate, Django Chat podcast host
Join us as we demonstrate uv‘s game-changing capabilities live, explore practical migration strategies, and discuss advanced features. We’ll show you why Python developers are rapidly adopting this breakthrough tool as their go-to package manager.
Ned Batchelder
Starting with pytest’s parametrize
Writing tests can be difficult and repetitive. Pytest has a feature called parametrize that can make it reduce duplication, but it can be hard to understand if you are new to the testing world. It’s not as complicated as it seems.
Let’s say you have a function called add_nums() that adds up a list of
numbers, and you want to write tests for it. Your tests might look like
this:
def test_123():
assert add_nums([1, 2, 3]) == 6
def test_negatives():
assert add_nums([1, 2, -3]) == 0
def test_empty():
assert add_nums([]) == 0
This is great: you’ve tested some behaviors of your add_nums()
function. But it’s getting tedious to write out more test cases. The names of the
function have to be different from each other, and they don’t mean anything, so
it’s extra work for no benefit. The test functions all have the same structure,
so you’re repeating uninteresting details. You want to add more cases but it
feels like there’s friction that you want to avoid.
If we look at these functions, they are very similar. In any software, when we have functions that are similar in structure, but differ in some details, we can refactor them to be one function with parameters for the differences. We can do the same for our test functions.
Here the functions all have the same structure: call add_nums() and
assert what the return value should be. The differences are the list we pass to
add_nums() and the value we expect it to return. So we can turn those
into two parameters in our refactored function:
def test_add_nums(nums, expected_total):
assert add_nums(nums) == expected_total
Unfortunately, tests aren’t run like regular functions. We write the test
functions, but we don’t call them ourselves. That’s the reason the names of the
test functions don’t matter. The test runner (pytest) finds functions named
test_* and calls them for us. When they have no parameters, pytest can
call them directly. But now that our test function has two parameters, we have
to give pytest instructions about how to call it.
To do that, we use the @pytest.mark.parametrize decorator. Using it
looks like this:
import pytest
@pytest.mark.parametrize(
"nums, expected_total",
[
([1, 2, 3], 6),
([1, 2, -3], 0),
([], 0),
]
)
def test_add_nums(nums, expected_total):
assert add_nums(nums) == expected_total
There’s a lot going on here, so let’s take it step by step.
If you haven’t seen a decorator before, it starts with @ and is like a
prologue to a function definition. It can affect how the function is defined or
provide information about the function.
The parametrize decorator is itself a function call that takes two arguments.
The first is a string (“nums, expected_total”) that names the two arguments to
the test function. Here the decorator is instructing pytest, “when you call
test_add_nums, you will need to provide values for its nums and
expected_total parameters.”
The second argument to parametrize is a list of the values to supply
as the arguments. Each element of the list will become one call to our test
function. In this example, the list has three tuples, so pytest will call our
test function three times. Since we have two parameters to provide, each
element of the list is a tuple of two values.
The first tuple is ([1, 2, 3], 6), so the first time pytest calls
test_add_nums, it will call it as test_add_nums([1, 2, 3], 6). All together,
pytest will call us three times, like this:
test_add_nums([1, 2, 3], 6)
test_add_nums([1, 2, -3], 0)
test_add_nums([], 0)
This will all happen automatically. With our original test functions, when we ran pytest, it showed the results as three passing tests because we had three separate test functions. Now even though we only have one function, it still shows as three passing tests! Each set of values is considered a separate test that can pass or fail independently. This is the main advantage of using parametrize instead of writing three separate assert lines in the body of a simple test function.
What have we gained?
- We don’t have to write three separate functions with different names.
- We don’t have to repeat the same details in each function (
assert,add_nums(),==). - The differences between the tests (the actual data) are written succinctly all in one place.
- Adding another test case is as simple as adding another line of data to the decorator.
Seth Michael Larson
Transferring “UTF8.XYZ”
I'm transferring the UTF8.XYZ domain and service to Trey Hunner, a friend and beloved member of the Python community. Trey and I have talked about making this transfer many times at PyCon US's across the years, and now it's finally happening!
I've taken the opportunity to refresh the service and publish one last revision introducing support for Unicode 17.0.0 and Python 3.13. Big thank you to Trey for taking this on.
Wait... what's UTF8.XYZ?
If this is your first time hearing of the service, that's okay! I created this simple service in 2020 because I wanted to easily grab emojis, em-dashes, and other Unicode characters that I used frequently throughout the day. There aren't any ads, pesky pop-ups, or fluff: only a button to copy the character into your buffer.
You can use curl from the terminal to grab characters easily there, too:
$ curl https://utf8.xyz/waving-hand-sign
👋
Simple, right?
Thanks for keeping RSS alive! ♥
Quansight Labs Blog
Python Wheels: from Tags to Variants
The story of how the Python Wheel Variant design was developed
August 12, 2025
PyCoder’s Weekly
Issue #694: Performance, Classes, t-strings, and More (Aug. 12, 2025)
#694 – AUGUST 12, 2025
View in Browser »

Python Performance Myths and Fairy Tales
This post summarizes a talk by Antonio Cuni who is a long time contributor to PyPy, the alternate Python interpreter. The talk spoke about the challenges and limits of performance in Python and how the flexibility of dynamic languages comes at a cost. See also the associated HN discussion.
JAKE EDGE
You Might Not Need a Python Class
Coming from other languages, you might think a class is the easiest way to do something, but Python has other choices. This post shows you some alternatives and why you might choose them.
ADAM GRANT
Deep Dive: Going Beyond Chatbots with Durable MCP

Join our August 19th webinar to explore long-running, human-in-the-loop MCP servers, sampling with LLMs, and how Python fits into scalable agent workflows with Temporal →
TEMPORAL sponsor
Exploring Python T-Strings
Python 3.14 introduces t-strings: a safer, more flexible alternative to f-strings. Learn how to process templates securely and customize string workflows.
REAL PYTHON course
Articles & Tutorials
Harnessing the Power of Python Polars
What are the advantages of using Polars for your Python data projects? When should you use the lazy or eager APIs, and what are the benefits of each? This week on the show, we speak with Jeroen Janssens and Thijs Nieuwdorp about their new book, Python Polars: The Definitive Guide.
REAL PYTHON podcast
Python Text Matching Beyond Regex
Text similarity is a fundamental challenge in data science. For data that contains duplicates, clustering content, or building search systems, this article explores using 4 different tools to solve this Regex, difflib, RapidFuzz, and Sentence Transformers
KHUYEN TRAN • Shared by Khuyen Tran
Preventing ZIP Parser Confusion Attacks
Python packaging wheels use the ZIP format and it was recently discovered that due to ambiguities in the specification, there could be a vulnerability when unpacking them. To prevent this, PyPI has added extra constraints.
SETH LARSON
Tools to Setup Great Python Projects
A guide to using uv, ruff, reorder-python-imports and pytest to manage packages, formatting, static analysis and testing - all under a centralized configuration that is easy to re-use across CI/CDs, CLIs, IDEs and scripts.
GITHUB.COM/DUARTE-POMPEU • Shared by Duarte Pompeu
Speed Up Your Python Data Science Workflows
This guide shows 7 popular Python libraries (pandas, Polars, scikit-learn, XGBoost, and more) — each accelerated with a simple flag or parameter change. Includes example demos and Colab notebooks.
JAMIL SEMAAN • Shared by Jamil Semaan
How Python Grew From a Language to a Community
This interview with Paul Everitt discusses the upcoming documentary on how Python went from a group of developers collaborating to having its own foundation and user conference.
DAVID CASSEL
Surprising Things With Python’s collections
This tutorial explores ten practical applications of the Python collections module, including use of Counter, namedtuple, defaultdict, and much more.
MATTHEW MAYO
Skip Ahead in Loops With Python’s Continue Keyword
Learn how Python’s continue statement works, when to use it, common mistakes to avoid, and what happens under the hood in CPython byte code.
REAL PYTHON
asyncio: A Library With Too Many Sharp Corners
asyncio has a few gotchas and this post describes five different problems, including: cancellation, disappearing tasks, and more.
SAILOR.LI
What Are Mixin Classes in Python?
Learn how to use Python mixin classes to write modular, reusable, and flexible code with practical examples and design tips.
REAL PYTHON
The Forgetful Calligrapher
Understanding Late Binding in Python Closures
VIVIS DEV • Shared by Vivis Dev
Projects & Code
Events
Weekly Real Python Office Hours Q&A (Virtual)
August 13, 2025
REALPYTHON.COM
PyCon Somalia 2025
August 13 to August 15, 2025
PYCON.ORG.SO
Python Atlanta
August 14 to August 15, 2025
MEETUP.COM
PyCon Korea 2025
August 15 to August 18, 2025
PYCON.KR
Chattanooga Python User Group
August 15 to August 16, 2025
MEETUP.COM
EuroSciPy 2025
August 18 to August 23, 2025
EUROSCIPY.ORG
PyCon Togo 2025
August 23 to August 24, 2025
PYTOGO.ORG
Happy Pythoning!
This was PyCoder’s Weekly Issue #694.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Python Morsels
Checking for string prefixes and suffixes in Python
Python's strings have methods for checking whether a string starts or ends with specific text and for removing prefixes and suffixes.

Table of contents
Slicing works, but there's a better way
We have a couple strings and we'd like to check whether one string is a prefix of another:
>>> filename = "report_housing_2030.pdf"
>>> prefix = "report_"
We could do that by getting the length of the prefix string and then slicing the other string to get the same prefix from it, and then comparing those strings to see whether they're equal:
>>> filename[:len(prefix)] == prefix
True
If we wanted to check whether one string was a suffix of another, we could do the same thing using negative indexes and slicing from the end of the string:
>>> tag = "app:v2.1.0-alpine"
>>> suffix = "-alpine"
>>> tag[-len(suffix):] == suffix
True
This all works, but this code is more awkward that it needs to be.
The startswith and endswith methods
Strings in Python have a …
Read the full article: https://www.pythonmorsels.com/prefixes-and-suffixes/
Real Python
Working With Python's .__dict__ Attribute
Python’s .__dict__ is a special attribute in classes and instances that acts as a namespace, mapping attribute names to their corresponding values. You can use .__dict__ to inspect, modify, add, or delete attributes dynamically, which makes it a versatile tool for metaprogramming and debugging.
In this video course, you’ll learn about using .__dict__ in various contexts, including classes, instances, and functions. You’ll also explore its role in inheritance with practical examples and comparisons to other tools for manipulating attributes.
By the end of this video course, you’ll understand that:
.__dict__holds an object’s writable attributes, allowing for dynamic manipulation and introspection.- Both
vars()and.__dict__let you inspect an object’s attributes. The.__dict__attribute gives you direct access to the object’s namespace, while thevars()function returns the object’s.__dict__. - Common use cases of
.__dict__include dynamic attribute management, introspection, serialization, and debugging in Python applications.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Python Engineering at Microsoft
mssql-python vs pyodbc: Benchmarking SQL Server Performance

Reviewed by Imran Masud and Sumit Sarabhai
When it comes to working with Microsoft SQL Server in Python, pyodbc has long been the de facto driver. It’s mature, trusted and has been serving the community well for years.
But as applications scale and Python becomes more central to modern data workflows — from microservices to data engineering and platforms like Microsoft Fabric — there’s a growing need to modernize and improve the developer experience.
So, can we take this further?
Meet mssql-python – a modern SQL Server driver for Python that rethinks the architecture from the ground up while preserving a familiar experience for developers. It is purpose-built for:
- Security
- Performance
- Memory safety
- Cross-platform support
Calling all Python + SQL developers! We invite the community to try out mssql-python and help us shape the future of high-performance SQL Server connectivity in Python.!
To evaluate how it stacks up against pyodbc, we ran a comprehensive suite of performance benchmarks using the excellent Richbench tool. The results? Let’s just say they speak volumes.
What makes mssql-python different?
Powered by DDBC – Direct Database Connectivity
Most Python SQL Server drivers, including pyodbc, route calls through the Driver Manager, which has slightly different implementations across Windows, macOS, and Linux. This results in inconsistent behavior and capabilities across platforms. Additionally, the Driver Manager must be installed separately, creating friction for both new developers and when deploying applications to servers.
With mssql-python, we made a bold decision. At the heart of the driver is DDBC (Direct Database Connectivity) — a lightweight, high-performance C++ layer that replaces the platform’s Driver Manager.
Key Advantages:
- Provides a consistent, cross-platform backend that handles connections, statements, and memory directly.
- Interfaces directly with the native SQL Server ODBC driver (msodbcsql18).
- Integrates with the same TDS core library that powers the ODBC driver.
Why This Architecture Matters?
By owning the layer that the ODBC driver depends on, DDBC delivers:
- Provides consistency across platforms.
- Lower function call overhead
- Zero external dependencies (pip install mssql-python is all you need)
- Full control over connections, memory and statement handling
This architecture gives mssql-python its core advantages – speed, control and simplicity.
Built with PyBind11 + Modern C++ for Performance and Safety
To expose the DDBC engine to Python, mssql-python uses PyBind11 – a modern C++ binding library, instead of ctypes. Why is that important?
With ctypes, every call between Python and the ODBC driver involved costly type conversions, manual pointer management, and is slow and unsafe.
PyBind11 solves all of this. It provides:
- Native-speed execution with automatic type conversions
- Memory-safe bindings
- Driver API feel clean and Pythonic, while the performance-critical logic remains in robust, maintainable C++.
Benchmark Setup
- Client Machine
- Windows 11 Pro (64-bit)
- Intel Core i7 (12th Gen), 32 GB RAM, NVMe SSD
- Python 3.13.5(64-bit)
- Database
- Azure SQL Database
- General Purpose (Serverless)
- vCores: 1
- Max storage: 32 GB
- Driver Versions
- mssql-python: v0.8.1
- pyodbc: v5.2.0
- Tools
- richbench – 5 runs × 5 samples per operation
- Connection Pooling
- Enabled in both drivers to simulate realistic app conditions
- Benchmark script
- Following is the snippet of the benchmark script used:

Benchmark Script
Benchmark Summary
mssql-python outperforms pyodbc across most operations:
|
Category
|
mssql-python vs. pyodbc |
| Core SQL (SELECT, INSERT, UPDATE, DELETE) | 2× to 4× faster |
| Join, Nested, and Complex Queries | 3.6× to 4× faster |
| Fetch Operations (One & Many) | 3.6 to ~3.7× faster |
| Stored Procedures, Transactions | ~2.1× to ~2.6× faster |
| Batch Inserts |  ~8.6x faster ~8.6x faster |
| 1000 Connections | 16.5x faster |
Across the board, the mssql-python driver demonstrated significantly faster execution times for common SQL operations, especially on:
- Lightweight query handling
- Fast connection reuse
- Low-latency fetches and inserts
These results indicate highly efficient execution paths, minimal overhead, and strong connection reuse capabilities.
Disclaimer on Performance Benchmarks
We welcome feedback and real-world usage insights from the community. If you encounter performance issues or have suggestions, please raise issues on Github, we’re actively listening and committed to improving the experience.
Visual Snapshot
We captured this benchmark data in a clean tabular format using richbench tool. Here’s a quick glance at the relative performance:
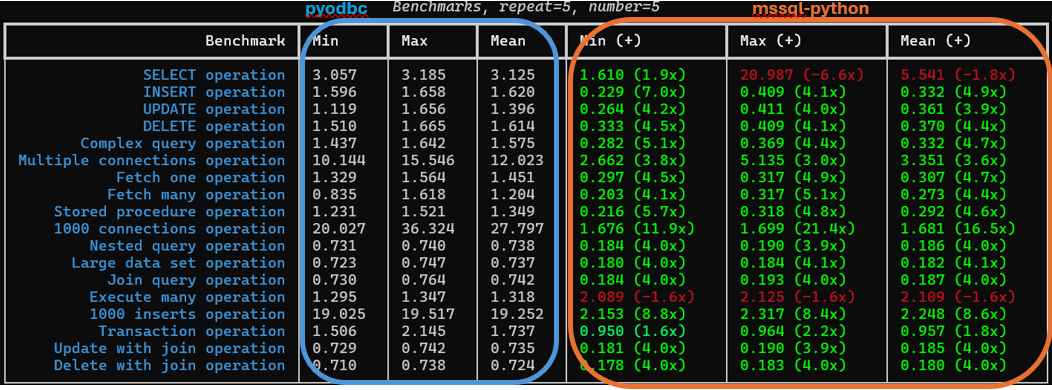
Analysis & Insights
- Low-Latency Wins: SELECT, UPDATE, DELETE saw the largest improvements from 2× to 4× faster.
- Complex Queries: Joins and Nested Queries showed ~4× improvements, due to lower per-call overhead and faster execution cycle.
- Optimized Fetching: fetchone() and fetchmany() showed strong gains due to better buffer handling.
- Connection Scaling: Creating 1000 concurrent connections was 16.5× faster, thanks to optimized pooling and connection caching in DDBC.
- Bulk Insert Gains: Inserts ran 8.6× faster, aided by native buffer reuse and low-level batching.
What’s Next?
We’re actively improving the driver and here’s what’s in the pipeline:
- Seamless Migration Support: We’re working on making the migration experience from pyodbc seamless, with familiar APIs and helpful migration guides.
- Performance benchmarks for Linux and macOS environments.
- Stress-testing under real-world application loads.
- Bulk Copy (BCP) support for ultra-fast ingestion.
- Community engagement for feedback and contributions.
Performance tuning is a key priority, and we’re committed to delivering consistent improvements in upcoming releases.
Join the Journey
If you’re building high-performance apps with SQL Server in Python, mssql-python is a fast, modern and compelling alternative to pyodbc. It is:
- Faster across key operations
- Safe and memory efficient
- Architected for modern Python-C++ interoperability
- Easy to install and integrate
Join the Early Customer Program
Apply here to join the Early Customer Program.
Get early access, influence the roadmap, and work directly with the team!
Try It and Share Your Feedback!
We invite you to:
- Check-out the mssql-python driver and integrate it into your projects.
- Share your thoughts: Open issues, suggest features, and contribute to the project.
- Join the conversation: GitHub Discussions | SQL Server Tech Community.
Use Python Driver with Free Azure SQL Database
 Deploy Azure SQL Database for free
Deploy Azure SQL Database for free
Deploy Azure SQL Managed Instance for free Perfect for testing, development, or learning scenarios without incurring costs.
The post mssql-python vs pyodbc: Benchmarking SQL Server Performance appeared first on Microsoft for Python Developers Blog.
August 11, 2025
Test and Code
237: FastAPI Cloud - Sebastián Ramírez
In this episode, Brian interviews Sebastián Ramírez, creator of FastAPI, about its rapid rise in developer popularity and the launch of FastAPI Cloud. Sebastian explains how FastAPI Cloud addresses deployment challenges small teams face. He shares his transition from open-source to startup founder, focusing on simplifying deployment against the complexity of tools like Kubernetes.
Links:
Help support the show AND learn pytest:
- The Complete pytest course is now a bundle, with each part available separately.
- pytest Primary Power teaches the super powers of pytest that you need to learn to use pytest effectively.
- Using pytest with Projects has lots of "when you need it" sections like debugging failed tests, mocking, testing strategy, and CI
- Then pytest Booster Rockets can help with advanced parametrization and building plugins.
- Whether you need to get started with pytest today, or want to power up your pytest skills, PythonTest has a course for you.
Everyday Superpowers
Get started with event sourcing today
This is the first entry in a five-part series about event sourcing:
I hope this series has inspired you to try event sourcing. In this article, I will give you some suggestions on how to start using it.
The mechanics of event sourcing are not complicated. They’re different, and it takes some getting used to.
When I learned event sourcing, I was told to create my own code to implement the pattern. That has been a great learning experience, but there are so many decisions to factor in that I frequently felt stuck. Instead of following my path, I advise you to see how the pattern works with a framework that someone else wrote, and then feel free to adventure on your own.
I suggest you start by using the `eventsourcing` Python package on a few toy projects. By leveraging it, you can see how the patterns come together. John Bywater and team have done a lot of hard work to make it easy to hit the ground running when you decide to use event sourcing.
To introduce you to the framework, I’ll explore the main components of the package, especially since the package uses terminology that you might not be familiar with.
The main terms you'll need to understand are Event, Aggregate, and Application. Let’s start with the Application.
This is the outer shell of your event sourcing program. It exposes functionality to the outside world. APIs, web apps, or CLIs will call methods on your `Application` to perform tasks or retrieve data.
Applications in the `eventsourcing` package have a repository responsible for saving and retrieving events from the event store.
An incomplete application for a shopping cart could look like this:
from eventsourcing.application import Application
class CartApplication(Application):
def add_item(self, item_id, quantity, price, cart_id=None):
cart = self.repository.get(cart_id) if cart_id else Cart()
cart.add_item(item_id, quantity, price)
self.save(cart)
return cart.idIn domain-driven design terms, I think of the `add_item` method as a command. It represents the intention to change the system by adding an item to a cart. If given a `cart_id`, it’ll create a `Cart` object from the events in the event store. Otherwise it’ll create a new `Cart`. Then it will tell that object to add an item to itself, save the resulting events to the event store, and return the cart id.
I imagine this code looks somewhat similar to the code you’d write in a traditional app.
This is one thing I like about the `eventsourcing` package, it abstracts the mechanics away so your code can focus on the business logic.
But what is this Cart object? Let’s dive into that next.
The `Cart` object in the previous example is an aggregate. Aggregates are analogous to the term “model” in a traditional application, in that models represent some kind of entity that changes over time.
In traditional apps, creating a new `Cart` object would create a new row in a database with the values for that new object. Changing the `Cart` object would result in changing the same row in the database.
In an event-sourced app, creating an aggregate would create an event in the event store that represents the creating of the aggregate with the values for the new object. Changing the `Cart` object would result in adding a new event to the event store with an event representing that change.
This is a different approach, but your code probably won’t look much different.
An aggregate that represents a shopping cart can look like this:
from eventsourcing.domain import event, Aggregate
class Cart(Aggregate):
def __init__(self):
self._items = []
@event("ItemAdded")
def add_item(self, item_id, quantity, price):
self._items.append((item_id, quantity, price))The application object we discussed above would call the `__init__` and `add_item` methods of this aggregate.
This code shows how well the `eventsourcing` package allows you to focus on your business logic. Calling one of these methods would result in creating events. Calling the `__init__` method will create a `Cart.Created` event. Calling the `add_item` method would create a `Cart.ItemAdded` event.
In an event-sourced app, aggregate methods are responsible for changing the system and preventing situations that would clash with the business rules.
So, if the business wanted to prevent people from having more than five items in their cart, we would need to implement that in the `add_item` method. Maybe something like this:
class Cart(Aggregate):
...
@event("ItemAdded")
def add_item(self, item_id, quantity, price):
if len(self._items) >= 5:
raise MaxCartItemsException
self._items.append((item_id, quantity, price))As such, aggregates will hold the majority of your business logic.
Finally, let’s talk about events.
An event represents a change that occurred in the system. Once created, it lives in the event store, usually in a database.
If I were to call the `add_item` method above and call `repr()` on the resulting event it could look like this:
Cart.ItemAdded(
originator_id=UUID('5e2c3aa2-86e6-4729-b751-13adc23d8da4'),
originator_version=2,
timestamp=datetime.datetime(2025, 3, 28, 1, 51, 32, 827273, tzinfo=datetime.timezone.utc),
item_id=324,
quantity=1,
price=3499
)This framework uses the term "originator" in its events to describe what other frameworks would call a model or entity. In this case, `originator_id` is akin to saying `cart_id`.
Events in the same event stream will have the same `originator_id` and a unique `originator_version`.
Another thing I like about the `eventsourcing` framework is that it does the work of defining the events for you from the parameters you provide in the aggregate’s methods. You can still define them yourself as well, to be more explicit, but I like that you have the option not to.
This is enough to give you a quick overview of the package components. From here, I suggest you follow the package’s tutorial.
The tutorial spends most of its time working with in-memory “Plain Old Python Objects.” If you want to see the events in a database, you’ll have to configure the package to do so through environmental variables.
Read more...
Django Weblog
Welcome Our New Fellow - Jacob Tyler Walls
We are pleased to welcome Jacob Tyler Walls as the newest member of the Django Fellowship team. Jacob joins Natalia Bidart and Sarah Boyce, who continue in their roles as Django Fellows.
Jacob is a full-stack developer and open-source maintainer with five years of experience using and contributing to Django. He got involved in open source thanks to music technology. After majoring in music and philosophy at Williams College, Jacob earned a Ph.D. in music composition from the University of Pennsylvania. Programming coursework both fed into his creative output and also led to roles as a Python generalist working on music information retrieval and as a developer for an interactive music theory instruction site using Django.
As a member of Django’s Triage & Review Team, Jacob is passionate about software testing and eager to pay forward the mentorship he received as a contributor. Jacob also co-maintains the Python projects music21 and pylint.
Most recently, as part of his work as a core developer of Arches, an open-source Django/Vue framework for managing cultural heritage data, Jacob had the opportunity to explore the expressive potential of Django’s ORM. He gave a DjangoCon talk on his experience adapting QuerySets to work with highly generic data access patterns and an analogous talk for an audience of Arches developers. Since 2022, he has focused on developing GIS-powered Django apps at Azavea and later Farallon Geographics.
When time permits, Jacob continues to teach music theory, including most recently as an adjunct faculty member at the University of Delaware. (Perhaps another time Django Reinhardt will end up on the syllabus.)
You can find Jacob on GitHub as @jacobtylerwalls and follow occasional musical updates at jacobtylerwalls.com
Thank you to all the applicants to the Fellowship. We hope to expand the program in the future, and knowing there are so many excellent candidates gives us great confidence as we work toward that goal.
Ari Lamstein
New Tutorial: Building Data Apps in Python With Streamlit
I just created a tutorial on building data apps in Python with Streamlit. In many ways, this is the resource I wish I had when I started working with Streamlit two years ago. You can take it for free here!
The tutorial is in a github repo. All the instructions are in the repo’s README file. You can go through the course at your own pace. I expect that most people will finish the course within a few hours.
Demo App
The first milestone in the course is running a demo app that is already in the repo. This app lets you select a state. It then creates a graph that shows how that state’s population has changed over time. The app also displays a dataframe with data on all the states:

Exercises
The core of the tutorial are 4 exercises to improve the app. These exercises cover the most common tasks I do when working with Streamlit:
- Create another graph.
- Create another select box.
- Use the value from the select boxes to determine which graph to show.
- Separate the two visualizations (graph and table) using tabs.
Below is a screenshot of the final app you will create. Note that users can now select which demographic to view. And the table which shows all the data is on a separate tab:

Deployment
Finally, the tutorial walks you through deploying the app to the web. This is also free, and allows your friends and family to see the app you created.
Click here to take the course!
Real Python
Python 3.14 Release Candidate Lands: Faster Code, Smarter Concurrency
Last month, Python 3.14 reached its first release candidate, pushing the interpreter past beta and onto the home stretch toward its final release on October 7. But that headline was only the start—new library releases also landed, Django celebrated its 20th birthday, and EuroPython brought the community together in Prague.
What follows is a quick-read digest of everything that mattered, from core-language breakthroughs to tooling upgrades and community milestones. Feel free to skip straight to whatever interests you most.
Join Now: Click here to join the Real Python Newsletter and you'll never miss another Python tutorial, course, or news update.
Python 3.14 Hits Its First Release Candidate
Last month’s biggest headline is the release of Python 3.14.0rc1, the first candidate for Python 3.14. This marks the penultimate step before the final release, which is scheduled for October 7, 2025.
Core developers are now focused on final documentation updates, while library maintainers are encouraged to test their projects with 3.14 and publish wheels to the Python Package Index (PyPI). Since this is a release candidate, there will be no further ABI changes, meaning that wheels built for this version will work with the final release.
Note: In the context of Python, ABI (Application Binary Interface) refers to the low-level binary compatibility between compiled Python extension modules and the CPython interpreter.
Python 3.14 comes with some exciting new features:
- Free-threaded Python is now officially supported and no longer experimental.
- Deferred evaluation of type annotations improves type hint semantics.
- Template string literals (t-strings) provide new ways to process custom strings.
- Multiple interpreters in the standard library support a human-friendly concurrency model and true multi-core parallelism.
- The new
compression.zstdmodule in the standard library adds support for Zstandard compression.
Topping the feature list is free-threaded Python, a long-awaited improvement that ushers in the free‑threaded era. The officially supported free‑threaded build lifts the long‑standing Global Interpreter Lock (GIL), allowing CPU-bound threads to run truly in parallel on separate cores. As a result, data‑science workloads, web servers, and other concurrency‑heavy apps can scale more cleanly without resorting to multiprocessing.
Existing single‑threaded code keeps working unchanged, but projects that embrace the new model can expect simpler concurrency patterns and better performance.
Other refinements include improved error messages, enhanced debugging tools, and new command-line interface (CLI) features for asyncio introspection.
The release also includes experimental just-in-time (JIT) compilation in the official macOS and Windows binaries, and a new Windows install manager that can be downloaded from the Microsoft Store.
Library and Tooling Highlights
The latest batch of releases brings fresh updates across the Python ecosystem, from cutting-edge data science libraries to faster installers and frameworks. Whether you’re looking for better performance, smarter APIs, or new tools for your workflow, these updates have something for every Pythonista. Here are the key highlights you won’t want to miss.
PyPy 7.3.20 Brings Bug Fixes and Cython Compatibility
Read the full article at https://realpython.com/python-news-august-2025/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Talk Python to Me
#515: Durable Python Execution with Temporal
What if your code was crash-proof? That's the value prop for a framework called Temporal. Temporal is a durable execution platform that enables developers to build scalable applications without sacrificing productivity or reliability. The Temporal server executes units of application logic called Workflows in a resilient manner that automatically handles intermittent failures, and retries failed operations. We have Mason Egger from Temporal on to dive into durable execution.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/ppm'>Posit</a><br> <a href='https://talkpython.fm/pybay'>PyBay</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading">Links from the show</h2> <div><strong>Just Enough Python for Data Scientists Course</strong>: <a href="https://training.talkpython.fm/courses/just-enough-python-for-data-scientists" target="_blank" >talkpython.fm</a><br/> <br/> <strong>Temporal Durable Execution Platform</strong>: <a href="https://temporal.io?featured_on=talkpython" target="_blank" >temporal.io</a><br/> <strong>Temporal Learn Portal</strong>: <a href="https://learn.temporal.io/?featured_on=talkpython" target="_blank" >learn.temporal.io</a><br/> <strong>Temporal GitHub Repository</strong>: <a href="https://github.com/temporalio/temporal?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Temporal Python SDK GitHub Repository</strong>: <a href="https://github.com/temporalio/sdk-python?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>What Is Durable Execution, Temporal Blog</strong>: <a href="https://temporal.io/blog/what-is-durable-execution?featured_on=talkpython" target="_blank" >temporal.io</a><br/> <strong>Mason on Bluesky Profile</strong>: <a href="https://bsky.app/profile/mason.dev?featured_on=talkpython" target="_blank" >bsky.app</a><br/> <strong>Mason on Mastodon Profile</strong>: <a href="https://fosstodon.org/@masonegger" target="_blank" >fosstodon.org</a><br/> <strong>Mason on Twitter Profile</strong>: <a href="https://twitter.com/masonegger?featured_on=talkpython" target="_blank" >twitter.com</a><br/> <strong>Mason on LinkedIn Profile</strong>: <a href="https://www.linkedin.com/in/mason-egger?featured_on=talkpython" target="_blank" >linkedin.com</a><br/> <strong>X Post by @skirano</strong>: <a href="https://x.com/skirano/status/1922651912156897284?featured_on=pythonbytes" target="_blank" >x.com</a><br/> <strong>Temporal Docker Compose GitHub Repository</strong>: <a href="https://github.com/temporalio/docker-compose?featured_on=talkpython" target="_blank" >github.com</a><br/> <strong>Building a distributed asyncio event loop (Chad Retz) - PyTexas 2025</strong>: <a href="https://www.youtube.com/watch?v=wEbUzMYlAAI&ab_channel=PyTexas" target="_blank" >youtube.com</a><br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=xcxQ1f-Oj2M" target="_blank" >youtube.com</a><br/> <strong>Episode #515 deep-dive</strong>: <a href="https://talkpython.fm/episodes/show/515/durable-python-execution-with-temporal#takeaways-anchor" target="_blank" >talkpython.fm/515</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/515/durable-python-execution-with-temporal" target="_blank" >talkpython.fm</a><br/> <strong>Developer Rap Theme Song: Served in a Flask</strong>: <a href="https://talkpython.fm/flasksong" target="_blank" >talkpython.fm/flasksong</a><br/> <br/> <strong>--- Stay in touch with us ---</strong><br/> <strong>Subscribe to Talk Python on YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" >youtube.com</a><br/> <strong>Talk Python on Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm at bsky.app</a><br/> <strong>Talk Python on Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i>talkpython</a><br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes at bsky.app</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
Python Bytes
#444 Begone Python of Yore!
<strong>Topics covered in this episode:</strong><br> <ul> <li><strong><a href="https://nedbatchelder.com/blog/202507/coveragepy_regex_pragmas.html?featured_on=pythonbytes">Coverage.py regex pragmas</a></strong></li> <li><em>* <a href="https://pypi.org/project/yore/?featured_on=pythonbytes">Python of Yore</a></em>*</li> <li><em>* <a href="https://github.com/dantebben/nox-uv?featured_on=pythonbytes">nox-uv</a></em>*</li> <li><em>* A couple Django items</em>*</li> <li><strong>Extras</strong></li> <li><strong>Joke</strong></li> </ul><a href='https://www.youtube.com/watch?v=HCRfjkbSbmE' style='font-weight: bold;'data-umami-event="Livestream-Past" data-umami-event-episode="444">Watch on YouTube</a><br> <p><strong>About the show</strong></p> <p>Sponsored by DigitalOcean: <a href="https://pythonbytes.fm/digitalocean-gen-ai"><strong>pythonbytes.fm/digitalocean-gen-ai</strong></a> Use code <strong>DO4BYTES</strong> and get $200 in free credit</p> <p><strong>Connect with the hosts</strong></p> <ul> <li>Michael: <a href="https://fosstodon.org/@mkennedy">@mkennedy@fosstodon.org</a> / <a href="https://bsky.app/profile/mkennedy.codes?featured_on=pythonbytes">@mkennedy.codes</a> (bsky)</li> <li>Brian: <a href="https://fosstodon.org/@brianokken">@brianokken@fosstodon.org</a> / <a href="https://bsky.app/profile/brianokken.bsky.social?featured_on=pythonbytes">@brianokken.bsky.social</a></li> <li>Show: <a href="https://fosstodon.org/@pythonbytes">@pythonbytes@fosstodon.org</a> / <a href="https://bsky.app/profile/pythonbytes.fm">@pythonbytes.fm</a> (bsky)</li> </ul> <p>Join us on YouTube at <a href="https://pythonbytes.fm/stream/live"><strong>pythonbytes.fm/live</strong></a> to be part of the audience. Usually <strong>Monday</strong> at 10am PT. Older video versions available there too.</p> <p>Finally, if you want an artisanal, hand-crafted digest of every week of the show notes in email form? Add your name and email to <a href="https://pythonbytes.fm/friends-of-the-show">our friends of the show list</a>, we'll never share it.</p> <p><strong>Brian #1:</strong> <a href="https://nedbatchelder.com/blog/202507/coveragepy_regex_pragmas.html?featured_on=pythonbytes">Coverage.py regex pragmas</a></p> <ul> <li><p>Ned Batchelder</p></li> <li><p>The regex implementation of how <a href="http://coverage.py?featured_on=pythonbytes">coverage.py</a> recognizes pragmas is pretty amazing.</p></li> <li><p>It’s extensible through plugins</p> <ul> <li><a href="https://pypi.org/project/covdefaults/?featured_on=pythonbytes">covdefaults</a> adds a bunch of default exclusions, and also platform- and version-specific comment syntaxes.</li> <li><a href="https://pypi.org/project/coverage-conditional-plugin/?featured_on=pythonbytes">coverage-conditional-plugin</a> gives you a way to create comment syntaxes for entire files, for whether other packages are installed, and so on.</li> </ul></li> <li><p>A change from last year (as part of coverage.py 7.6 allows multiline regexes, which let’s us do things like:</p> <ul> <li>Exclude an entire file with <code>\\A(?s:.*# pragma: exclude file.*)\\Z</code></li> <li>Allow start and stop delimiters with <code># no cover: start(?s:.*?)# no cover: stop</code></li> <li>Exclude empty placeholder methods with <code>^\\s*(((async )?def .*?)?\\)(\\s*->.*?)?:\\s*)?\\.\\.\\.\\s*(#|$)</code></li> <li>See Ned’s article for explanations of these</li> </ul></li> </ul> <p><strong>Michael #2: <a href="https://pypi.org/project/yore/?featured_on=pythonbytes">Python of Yore</a></strong></p> <ul> <li>via Matthias</li> <li>Use <code>YORE: ...</code> comments to highlight CPython version dependencies. <div class="codehilite"> <pre><span></span><code><span class="c1"># YORE: EOL 3.8: Replace block with line 4.</span> <span class="k">if</span> <span class="n">sys</span><span class="o">.</span><span class="n">version_info</span> <span class="o"><</span> <span class="p">(</span><span class="mi">3</span><span class="p">,</span> <span class="mi">9</span><span class="p">):</span> <span class="kn">from</span><span class="w"> </span><span class="nn">astunparse</span><span class="w"> </span><span class="kn">import</span> <span class="n">unparse</span> <span class="k">else</span><span class="p">:</span> <span class="kn">from</span><span class="w"> </span><span class="nn">ast</span><span class="w"> </span><span class="kn">import</span> <span class="n">unparse</span> </code></pre> </div></li> </ul> <p>Then check when they go out of support:</p> <div class="codehilite"> <pre><span></span><code>$<span class="w"> </span>yore<span class="w"> </span>check<span class="w"> </span>--eol-within<span class="w"> </span><span class="s1">'5 months'</span> ./src/griffe/agents/nodes/_values.py:11:<span class="w"> </span>Python<span class="w"> </span><span class="m">3</span>.8<span class="w"> </span>will<span class="w"> </span>reach<span class="w"> </span>its<span class="w"> </span>End<span class="w"> </span>of<span class="w"> </span>Life<span class="w"> </span>within<span class="w"> </span>approx.<span class="w"> </span><span class="m">4</span><span class="w"> </span>months </code></pre> </div> <p>Even fix them with <code>fix</code> .</p> <p><strong>Michael #3: <a href="https://github.com/dantebben/nox-uv?featured_on=pythonbytes">nox-uv</a></strong></p> <ul> <li>via John Hagen</li> <li>What nox-uv does is make it very simple to install uv extras and/or dependency groups into a nox session's virtual environment.</li> <li>The versions installed are constrained by uv's lockfile meaning that everything is deterministic and pinned.</li> <li>Dependency groups make it very easy to install only want is necessary for a session (e.g., only linting dependencies like Ruff, or main dependencies + mypy for type checking).</li> </ul> <p><strong>Brian #4: A couple Django items</strong></p> <ul> <li><strong>Stop Using Django's squashmigrations: There's a Better Way</strong> <ul> <li>Johnny Metz</li> <li>Resetting migrations is sometimes the right thing.</li> <li>Overly simplified summary: delete migrations and start over</li> </ul></li> <li><strong>dj-lite</strong> <ul> <li>Adam Hill</li> <li>Use SQLite in production with Django</li> <li>“Simplify deploying and maintaining production Django websites by using SQLite in production. <code>dj-lite</code> helps enable the best performance for SQLite for small to medium-sized projects. It requires Django 5.1+.”</li> </ul></li> </ul> <p><strong>Extras</strong></p> <p>Brian:</p> <ul> <li><a href="https://testandcode.com/237?featured_on=pythonbytes">Test & Code 237 with Sebastian Ramirez on FastAPI Cloud</a></li> <li><a href="https://pythontest.com/pytest-fixtures-nuts-bolts-revisited/?featured_on=pythonbytes">pythontest.com: pytest fixtures nuts and bolts - revisited</a></li> </ul> <p>Michael:</p> <ul> <li>New course: <a href="https://training.talkpython.fm/courses/just-enough-python-for-data-scientists?featured_on=pythonbytes"><strong>Just Enough Python for Data Scientists</strong></a></li> <li><a href="https://www.youtube.com/watch?v=Uh8CMtaWPpc">My live stream about uv</a> is now on YouTube</li> <li><a href="https://cursor.com/en/cli?featured_on=pythonbytes">Cursor CLI</a>: Built to help you ship, right from your terminal.</li> </ul> <p><strong>Joke: <a href="https://www.reddit.com/r/programminghumor/s/90oFJlauGv?featured_on=pythonbytes">Copy/Paste</a></strong></p>
August 10, 2025
Go Deh
Go Deh celebrations!


This year it's:
- Fifty years since I first learned to program!
- Thirty years of programming Python!
- And In July, this blog topped one million views since its inception!
I first learned to program by crashing an after-school class I saw the private school geeks disappearing to from Central library in Nottingham. One of the Trent Polytechnic lecturers I now see sometimes on Computerphile - he mentioned how the council payed something towards the cost of the computer on the understanding that they have a class for students, but somehow only the guys from the fee paying Nottingham High School for Boys seemed to get the memo, hmm.
That was s long ago, Paper tape and teletypes.
Forward to 1995: A new job, amongst engineers where the few of them that could program, programmed in Perl. Perl was big within the chip design industry back then, but Aargh! I thought Perl was awful - for me it did not gel! I went looking for an alternative and found this little known language called Python.
The community on comp.lang.python seemed so nice, they valued readability and "One obvious way to do it" over Perls more than one way. I was hooked, and did my little bit of evangelizing. (OK, I was known as that Python guy - but they couldn't fault the code).
Was it eleven years ago that I started the blog? It has been one of two main places where I have shown my work - the other is on site rosettacode.org which, no doubt, has been scraped to death for AI's - it is one of the few places online showing different programming languages solving the same task. I wrote 199 of those RosettaCode tasks over the years, and many more of the examples solving those tasks; (mainly Python and Awk language examples). Most, if not all of those task descriptions were my own work - not copied off other sites - if there are similarities in text then they probably copied from me or the task is so simple that there is going to be convergence).
Lately, as you can tell from the pictures above, I have been dabbling in AI. AI is the future, but who knows how AI will affect that future? I am a programmer who can describe coding tasks to other people for them to complete the task. AI is an ever changing field, I think that I am learning to use it better, as it gets better too - I am both more and less precise in my prompting and finding out what the AI remembers and does best. I experiment with the amount of description in the code to cut and paste into new sessions to cut the mistakes and continue from a clean base. I experiment with coding from pseudo-code. I have found that some abilities are universal: when exploring the use of SQL - which I am a hunt-n-peck coder in, I can still spot redundancies "You recompute the first query as part of the second and the second as part of the third, can't you reuse prior results", lead to the AI introducing common table expressions I think it was, and telling me all about them.
I'm still scripting 😊
August 09, 2025
Peter Bengtsson
Combining Django signals with in-memory LRU cache
It's easy to combine functools.lru_cache with Django signals to get a good memoization pattern on Django ORM queries.